
- 以Java构建,内部实现相当复杂,本厂几位读源代码的同学都没能搞定;
- Client 过于厚重,实现比较封闭,没办法进行定制扩展开发,前段时间我们做HBase Fail Fast机制时就吃了大亏;
- 内部组件状态不透明,各个组件的关联关系相当复杂,某一模块出问题就可能导致全局出问题;
- 服务恢复复杂,各个组件之间有比较多的关联;
- 由于数据量较大,有的集群恢复时间以天为单位,对服务影响较大,前端稳定性配合的难度也比较高;
- 单集群规模过大,这时瓶颈是带宽和磁盘速度,其解决方案只能是保持集群规模,否则只能祈祷集群整体不要出问题。虽然HBase提供的是一体化的解决方案,但为了确保服务故障时能够快速恢复,还是要控制单个集群的规模,必要时要对集群进行拆分;
- Client实现复杂的问题,如果代码嵌入不进去,那么就当个黑盒用,我们的Fail Fast就是当做黑盒,从近期几次问题来看,效果还是很理想;
- 对代码体系掌控不足的问题,对于这么一个复杂的问题,第一步应该是先掌握最简单的模型,然后逐步去了解周边的各种功能模块;
- 对于修复复杂的问题,可以用最经典的解决方案:“重做整个集群”,如果面对一个棘手的问题重做是更优的解决方案;
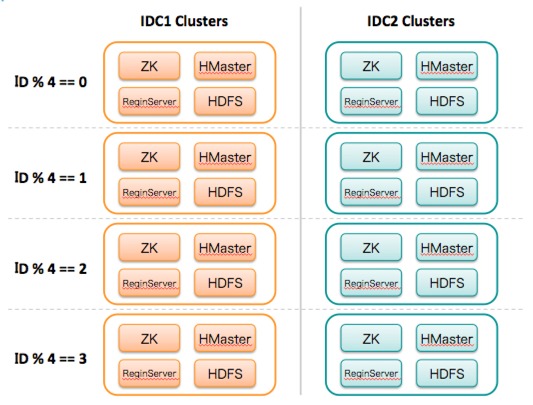
如上的解决方案在资源上会有一些冗余,但如果应用在核心服务则可以确保服务有非常高的可用性保障。相比于Mysql的解决方案,按2000亿条数据(恢复时间在24小时左右,业务能忍受的极限)一个集群算,集群内的容量线性扩容,依然是一个很好的万亿级数据的解决方案。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
基于HBase构建可伸缩的分布式事务队列
在 HBase 的帮助下,结合最佳实践,我们该如何创建了一个线性可伸缩的,分布式事务队列系统。
-
开源第一弹:什么是HBASE?
在数据研究人员的工具集上有着大量的工具可以使用,这对于大数据技术,既是一件好事也是一件坏事。
-
集群软件让电商网站运行更稳定
SIOS的解决方案能够让用户避免不必要的停机时间,同时能够利用本地存储来搭建一个Windows或Linux服务器集群,无需再额外部署一个SAN。
-
如何在一台服务器上安装两个PXC集群节点
我认为在单个物理服务器上运行2个或多个Percona XtraDB Cluster(PXC)节点这样没有什么意义,除了教育和测试目的,但在这种情况下这样做仍然是有用的。