
SQL Server 2008 R2向前端工具开放了数据挖掘能力,通过集成在Excel中的插件,允许用户连接到SQL Server服务器,直接操作多种数据挖掘算法,解决日常应用中的小型预测问题;使用过程中,用户几乎感觉不到SQL Server服务器的存在,也不必受复杂逻辑实现的困扰,一切皆由数据说了算。
在本文实例中,使用SQL Server 2008 R2实例数据库AdventureWorks结合SQL Server 2008数据挖掘外接程序,即使您不会SQL Server,不懂SQL语句,也没有任何关系,只要您会使用Excel就可以获取到想要的数据,并且对简单的点击几个按钮就可以对数据进行挖掘。如果您有一定的数据库基础,那么结合Reporting Service,可以生成预测数据和结果。
步骤一:数据挖掘外接程序
在步骤1中我们首先安装Microsoft SQL Server 2008 Office 2007 数据挖掘外接程序,其下载地址如下:
http://www.microsoft.com/downloads/details.aspx?FamilyId=896A493A-2502-4795-94AE-E00632BA6DE7&displaylang=zh-cn
通过使用 Microsoft SQL Server 2008 Office 2007 数据挖掘外接程序(数据挖掘外接程序),可以在 Office Excel 2007 和 Office Visio 2007 中利用 SQL Server 2008 的预测分析功能。数据挖掘外接程序包括以下组件:
Excel 表分析工具:此外接程序提供了一些非常易于使用的任务,这些任务可利用 SQL Server 2008 数据挖掘对电子表格数据进行更强大的分析,而不需要您了解任何数据挖掘概念。
Excel 数据挖掘客户端:通过使用此外接程序,您可以使用电子表格数据,或使用可通过 SQL Server 2008 Analysis Services 实例访问的外部数据,在 Excel 2007 内创建、测试、浏览和管理数据挖掘模型。
Visio 数据挖掘模板:利用此外接程序,您可以用可加注的 Visio 2007 绘图形式呈现和共享挖掘模型。
在本文的实例中,我们重点讨论的是使用Excel来进行数据挖掘,Visio 数据挖掘模板这里不做过多介绍。
下载数据挖掘外接程序后,在安装的过程中,根据需要选择要安装的功能,为了了解和使用所有功能,我们把默认不安装的Excel数据挖掘客户端和Visio数据挖掘模板页安装上,其界面如图1所示:
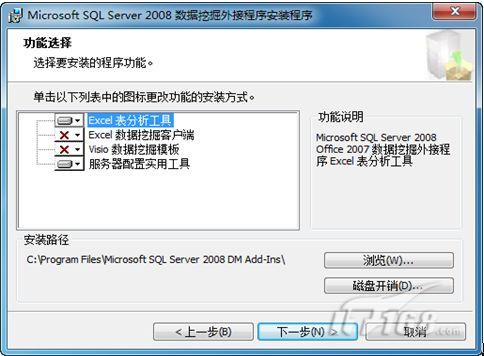
图1 数据挖掘外接程序功能选择
安装完成后,需要连接到SSAS数据库,连接到SSAS数据时,我们选择第二项,使用自己管理的现有Microsoft SQL Server 2008 Analysis Service实例,通过这个实例的选取,实际上选取了我们在数据里安装的AdventureWorks 数据分析实例。
连接成功后,点击“下一步”,运行服务器配置实用工具,这是开始使用Office 2007数据挖掘外接程序最后一个配置步骤,其界面如图2所示:
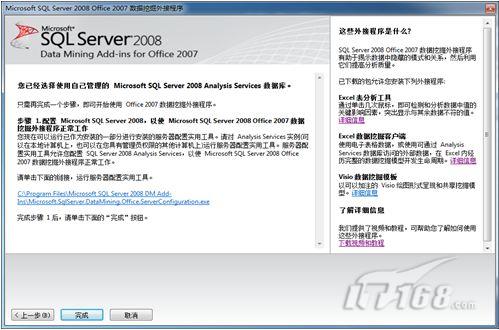
