
本文节选自Krish Krishnan新书《大数据时代的数据仓库》第10章“集成大数据与数据仓库”,是两篇系列文章的第一篇(由Elsevier 销售的Morgan Kaufmann出版社授权)。更多关于数据仓库与大数据集成的内容,请阅读节选自这本书的第二篇文章,另外有一篇Q&A更深入介绍了作者的见解。访问Elsevier商店 ,在2014年1月31日前使用折扣码SAVE3013就可以以3折价格下载全书电子版。
数据集成是指将来源于不同系统的数据组合在一起,供业务用户研究不同的行业行为及客户行为的数据处理方式。在数据集成应用早期,数据仅限于交易系统及其应用。业务决策的制定以决策平台为指导,而有限的数据集提供了创建决策平台的基础。
数据容量与数据类型在过去三十年里大幅增长,数据仓库技术从无到有,基础架构和技术的发展满足了分析和数据存储需求。这一切彻底改变了数据集成的前景。
传统数据集成技术主要关注于架构和相关编程模型的ETL、ELT、CDC和EAI类型。然而,在大数据环境里,这些技术需要根据规模和处理复杂度等需求进行修改,其中包括需要处理的数据格式。实现大数据处理需要两个步骤。第一步是实现数据驱动的架构,其中包括数据处理的分析和设计。第二步是物理架构实现,我们将在下面的章节介绍这个步骤。
数据驱动的集成
在建造下一代数据仓库的技术方法中,企业中所有数据首先会根据数据类型进行分类,也会考虑到数据本身的性质及其相关的处理需求。数据处理过程将会用到内置在处理逻辑中并且整合到一系列编程流程中的业务规则,数据处理会使用到企业元数据、MDM和语义技术(分词技术)等。
图10.3显示了各类数据的入口数据处理过程。这个模型首先基于数据的格式和结构划分数据类型,然后再进行ETL、ELT、CDC或文本处理技术中各个层次的规则处理。下面,让我们来分析一下数据集成架构及其优点。
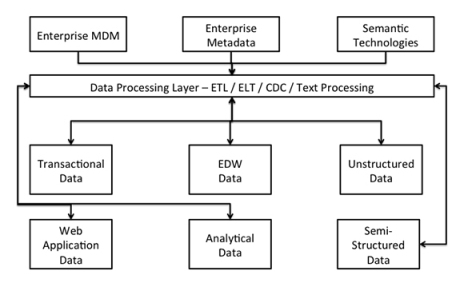
图10.3
数据分类
如图10.3所示,数据可以粗略地划分为以下分类:
- 事务处理数据。比如典型的OLTP数据。
- Web应用数据。比如组织开发的Web应用所产生的数据。这些数据包括点击流数据、Web销售数据及客户关系和呼叫中心通话数据。
- EDW数据。这是来自组织当前所用数据仓库的现有数据。它可能包括组织中各种不同的数据仓库和数据集市,它们存储和处理着供业务用户使用的数据。
- 分析数据。这些数据来自于目前组织部署的分析系统。现在这些数据主要基于EDW或事务数据。
非结构化数据。这个大分类包括:
- 文本:文档、笔记、记事和通讯录
- 图像:照片、图表和图形
- 视频:与组织相关的企业和客户视频
- 社交媒体:Facebook、Twitter、Instagram、LinkedIn、论坛、YouTube和社区网站
- 音频:呼叫中心通话、广播
- 传感器数据:包括来自营业范围相关的各种设备的传感器数据。例如,能源公司会产生智能测量仪表数据,而物流与配送供应商(UPS和FedEx)产生的是卡车和汽车传感器数据。
- 天气数据:现代B2B和B2C公司用天气数据分析天气对业务的影响;它已经成为预测分析的重要元素。
- 科学数据:应用于医学、制药、保险、医疗和金融服务,这些领域都需要复杂的数据计算能力,其中包括模拟和生成模型。
- 股市数据:许多组织用它处理金融数据,预测市场趋势、金融风险和进行精算计算。
半结构化数据。其中包括电子邮件、演示文稿、数学模型、图形和地理数据。
架构
在确定和整理好不同的数据类型之后,就可以清晰确定各种数据特征——包括数据类型、关联的元数据、可以标识为主数据元素的重要数据元素、数据复杂度及拥有和管理数据的业务用户。
工作负载
处理大数据的最大需求是前面章节所介绍的工作负载管理。
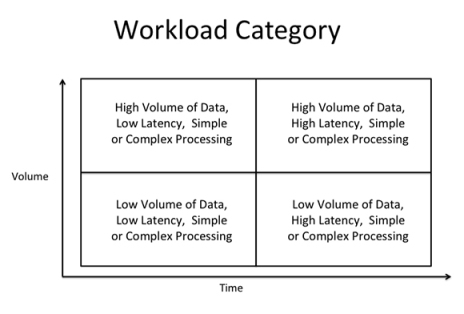
有了数据架构和分类,我们就可以分配可以执行该类数据工作负载需求的基础架构。
我们可以根据数据容量和数据延迟时间将工作负载大体分成4类(图10.4)。然后,我们再根据类别将数据分配到物理基础架构层进行处理。该管理方法可以为数据仓库的各个部分创建一种动态可扩展需求,它们可以高效利用当前及未来的新基础方法。在这个时候,一定要注意的关键问题是要保持处理逻辑的灵活性,使它能够在不同的物理基础架构组件上发挥作用,因为数据是根据处理紧迫性进行分类的,这样相同的数据就可能会被归类到不同的工作负载上。
工作负载架构将进一步决定混合工作负载管理的条件,来自不同工作负载的数据会一同处理。
例如,通常我们只需要在一个环境中处理一种数据及其负载,如果将高容量低延迟数据和低容量高延迟数据放在一起处理,数据处理环境就会面临多样化压力。同时发生或高频的用户查询和数据加载会进一步加大数据处理的复杂性,情况可能会很快失去控制,然后影响整体性能。如果一个基础架构同时处理大数据和传统数据,再加上这些复杂性,那么问题会更加严重。
划分工作负载的目标是确定数据处理的复杂性,以及如何降低下一代数据仓库的基础架构设计的风险。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
翻译
TechTarget中国特约技术编辑,某高校计算机科学专业教师和网络实验室负责人,曾任职某网络国际厂商,关注数据中心、开发运维、数据库及软件开发技术。有多本关于思科数据中心和虚拟化技术的译著,如《思科绿色数据中心建设与管理》和《基于IP的能源管理》等。
相关推荐
-
超越RDBMS:数据仓库与数据湖、数据集市
现在企业从各种来源收集的大量数据已经远远超出传统关系学数据库可处理的范畴。这引发数据仓库与数据湖的问题:何时使 […]
-
对SAP HANA数据库涉嫌知识产权盗窃的指控存疑
Enterprise Applications Consultin公司负责人Joshua Greenbaum表 […]
-
数据货币将决定企业成败
在2017年3月McKinsey公司对500多名高管的调查显示,越来越多的企业使用数据和分析来推动增长,但目前 […]
-
在HANA上实施SAP BW要做哪些准备?
在HANA上实施SAP BW可以帮助公司利用到HANA的速度和性能优势。不过,CIO及技术团队首先要注意一些关键问题。