
PostgreSQL 是一个对象关系型数据库,由来自全球一组网络开发者开发。它是一个可代替如Oracle、Informix商业数据库的开源版本。
PostgreSQL 最初由加州大学伯克利分校开发。1996年,一个小组开始在互联网上开发该数据库。他们使用email分享想法,用文件服务器分享代码。PostgreSQL现在在功能方面、性能方面以及可靠性上可与商业数据库比肩。它支持事务、视图、存储过程和参考完整性约束。它也支持大量的编程接口,包括ODBC、Java(JDBC)、TCL/TK、PHP、Perl以及Python。得益于互联网开发者人才库,PostgreSQL 还有广阔的增长空间。
性能概念
数据库性能优化有两个方面。一方面是提高数据库对电脑CPU,内存和硬盘的使用。另一方面是最优化传递到数据库的查询。这篇文章讨论的是在硬件方面优化数据库性能。通过使用例如:CREATE INDEX,VACUUM,VACUUM FULL,ANALYZE,CLUSTER和EXPLAIN这些数据库SQL命令,插叙查询的最优化已经完成了。这些在我写的《PostgreSQL:Introduction and Concepts》这本书中已经讨论过了。
为了理解硬件性能的问题,就必须理解在电脑的内部发生了什么。简单的说,一台电脑可以被视为一个被存储器包围的中央处理单元(CPU)。在和CPU同一小片上的是不同的寄存器,它们保存了中间运算结果和各种指针以及计数器。包围这些的是CPU cache,其中有最新的访问信息。越过CPU cache是大量的随机存取存储器(RAM),它保存了正在运行的程序以及数据。在RAM的外围就是硬盘了,它保存了更加多的信息。硬盘是唯一可以永久存储信息的区域。,所以电脑关机后,所有被保存下来的信息都在这里。归纳起来,这些是包围CPU的存储区域:
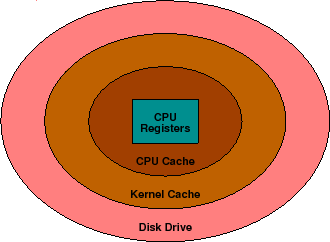
存储区域 容量
CPU寄存器 几字节
CPU高速缓存 几千字节
RAM 几兆字节
硬盘 几千兆字节
你可以看到储存大小随着离CPU距离的增加而增加。理论上,大容量的永久存储可以被安置在CPU的旁边,但是这将变的很慢而且很昂贵。实际当中,最常用的信息被放在CPU的旁边,而不怎么用的信息就放得离CPU远远的。在CPU需要的时候再拿给CPU。
缩短数据与 CPU 的距离
数据在各种存储区域的转移是自动执行的。编译器决定哪些数据存在寄存器里头。CPU 决定哪些数据存在缓存里面。 操作系统负责内存和硬盘之间的数据交换。
数据库管理员对 CPU 的寄存器和缓存无能为力。要提高数据库的性能,只能通过增加内存中的有用数据量, 从而减少磁盘访问来获得。
看似简单, 其实不然, 内存中的数据包含很多东西:
-
正在执行中的程序
-
程序的数据和堆栈
-
PostgreSQL共享缓存
-
内核磁盘缓存
-
内核
理想的性能调整, 既要增加内存中的数据库数据占有量,又不能对系统造成负面影响。
PostgreSQL共享缓存
PostgreSQL没有直接访问磁盘,而是访问PostgreSQL的缓存。然后再由PostgreSQL的后台程序读写这些数据块, 最后写到磁盘上。
后台首先在表中,查找缓存是否已经存在这些数据。 有, 就继续处理。没有, 则由操作系统从内核磁盘缓存, 或者直接从磁盘加载这些数据。无论哪一种,代价都很高。
PostgreSQL默认分配 1000 个缓存。每个缓存有 8k 字节。增加缓存的数量,能增加后台访问缓存的频率,减少代价较高的系统请求。缓存的数量,可以通过 postmaster 命令行的参数, 或者配置文件 postgresql.conf 中的 shared_buffers 的值来设置。
多大才算太大?