图2 配置SQL Server
点击图2中所示的链接后,数据挖掘外接程序配置向导页面,如图3所示:
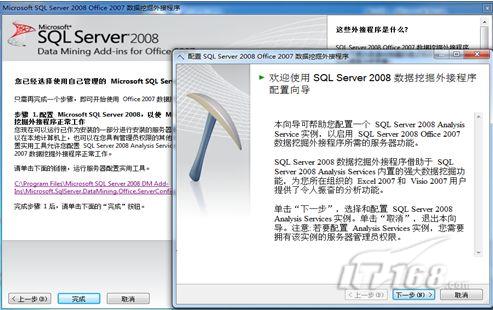
图3 数据挖掘配置向导
配置向导共分4步:第一步填写服务器名称和身份验证方式以连接到Analysis Service数据库;第二步:设置是否允许创建临时挖掘模型;第三步:为外接程序用户创建数据库;第四步:将相应权限授予相应用户。配置成功后,其界面如图4所示:
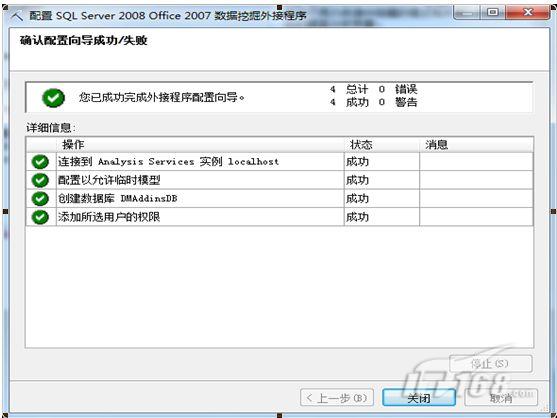
图4 数据挖掘外接程序配置成功
关闭接程序配置向导,打开已经生成好的实例Excel文件:DMAddins_SampleData.xlsx,如图5所示:
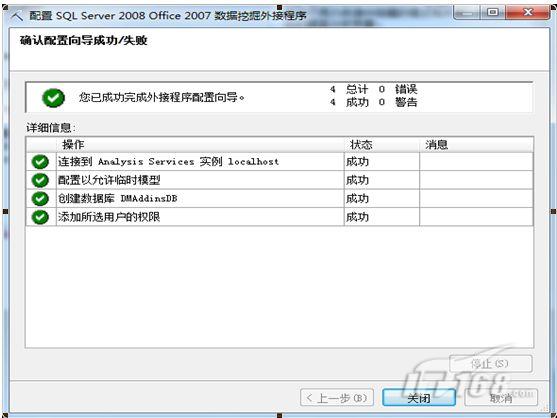
图5 数据挖掘外接程序实例数据
在进行数据挖掘前,需要连接到数据分析服务,如图6所示:

图6 连接到数据分析服务
至此,在进行数据挖掘前的所有准备工作已经完成。
步骤二:在Excel中完成数据挖掘全过程
在步骤二中,我们将使用步骤一的Excel文件进行数据挖掘和数据分析。下面就开始介绍数据挖掘,打开文件DMAddins_SampleData.xlsx(默认位置在X86:C:Program Files Microsoft SQL Server 2008 DM Add-Ins,X64:C:Program Files (x86)Microsoft SQL Server 2008 DM Add-Ins),我们可以看到能够使用的数据挖掘工具如图7所示:

图7 数据挖掘工具
这些数据挖掘工具包括:数据准备、数据建模、准确性和验证、模型用法、模型管理、连接。在下面的案例中,我们使用数据建模工具预测来做演示:
操作步骤如下:
(1)在图5中选择“预测”,自动打开“Forecasting” Sheet
(2)在预测Sheet中,点击数据挖掘页,并点击“预测”按钮,如图7所示
(3)点击“预测”按钮后,自动弹出预测数据挖掘向导,选择数据表和数据区域,在这里数据表我们选择了“Table5”,数据区域选择了所有区域。按照向导对输入内容进行设置、结构名称和描述、模块名称和描述,点击“完成”即可,其结果如图8所示:
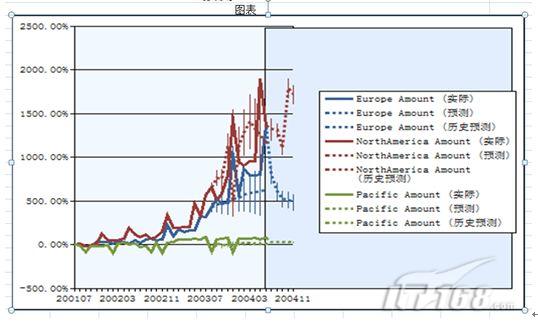
图8 预测数据挖掘结果
由上面的简单演示可以看到,使用外接数据挖掘工具后,您只需要选择文件,点点鼠标就能完成功能复杂的数据挖掘工作,此页面上附带的其它数据挖掘工具使用也很简单,感兴趣的读者可以自己尝试一下。
出了数据挖掘工具,外接程序还提供了数据分析工具,其能够操作的面板如图9所示:
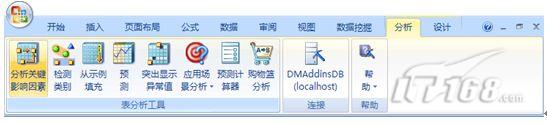
图9 数据分析工具
使用数据分析工具可以对关键影响因素、检测类别、从示例填充、预测、突出显示异常值、应用场景分析、预测计算器、购物篮分析,其中预测计算器和购物篮分析是新增加的功能。
步骤三:读取Reporting Service,操作并使用预测数据和成果
报表服务为公司提供了满足各种各样的报表场景的能力。
? 管理报表生成。经常被称为企业报表生成——支持涵盖了业务所有方面的报表创建,并可在整个企业范围内发送报表,使每个雇员都可以及时的访问到与他们的业务领域相关的信息,并使他们可以做出更好的决策。
