
SQL Server 2017新增了图形数据库功能,你可以使用图结构来表示不同数据元素之间的关系。 SQL Server 2017增加了对图形数据库的支持,这有助于简化数据集的处理和查询,这些数据集可以被映射成图形形式,这在医疗、客户和社交网络等数据上十分有用。在许多情况下,相比于传统的关系型数据库,SQL Server 图形数据库能够更好地处理那些日益丰富的数据类型。 微软将图形数据库功能集成到SQL Server数据库引擎中,以利用那些广为人知的的核心组件,如存储引擎、查询处理器和元数据等功能。
这样你就可以在使用图形数据库的同时使用机器学习服务、columnstore索引和各种实用工具如S……
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
SQL Server 图形数据库一窥
节点是一个实体,例如人、位置、产品或企业都属于实体。在图形数据库中,将相关节点分组到节点表中。举例来说, 如果你构建一个图形数据库,来支持一个图书爱好者的论坛,你可以创建存储图书,作者,读者的节点表。这些表将分别包含图书、作者和读者的每个实体。 边缘描绘了两个节点之间的关系或连接。类似于处理节点的方式,将相关的边分组到图形数据库的边表中。 回头来看图书爱好者论坛的例子,你可以创建一个名为“WrittenBy”的边表,以表示书与作者的关系。然后,你还可能会创建一个推荐表,以显示哪些读者推荐哪些图书和作者。这两个边表能够表示这三种类型的节点之间的关系。 为了更好地理解节点和边的工作方式,请参考图1中的图形,它显示了三个节点以及它们之间定义的关系。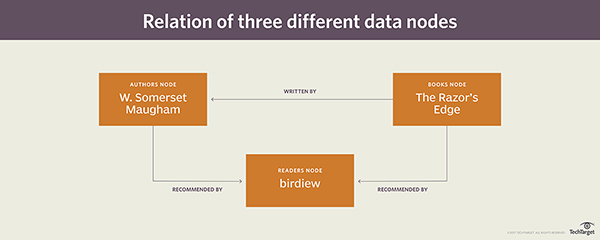
图1 三个数据节点以及它们之间的关系
虽然这个图只显示了三个节点,但我们可以将更复杂的关系整合到SQL Server图形数据库中。 例如,一个作者可以写多本书,多个作者可以合著一本书或多本书。读者推荐不同的书籍和作者,还有读者与读者之间推荐的关联等。构建图像数据库表
节点表包括自动生成的ID列和描述节点的一个或多个列。在图形数据库的理论中,这些附加的列被称为属性。例如,Authors表可能包括first、middle和last names的属性。属性列中的值与传统SQL Server表中的列值类似。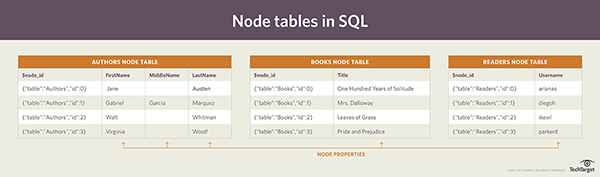
图2 显示了图书爱好者论坛的SQL Server 图形数据库中的节点表
默认的ID列,称为$ node_id,实际上是一个伪列,它映射到一个包含$ node_id_的内部名称,作为全局唯一标识符。在引用该列时,你可以在任何查询中使用这个伪列名。 SQL Server的数据库引擎自动生成$ node_id列中的值,它将节点表的ID和基于整数的bigint值合并在一起。SQL Server将值显示为JSON字符串。在图2中,你只能看到这些字符串的一部分,完整的值要长得多。例如,下面的JSON字符串显示了作者表最后一行的实际值: {"type":"node","schema":"dbo","table":"Authors","id":3} 该字符串标识表类型(node)、数据库模式(dbo)、表(Authors)和单个节点ID(3),在本例中,这个ID对应的作者Virginia Woolf。 边表采用稍微不同的方法。它包括三个自动生成的列:$ edge_id、$ from_id和$ to_id。$ edge_id列与节点表中的node_id类似。它作为一个伪列,便于引用,它会自动为数据库中的每条边生成唯一的id。一条边表示的关系
$ from_id和$ to_id列用来关系两端的节点;它们一起定义了图形数据库中节点之间的连接。边表还可以包括属性列,但这些列是可选的。 图3显示了上述WrittenBy,RecommendedBy边表格;后者还包括一个推荐RecommendedDate列。
图3 SQL Server图形数据库中的边表示例
与$ edge_id和$ node_id列一样,$ from_id和$ to_id列的值是JSON字符串的截取,用以表示引用的节点。例如,WrittenBy表的第一行显示了book 0和author 1之间的关系,这表明书籍One Hundred Years of Solitude是由Gabriel Garcia Marquez编写的。 作为SQL Server 2017的一部分,微软已经更新了一些Transact - SQL语句,使其能够创建节点表和边表,并在边表中填充关系数据。此外,你还可以使用Transact-SQL编写语句来修改表定义,并对表中的数据进行查询和分析。 当然,建立和管理SQL Server 图形数据库比我们在这里介绍的要复杂得多,本文的目的是让你更好地了解它是如何工作的。如果你正在处理的应用程序数据可以从图形结构中获益,那么你有充足的理由来考虑使用SQL Server 2017。
翻译

TechTarget特邀编辑。北京邮电大学计算机科学与技术专业硕士。熟悉软件开发流程,对系统管理,网络配置,数据库应用等方面有深入的理解和实践经验。现就职于IBM(中国)投资有限公司,从事IBM服务器相关软件的开发工作。业余时间喜欢游泳登山,爱健身,喜欢结交朋友。
相关推荐
-
云端SQL Server高可用性最佳做法
与内部部署相比,在云端运行SQL Server可为数据库软件用户提供更多的灵活性和可扩展性,也可能更省钱。但云 […]
-
如何在Azure部署时选择合适的SQL Server?
想要在Azure上运行SQL Server,企业一般会面临两种选择:在Azure虚拟机上安装SQL Server或使用Azure SQL Database。
-
Linux支持的引入 推动了SQL Server 2016集成服务的发展
随着SQL Server的不断发展,集成服务也在发生相应的变化。在最新的SSIS更新中,增加Linux支持和SQL Server 2016升级向导。
-
Notre Dame对云端SQL Server性能基准的探索实践
确立SQL Server的性能基准,对于云端迁移来说是至关重要的第一步,一位来自于University of Notre Dame 的DBA表示,他正在试图通过数据库监控软件,找出SQL server的性能基准。