
相比于传统关系型数据库市场,在大数据领域,更多的大型IT厂商都想在其中分得一杯羹。因此我们看到在过去的一年中,有越来越多的传统硬件厂商在变的越来越“软”,包括EMC、惠普在内都推出了自己的大数据软件平台,欲与传统数据库厂商一较高下。而像Oracle、IBM等厂商却变得越来越“硬”,类似于大数据一体机的产品层出不穷。在这里我们总结一下过去一年中,大数据市场都发生了哪些值得关注的事。
EMC成立Pivotal,围绕Greenplum推出Hadoop发行版
今年4月,EMC正式宣布成立独立运营的子公司Pivotal。在此之前他们就围绕收购来的Greenplum发布了Hadoop发行版PivotalHD,同时发布的还有一个名为HAWQ的技术,通过HAWQ能够将Greenplum与Hadoop分布式架构进行紧密地融合。

Pivotal HD可以简单地看做将Greenplum数据库的POSIX文件系统替换成Hadoop分布式文件系统(HDFS),而之前DBA在Greenplum数据库中所能做的所有操作,Pivotal HD都能够提供支持。同业界主流的Hadoop发行版相比,Pivotal HD能够处理更为广泛的大数据工作负载,并在性能方面得到显著的提升,还能够帮助用户节约一半的成本。
HAWQ完全是由EMC和Greenplum团队自主研发的技术,它能够在Hadoop分布式文件系统中提供最纯粹的并行SQL处理。这是一个类似于Cloudera Impala的SQL in Hadoop功能,它的一些特性包括:动态Pipelining,高级数据库查询优化器,纵向扩展功能,SQL兼容功能,交互式查询,深度分析功能以及普遍的Hadoop格式支持等。在新平台Pivotal One当中,Pivotal HD、HAWQ以及Greenplum数据库和GemFire内存技术成为大数据分析的基础。
扩展阅读:Pivotal快速进入状态 欲将云与大数据完美整合
惠普发布大数据平台HAVEn
同EMC相类似,以硬件为主打的惠普同样拥有一家数据库公司,那就是Vertica。但惠普没有选择推出自己的Hadoop发行版,而是对收购来的Vertica、Autonomy、ArcSight等产品进行了优化整合,推出了他们的大数据分析平台HAVEn。
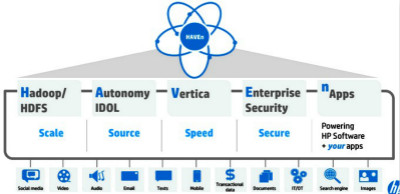
HAVEn是Hadoop(HDFS)、Autonomy、Vertica、EnterpriseSecurity以及nApp(行业解决方案)的缩写。HAVEn中并没有引入新的技术,基本上组合了收购来的软件产品,包括Autonomy非结构化数据分析工具、Vertica高性能数据分析引擎以及ArcSight日志管理。事实上,HAVEn并非一个打包的大数据分析平台,客户可以选择HAVEn中的任一组件来解决实际应用中的大数据问题,而无需一次性上一整套系统。
而Hadoop也是惠普大数据分析平台关注的一个焦点。HAVEn为Vertica分析引擎提供了Hadoop接口,为数据流提供了双向的集成以及专门的Hadoop管理工具。同时HAVEn针对各种Hadoop的版本都提供了支持,包括开源Hadoop以及主流商用发行版本,如Cloudera、Hortonworks以及MapR等。
扩展阅读:惠普发布大数据分析平台HAVEn
Oracle软硬结合,进一步完善大数据平台
我们之前介绍过Oracle的大数据战略,基本上可以总结为Big Data Appliance+Exadata+Exalytics。Oracle认为大数据一直存在,只不过现在包括Hadoop、MapReduce以及NoSQL数据库等技术已经为企业所广泛使用,处理大数据的技术已经达到工业化的水平而已。
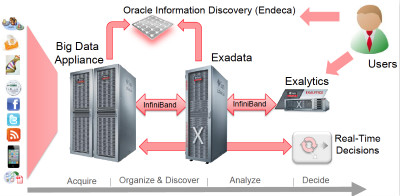
那么在过去一年中,Oracle的大数据战略中又添加了哪些亮点呢?最值得注意的就是他们收购来的Endeca,Oracle Endeca Information Discovery是一款针对非结构化数据的分析工具,能够将海量非结构化数据转化为有价值的商业洞察。Oracle Endeca Information Discover还针对 Exalytics进行了优化和认证,可以快速、直观地分析任意来源组合产生的数据。
另外Oracle也对硬件产品进行了更新,最新的Oracle大数据机X4-2与Oracle大数据连接器和Exadata组成了面向大数据的集成平台,能够帮助企业轻松实现结构化数据和非结构数据的融合。而随着第五代Exadata x4-2的发布,更大内存配合Oracle数据库12c将在大数据时代发挥更大作用。
扩展阅读:甲骨文再度完善大数据平台
IBM技术全面拥抱大数据
如上文所述,IBM发布的DB2 BLU加速器旨在加速大数据分析负载。此外,IBM在今年还发布了最新的专家集成系统PureData for Hadoop,它搭载企业级Hadoop产品BigInsights,提供软硬件一体化的架构与全面的Hadoop工具,降低了用户部署难度。

