
MySQL复制操作可以将数据从一个MySQL服务器(主)复制到其他的一个或多个MySQL服务器(从)。试想一下,如果从服务器不再局限为一个MySQL服务器,而是其他任何数据库服务器或平台,并且复制事件要求实时进行,是否可以实现呢?
MySQL团队最新推出的 MySQL Applier for Hadoop(以下简称Hadoop Applier)旨在解决这一问题。
用途
例如,复制事件中的从服务器可能是一个数据仓库系统,如Apache Hive,它使用Hadoop分布式文件系统(HDFS)作为数据存储区。如果你有一个与HDFS相关的Hive元存储,Hadoop Applier就可以实时填充Hive数据表。数据是从MySQL中以文本文件形式导出到HDFS,然后再填充到Hive。
操作很简单,只需在Hive运行HiveQL语句’CREATE TABLE’,定义表的结构与MySQL相似,然后运行Hadoop Applier即可开始实时复制数据。
优势
在Hadoop Applier之前,还没有任何工具可以执行实时传输。之前的解决方案是通过Apache Sqoop导出数据到HDFS,尽管可以批量传输,但是需要经常将结果重复导入以保持数据更新。在进行大量数据传输时,其他查询会变得很慢。且在数据库较大的情况下,如果只进行了一点更改,Sqoop可能也需要较长时间来加载。
而Hadoop Applier则会读取二进制日志,只应用MySQL服务器上发生的事件,并插入数据,不需要批量传输,操作更快,因此并不影响其他查询的执行速度。
实现
Applier使用一个由libhdfs(用于操作HDFS中文件的C库)提供的API。实时导入的过程如下图所示:
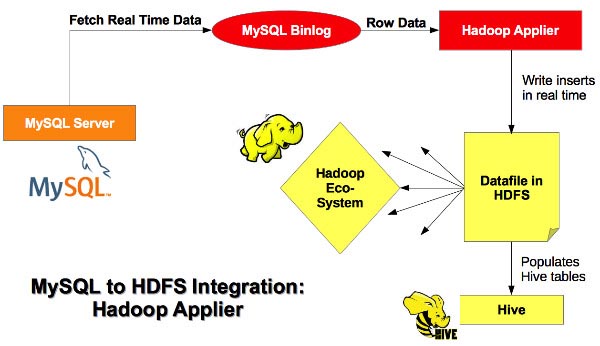
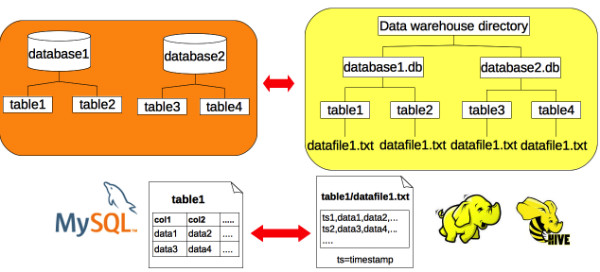
数据库被映射作为一个单独的目录,它们的表被映射作为子目录和一个Hive数据仓库目录。插入到每个表中的数据被写入文本文件(命名如datafile1.txt),数据以逗号或其他符号分割(可通过命令行进行配置)。
下载地址:mysql-hadoop-applier-0.1.0-alpha.tar.gz(alpha版本,不可用于生产环境)
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Cloudera-Hortonworks合并或将减少Hadoop用户的选择
近日大数据领域两家顶级供应商达成交易协议,这可能会影响Hadoop和其他开源数据处理框架,并使大数据用户的技术 […]
-
Azure数据湖分析从U-SQL中获得提升
大数据的发展已经让许多精通SQL的数据专业人员不知所措。微软的U-SQL编程语言试图让这些人回归数据查询游戏。
-
进入机器学习时代,数据库何去何从?
Vertica之前就已经能够对Hadoop数据进行访问,但Vertica8.0分析引擎则能够与Hadoop数据适当协作,如此一来就能减少数据迁移。
-
NoSQL——未来数据库家族的一员
NoSQL是对数据库由内而外的全方位改造,从而创造出一个高容量、高速度和高可变性的架构。然而,NoSQL供应商在可变性部分却正在遭遇失败。