
对于计数器大家肯定还有或多或少的疑问。
Q1:计数从哪里来?
通常我们发布的社交内容会存储在数据库中,最常见的如MySQL:
更新索引:insert into user_message(uid,messageid) values(‘xx’,’xx’)
更新内容:insert into message_2013_05(messageid,message) values(‘xx’,’xx’);
为什么要进行索引和内容区分我这里就不多熬述了,这时要计算我有发送了多少个message,再mysql库中select count(messageid) where uid=xxx 就可以获得我们想要得计数,也就说大多数情况它源于我们的索引数据。
Q2:计数和其他数据相比有什么特点?
1.单key读写频繁,总体读取量我们认为可能比内容模块还要频繁,索引的增删改查都会导致计数器的频繁增减。尤其当某篇twitter,feed,weibo非常火爆时,单key的更新将更加火爆。
2.需要持久化,所有用户都可能需啊知道自己的计数,这个数据和内容本身一样重要。
从上面这两个需求来看选用Redis就是水到渠成了,而应对hotkey从Mysql update count+1 & Memcache 替换成Redis incr更是优雅很多。减少了很多数据一致性的风险。
优化的思路:
- 单独维护计数,从获取更新复杂度O(n)到O(1)
我们知道随着单个uid->message的个数越来越多,而count(message_id)的逻辑复杂度是O(n),获取这个计数的成本是越来越大。如何让其获取变为O(1)?其实很简单,我们只要单独维护一下这个计数就可以了。举一个简单的例子来说明:
假设我们有个字段,我们需要频繁的获取和更新这个字段的长度,引用Redisbook中的一段对于redis 用于存储key value的sds的描述好像能简单的叙述这件事情。
“
比如说, hello world 在 C 语言中就可以表示为 “hello world�” 。
这种简单的字符串表示在大多数情况下都能满足要求,但是,它并不能高效地支持长度计算和追加(append)这两种操作:
- 每次计算字符串长度(strlen(s))的复杂度为 θ(N) 。
- 对字符串进行 N 次追加,必定需要对字符串进行 N 次内存重分配(realloc)。
| struct sdshdr { len = 11; free = 0; buf = “hello world�″; // buf 的实际长度为 len + 1 }; |
通过 len 属性, sdshdr 可以实现复杂度为 θ(1) 的长度计算操作。
”
- 前端还是后端维护计数,哪个更优?
前端维护:当发生message_id的增减时,client端进行一次transaction提交,索引更新及技术更新。优点是逻辑比较简单,就是原来单次写入变成了多次写入,缺点是易引起数据不一致。
后端维护:当数据库接收到message索引增减后,会产生相应的操作log,对于MySQL来说就是Binlog,我们根据mysql insert及delete 对索引计数进行增减操作。
不推荐MySQL及MySQL 触发器更新的原因有如下几个:
1.Mysql本身可能成为更新瓶颈。mysql update其实是一种重更新,在buffer pool未命中的情况下,需要把where id=xxx的page从磁盘加载到内存中,在大并发的hot key更新时,这点很有可能成为瓶颈。
2.Mysql Replication的效率问题。Mysql Replication在如上写入更新频繁的情况下,也会成为瓶颈,当你的发了一篇feed,却发现过了一分钟计数才更新,这个肯定是不能容忍的。
3.Mysql trigger相关bug比较多:
如下是我们线上环境遇到的一个trigger引发的同步中断问题:http://bugs.mysql.com/bug.php?id=53079
后端维护的思路
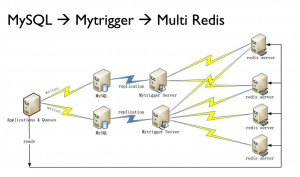
详细可见 @jackbillow http://www.programmer.com.cn/14577/ 中使用Redis方法
其实选择前端维护还是后端维护实际应该取决于你们公司前端及后端技术成熟程度,如果后端技术足够成熟,那么放在后端维护节省的就是大量的开发时间和降低数据一致性的风险,反之,可以放在前端进行维护。
- Redis内存容量优化
Redis kv数据结构如下:
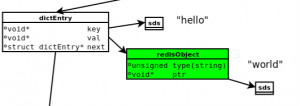
对于简单的k-v场景来说,最好的优化思路就是将图中Redis本身为了通用性创建的dict(16字节)及Redis Object(16字节)去除,sds的额外字节去除,这样假设你的key占用10字节,value 采用int占用4字节:
那么去除之前可能占用的内存是:
string类型的内存大小 = 键值个数 * (dictEntry大小16字节 + redisObject大小16字节 + 包含key的sds大小 + 包含value的sds大小) + bucket个数 * 4
去除之后:
string类型的内存大小 =键值个数 * (key的大小10字节 + value的4字节)+bucket个数 * 4
当你有数亿个key的时候,节省的内容容量将会是相当可观的,当然实际优化的场景肯定会比现在列几个公式复杂,有得必有失。
- 未来计数场景畅想
Redis数据不能将老数据平滑过度到磁盘,无法应用到现SSD等高性能设备是硬伤。
http://nosql.mypopescu.com/post/3745773666/redis-and-hbase-for-mozilla-grouperfish-storage 这篇文章给了不错的思考方向。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
2017年5月数据库流行度排行榜 MySQL与Oracle“势均力敌”
数据库知识网站DB-engines.com最近更新了2017年5月的数据库流行榜单。TechTarget继续与您一起分享最新的榜单情况。
-
2017年3月数据库流行度排行榜 Oracle卫冕之路困难重重
时隔一个月,数据库市场经过一轮“洗牌”,旧的市场格局是否会被打破,曾经占巨大市场份额的企业是否可能失去优势?
-
2017年2月数据库流行度排行榜 攻城容易守城难
2016年下半年,数据库排行榜的前二十名似乎都“固守阵地”,在排名上没有太大的变动。随着2017年的悄然而至,数据库的排名情况是否会有新的看点?
-
MySQL管理特性:让企业适合交易平台
当Alexander Culiniac和他的同事在TickTrade系统公司建立一个基于云的交易平台时,面临一些基本的约束。那就是,系统必须在云上工作良好并且经济实用。