PureData针对不同的数据工作负载还包括了交易处理(IBM PureData System for Transactions)、分析(PureData System for Analytics)与运营分析(PureData System for Operational Analytics)。随着PureData For Hadoop的发布,IBM专家集成系统(PureSystems)家族已经能够满足结构化数据、非结构化数据以及海量数据分析的需求。
除此之外,IBM今年还发布了新版本的BigInsights与Stream大数据平台,改进了对SQL的支持,提高了安全性和可用性等功能。
扩展阅读:发力大数据:IBM推出面向Hadoop的PureData
Hadoop 2.0时代到来,YARN改变游戏规则
作为大数据时代最热门的一项技术,Hadoop几乎成为了大数据的代名词。今年10月,Apache软件基金会宣布Hadoop 2.0正式GA,新版本的Hadoop将带来大量变化。以HDFS和基于Java的MapReduce为核心组件,Hadoop的早期采用者都在使用它应对海量数据处理,包括结构化与非结构化数据,从日志文件到文本数据,再从传感器数据再到社交媒体数据不一而足。
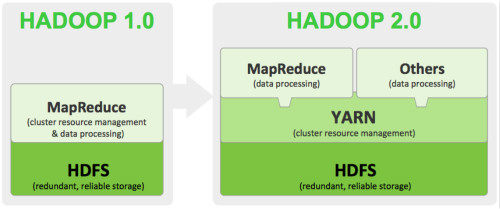
Hadoop 2.0目前已经统一称为Hadoop 2,它已经进入越来越多人的视野当中。其中最重要的一部分就是YARN(Yet Another Resource Negotiator),这个更新的资源管理器能够让非MapReduce开发的应用运行在HDFS上。通过这种方式,YARN旨在解除Hadoop的批处理限制,同时提供与现有应用结构的向下兼容。
之前的Hadoop是在MapReduce基础上构建的,虽然在计算范式上有过很多尝试,但它依然没有脱离MapReduce提供的框架。它以JobTracker和TaskTracker的形式来处理工作负载并管理服务器资源,每个节点都是配置了map和reduce。YARN提供了更好,更灵活的设计,对计算资源处理进行了分离。如果说现代化的操作系统需要包括一个虚拟机和一个资源管理器,那么YARN的出现已经使Hadoop从一个分布式处理架构蜕变为一个分布式操作系统。这对Hadoop来说是具有革命性的,是可以改变游戏规则的。
大数据让NoSQL、NewSQL越来越流行
人们通常喜欢用几个V的概念来描述大数据,其实很简单,大数据除了数据体量巨大之外,它的数据结构也与传统的关系型数据有着很大不同。拿一条电影网站IMDB上的数据来说,如果用传统的关系型数据库来进行存储,它的许多查询就会涉及到大量的表连接,这样的效率非常低;而基于键值对(Key-value)的方式,查询起来就会很方便。社交媒体数据也是如此,这就是为何NoSQL和NewSQL数据库在大数据时代有着更多的用武之地。
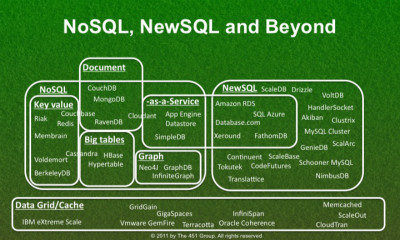
在DB-engines网站每月评选的数据库产品流行度排行榜中,NoSQL数据库的蹿升速度是最快的,其中数据库流行榜的前十名中已有两个NoSQL产品。在过去一年中,图型数据库(Graph DBMS)的流行度变化趋势最大,包括Neo4j这样的数据库产品在过去一年中受到了广泛的讨论与关注。此外像Cassandra这样的列式数据库以及MongoDB这样的文档型数据库已经成为明星级产品。
另外,传统客户的数据量增长速度在加快,这使得他们需要考虑尝试一些新的技术架构来应对这些问题。以列式存储为主,大规模使用基于MPP架构的来满足大数据量处理需求,这是NewSQL数据库所存在的共性。在过去一年中,我们看到一些国产数据库厂商正在试水NewSQL并取得了一定的成绩,在一些基准测试中,国产数据库并不输给那些大牌的数据库产品。南大通用的技术总监武新也认为,大数据为国产数据库的发展提供了千载难逢的良机。
扩展阅读:为什么要选择MongoDB?
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
创建NoSQL数据建模符号 企业架构师亲自上阵
新兴的NoSQL数据风格促使创新的应用程序快速发展,但NoSQL同时也带来了挑战。NoSQL系统能够快速投入生产,有时甚至根本不用创建任何的前期模式。
-
深入理解Amazon DynamoDB NoSQL云数据库服务
Amazon DynamoDB NoSQL云数据库即服务主要为跨移动设备、网页web端、游戏、数字营销和物联网领域的应用提供支持。
-
SQL和NoSQL数据库设计之争
企业收集了很多大规模增长的松散结构化数据,Hadoop,Spark以及其他新技术处理这些数据非常有助于改善商业智能分析效率。
-
深入解读Hadoop十周年——展望篇
本文以技术篇、产业篇、应用篇、展望篇四部分带领大家深入解读Hadoop的昨天、今天和明天,一起憧憬下一个十年。