你可能在想, “那我把所有的内存都分配给 PostgreSQL的缓冲区好了”。 如果你这么做, 那系统内核以及其他程序就没有内存可用了。理想的PostgreSQL共享缓冲区大小,是在没有对系统产生不利影响的情况下, 越大越好。
要理解什么是不利影响,首先要明白 UNIX 是如何管理内存的。要是内存容量足够大,能容下所有的程序和数据。 那我们也就用不着管理内存了。问题是, 内存的容量有限,所以, 需要内核将内存中的数据分页, 存入磁盘,这就是传说的的数据交换。原理是, 将当前用不上的数据移到磁盘中。这个操作叫做交换区页面移入(swap pageout)。页面移入交换区不难,只要在程序非活跃期执行就可以。问题在于, 页面重新从交换区移出来的时候。 也就是, 移到交换区的旧页面, 又重新移回内存。这个操叫交换区移出( swap pagein)。说它是个问题, 是因为, 当页面移入内存的时候, 程序需要终止执行, 直到移入操作完成。
系统的页面移入活跃情况, 可以通过像 vmstatand sar 这种系统分析工具来查看, 是否有足够的内存, 维持系统的正常运作。不要把交换区页面移出,跟常规的页面移出搞混了。常规的页面移出, 将页面数据从文件系统中读出来,当作是系统操作的一部分。如果你看不出, 是否有交换区页面移出操作。但是交换区页面移入的操作非常活跃, 这也说明,有大量的页面移出的操作正在进行。
高速缓存(cache)容量的影响
或许你会想为什么高速缓存的大小如此重要。首先,试想一下PostgreSQL共享缓存大到可以放下整张表。重复连续扫描这张表就不需要硬盘的参与,因为数据已经在cache里了。现在假设cache比表小一个单元。一次连续的扫描将会把所有单元载入cache直到最后一个单元。当需要最后一个单元时,最初的单元被移除。当另一次连续扫描开始的时候,最初的单元已经不再cache里了,为了载入它,最开始的单元会被移除,也就是第一次扫描时的第二个单元会被移除。这将持续进行到单元结束。这个例子很极端,但是你可以看到减少一个单元就将会把cache的效率从100%变为0%。这表明找到合适的cache容量会戏剧性的改变性能。
合适容量的共享缓存
理论上,PostgreSQL共享缓存将是:
-
它应该足够大来应付通常的表访问操作。
-
它应该足够小来避免 swap pagein 的发生。
记住数据库管理器运行时分配所有的共享存储。这一区域即使在没有访问数据库的请求时也保持一样大小。一些操作系统pageout未指定的共享存储,而另一些LOCK共享存储到RAM中。LOCK贡献存储更好一点。PostgerSQL的管理员指导手册里有关于不同操作系统核心配置的信息。
内存排序队列大小
另一个优化参数是排序队列的内存总量。当对大表或一个记录集排序时,PostgerSQL会将他们分块排序,将中间结果存储在临时文件里。这些文件将在所有队列处理完毕后合并使用。增加每一队列的大小就会产生更少的临时文件同时加快处理速度。然后,如果队列过大,部分内存队列就会在处理过程中pageout到虚拟内存从而导致pagein的发生。因此,用小点的队列产生更多的临时文件会快很多,但又一次,当太多内存被分配时,虚拟内存pagein产生。记住这个参数是后端使用在处理批次上的,而不是 ORDER BY, CREATE INDEX或合并。多少同时的排序就会用多少倍这么多的内存。
这个值可以通过数据库管理器命令行标志改变或通过改变在postgresql.conf中sort_mem的值来改变。
缓存规模和排序规模
缓存规模和排序规模都会影响内存的使用。你不可能增加一个的规模, 而不影响另外一个。记住,缓存的规模是在 postmaster 启动的时候, 就设好的。 而排序的规模择由排序的数量决定。一般情况下,缓存规模要大过排序的规模。不过, 某些用到 ORDER BY, CREATE INDEX 或数据合并的查询, 可以通过加大排序规模来提速。
此外, 许多操作系统对共享内存的分配有限制。修改这一限制, 就意味着, 要重新编译或者配置内核。也就是说, 你要对操作系统这方面相当熟练才行。更多信息, 参考 PostgerSQL管理员操作手册。
在调整的开始,使用15%的RAM作为缓存大小,如果有几个大的事物就用2-4%的内存做排序大小,如果你有很多小事物的话就使用更小的内存。你可以尝试提高它来看看性能是否提升,swapping交换是否发生。如果共享缓存过大,你就花费太多时间来维护大量的缓存,而且它会浪费掉本可以被其他进程使用的RAM,无法作为额外的内核磁盘的缓存。
有价值的服务器参数是effective_cache_size。这个参数被优化器用来估计内核磁盘缓存的大小。在使用统一缓存的内核里,这个值应该设为内核未使用RAM的平均值,因为这样内核就可以使用未使用的RAM来缓存最近访问的磁盘页。在有固定磁盘缓存的内核里,这个值应该设为内核缓存的大小,一般为RAM的10%。