? 即时报表生成。使用户可以创建他们自己的报表,并使他们快速灵活的获得他们需要的信息,并且是以他们需要的格式,而不必提交请求和等待报表开发人员来为他们创建报表。
内嵌的报表。使公司可以将报表直接内嵌到商业应用程序和web门户网站中,用户也可以在他们的业务处理过程中使用这些报表。与Microsoft Office SharePoint Server 2007的深度集成还使得公司可以通过一个中央库来发送报表,或直接在SharePoint中使用用于轻度渲染报表的web部分,从而能够轻松的创建仪表盘。在这种方式下,公司可以将整个公司的所有关键的商业数据,包括结构化的和非结构化的放在一个中央存储地址,为信息访问提供了一个共同的体验,以便用户可以浏览到主要的业务执行信息。
Reporting Services 提供了三个报表设计工具,即 Business Intelligence Development Studio 中的报表设计器、Report Builder 1.0 和 Report Builder 3.0;还提供了一个报表模型设计工具,即模型设计器。
报表设计器是一种图形界面,用于创建功能齐全的 Reporting Services 报表。您可以访问多种类型的数据源并创建高度自定义的报表。完成报表后,您可以访问所有 Reporting Services 报表管理功能。
Report Builder 3.0 是一种直观的报表创作环境,专门针对 Microsoft Office 进行了优化,适用于喜欢在熟悉的 Office 环境下工作的业务用户。它还支持 Reporting Services 中提供的高级报表功能。
Report Builder 1.0 是一种客户端应用程序,协助生成即席报表。Report Builder 1.0 在 2005 年首次发布,并仍可在当前版本中使用。
使用模型设计器,可以选择要在模型生成进程中应用哪些规则,并且可以修改模型及其基础数据源视图。模型可以用作其他报表创作工具中的数据源,如报表设计器或报表生成器。
在步骤三种,我们可以使用Report Builder 3.0来设计报表,设计完成的报表可以导出到Excel文件中,这样就可以使用外接数据挖掘工具进行数据挖掘,并且能够使用数据挖掘和分析面板中的预测功能。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
SQL Server 数据仓库迅速扩张市场
微软SQL Server有健壮的产品和较低的成本,该产品已经把自己定位为中端市场数据仓库业务的重要竞争者,并日益向整个数据仓库市场扩张。
-
微软SQL Server 2012:撒大网 捕大鱼
微软公司曾经提出过让商务智能“大众化”的策略,于是着手建立了一个庞大的基于其SQL Server平台的BI阵容。
-
PowerPivot:用DAX公式创建度量值
有了DAX,你可以把复杂的分析和全面的BI合并到Excel环境中,让你的电子表格世界变成开放的疆域。
-
PowerPivot:使用DAX公式来计算列
DAX公式与传统的Excel公式类似,但是功能要多得多。传统的Excel公式在二维数据集的处理上有一些限制,而DAX可以支持你处理更大的数据集。