Disk Locality
磁盘本身的特点, 决定了他的性能跟上面提到的其他存储方式不同。别的存储方式, 访问数据中的任何一个字节, 速度都是一样的。 而磁盘,由于磁盘片在不断的转动, 磁头在不断的移动,访问离磁头当前位置近的数据, 速度要比离磁头远的数据快。
磁头从一个柱面, 移动到同一个磁盘片的另外一个柱面, 比较耗时间。Unix 内核开发人员当然知道这一点。所以在磁盘上存储大文件的时候,他们尽可能把同一个文件的存储块紧挨在一起存放。例如:我们有一个文件, 在磁盘上保存, 需要占10个存储块。操作系统会把 1-5 存储块放在一个柱面, 而 6-10 存在另外一个柱面。从头到尾读取这个文件, 只需要磁头移动两次 — 一次移到存放 1-5 存储块的柱面, 另外一次移到存放 6-10 那个柱面。但是, 如果文件的读取不按存储块的顺序来,比如 1,6,2,7,3,8,4,9,5,10, 那么读完整个文件就要移动磁头十次。 所以, 对于磁盘来说,按顺序访问要比随机访问快的多。这也是为什么, PostgerSQL在读取表中的大量数据时, 宁可选择顺序扫描, 也不用索引扫描。 磁盘的这个缺点, 让我们看到了缓存的价值。
多磁盘
数据库操作期间, 磁头会频繁移动. 太多的读/写请求, 会导致磁盘队列饱和, 性能急剧下降. (我们可以通过 Vmstat 和 sar 这两种工具, 查看磁盘的活动情况 )
其中一个解决磁盘队列饱和的办法是, 将部分PostgerSQL数据文件移到其他磁盘. 注意, 别把文件移到同一个磁盘的其他文件系统. 因为同一个磁盘上的所有文件系统共享一个磁头.
数据库分布到不同磁盘的方式, 有下列几种:
-
转移数据库, 表, 索引(Databases,_Tables,_Indexes)
-
利用表空间(Tablespace)在不同磁盘上创建对象.
-
转移预写日志
-
通过 initdb -X 和 符号链接文件(symbolic link) 将 pg_xlog 目录移到其他磁盘. 跟其他写操作不同, POSTGRESQL 日志写操作, 必须在事务结束前, 提交给磁盘. 就算使用缓存, 也无法推迟这些写操作. 在不同磁盘上保存日志, 可以减少磁头的移动造成的延时. ( postgres -F 参数 可以关闭”日志保存(在磁盘上)”这项功能. 但是, 如果遇到操作系统崩溃, 只能通过备份文件恢复.)
其他方法还有, 利用 RAID 磁盘阵列将单个文件系统分布到多个磁盘中. 虽然, 镜像导致数据库写入速度变慢, 但是可以提高读取的速度. 因为, 数据可以同时从多个磁盘上读出来. 很多网站都喜欢用 RAID 1+0 或 RAID0+1, 原因是, 它有分段操作提高性能, 镜像文件保障可靠性. RAID 5 在磁盘数量不少于 6 个的时候, 速度最快. 理论上, RAID5 都有用电池做后备电源的写缓存, 所以磁盘写入操作效率很高, 不至于会拖程序的后腿.
磁盘缓冲
现在的磁盘都有读和写缓冲。读缓冲保存最近的读请求在磁盘的内存里面。 写缓冲保存最近的写请求, 知道他们能有效地存到磁盘上。可能你已经看到了, 这里有个问题 — 要是写缓冲区里面的数据还没来得及存到磁盘上, 就断电了怎么办?有些磁盘和 RAID 控制器, 都有电池做后备电源, 能将写缓存里面的数据保持到供电回复位置。不过, 多数磁盘和 RAID 控制器都没有这个功能, 所以可靠性是个问题。
好在, 大部分磁盘都可以关闭写缓存。SCSI 磁盘写缓存一般都是关闭的。 IDE 磁盘的写缓存默认是开启的, 但是可以在操作系统中, 使用命令行 hdparm -W0, sysctl hw.ata.wc = 0, 或 scsicmd 关闭。那是, 有些 IDE 磁盘虽然提示写缓存已经关闭, 其实还是在用。结果导致磁盘变得不稳定。没有代价高昂的测试, 是很难看出来磁盘的写缓存是否真的关闭了。
由于 PostgreSQL 每次都要调用 fsync() 将预写日志写入磁盘,并等到日志写操作执行完毕,才提交事务。所以, 如果使用写缓存,用户会发现, 性能变快了很多。 因此,对于 PostgreSQL 来说,从性能和可靠性这两方面衡量,最好能使用有电池做后备电源的写缓存。
SCSI vs. IDE
SCSI 盘通常要比 IDE 磁盘贵的多. SCSI 磁盘有个协议, 用于控制器和操作系统之间通信. 而 IDE 磁盘则简单得多, 一次只能接受一个请求. SCSI 磁盘的带标队列(tagged queueing) 能同时接受多个请求, 并自动排序, 以便提高效率. 这是为什么, 在单用户, 单文件操作的时候, SCSI 和 IDE 磁盘在性能上如此相似。不过在多用户, 多处理器的情况下, SCSI 性能要比 IDE 好得多。也正是这个原因, SCSI 更适合用在高负载的数据库服务器上。
其实, SCSI 和 IDE 的差别就只有一种 — 一个是专为高性能, 高可靠性设计的企业级磁盘;另外一个是优先考虑成本的个人电脑磁盘。这篇文章详细的描述了,厂商是如何以性能, 可靠性和成本为衡量标准, 生产制造磁盘的. 是一篇相当不错的磁盘选购指南。
文件系统
一些操作系统支出多磁盘文件系统。一些情况下,这将很难看到哪一个文件系统最好。PostgresSQL通常在传统的Unix文件系统中表现最好,比如很多操作系统支持的BSD UFS/FFS 文件系统。UFS默认的8K块大小和PostgresSQL的分页大小一样。你可以在其上运行日志文件系统或基于日志的文件系统,但是这会增加fsync的先写日志开销。稍早的基于SvR3的文件系统变得太破碎化而无法达到很高的性能。
Linux的文件系统实在太多了,因此很难做出选择。并且没有一个是十全十美的:ext2不是完全崩溃安全,ext3,XFS和JFSare 是基于日志的,而Reiser对小文件很完美而且也登载日志。journalling文件系统比ext2慢了一大截,不过它支持崩溃恢复,ext2最好别用。如果必须要用ext2的话,给它设置下同步。有些人建议ext3系统应该设置data=writebck。
NFS和别的远程文件系统不推荐用在PostgresSQL上。NFS的文件系统的 语义和本地文件系统的语义不同,而这些差别将导致数据可靠度和奔溃恢复的出现问题。
多中央处理器
PostgresSQL使用多进程模式,意味着每一个数据库都有自己的处理单元。因此,所有的多中央处理器操作系统都可以通过可用的CPU来spread多数据库。然后,如果只有一个数据库连接,那么它只能使用一个CPU。PostgresSQL不允许使用多线程来让一个进程使用多个CPU。
检查点(checkpoint 事件)
当先写日志文件填满后,一个checkpoint事件会强制所有缓冲块进入硬盘好让日志文件再使用,Checkpoints也会定时自动执行,通常时间间隔是5分钟。如果有大量数据库写入,那么先写文件日志将被迅速填满,导致极度缓慢,因为所有的缓冲块都涌向了硬盘。
checkpoint应该每几分钟产生一次。如果一分钟产生好几次的话,性能将会变差。为了判断checkpoint是否过于频繁,检查由checkpoint_warning产生的日志信息。如果你的checkpoint每30s内不止一次就会产生这个信息。
减少checkpoint频率包括增加在data/pg_xlog的先写日志文件。每一个文件为16M,因此对硬盘的影响是可见的。默认安装使用了最小数量的日志文件。为了减少checkpoint的频率,你需要增加这个参数:
-
checkpoint_segment=3
默认的值是3,增加这个值直到checkpoint每几分钟才产生一次。另一个日志文件:
-
LOG:XLogWrite:new log file created-consider increasing WAL_FILES
这条信息表明postgresql.conf中的wal_files参数应该增加。
总结
幸运的是,PostgreSQL不需要太多的调整。大部分参数会自动调整以维持最佳性能。管理员也可以控制高速缓存的大小和排序规模的大小来优化可用内存的使用。硬盘存取也可通过驱动延展。其它的参数也可以通过share/pstgresql/conf.sample设置。你可以复制此文件到data/postgresql.conf来尝试PostgreSQL 的一些更另类的参数。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
2017年1月数据库流行度排行榜 新年新气象
新年新气象,数据库知识网站DB-engines最近更新了2017年1月份数据库流行度榜单。TechTarget数据库网站将与您分享1月份的榜单排名情况,让我们拭目以待。
-
2016年12月数据库流行度排行榜 几家欢乐几家愁
在过去的6个月中,数据库排行榜的前二十名总体上没有太大的变动,那么数据库知识网站DB-engines最近更新的2016年12月份数据库流行度排名情况是否一如既往的沉寂、低调呢?
-
2016年10月数据库流行度排行榜 两组数据库棋逢对手
数据库知识网站DB-engines更新了2016年10月份的数据库流行度排行榜,10月份的榜单又有哪些变化,哪些惊喜呢?
-
2016年9月数据库流行度排行榜 PostgreSQL超MongoDB居第四
数据库知识网站DB-engines更新了2016年9月份的数据库流行度排行榜。TechTarget数据库网站与您分享9月份的榜单。