
导读:
2012年5月12日,MySQL技术群-北京技术圈的MySQL爱好者,聚集搜狐公司,举办MySQL数据库技术沙龙,本文内容为搜狐DBA团队古雷(外号:古大师,因研究佛学而来)分享的MySQL之SQL执行过程,先整理成文章的方式供大家阅读,古大师也是mysqlops中文网的技术编辑之一。
序言:
不积跬步,无以至千里;不积小流,无以成江海——《劝学》荀子
吾生也有涯,而知也无涯。以有涯随无涯,殆已——《养生主》庄子
Group by
| select name1 from test group by name1; |
从InnoDB存储引擎表读出一条记录,写入临时表,循环往复
临时表中,group by的key(本例中为name1)
- 每个KEY值只有一行记录
- (相同KEY值写入,检测到重复键错误,忽略此错误并继续)
从临时表中读取记录(全部或KEY)
排序(filesort)
发送排序结果
Group by + sum
| select sum(id) from test group by name1; |
从InnoDB存储引擎表读取一条记录,写入临时表,循环往复
临时表中group by的key(本例中为name1)
- 有一个hash索引
- 每个KEY值只有一行记录
- 写入临时表每行记录时,更新相同KEY的sum值
以group by的key对临时表排序(filesort)
发送排序结果
If you use GROUP BY, output rows are sorted according to the GROUP BY columns as if you had an ORDER BY for the same columns. To avoid the overhead of sorting that GROUP BY produces, add ORDER BY NULL
临时表写入的痕迹1

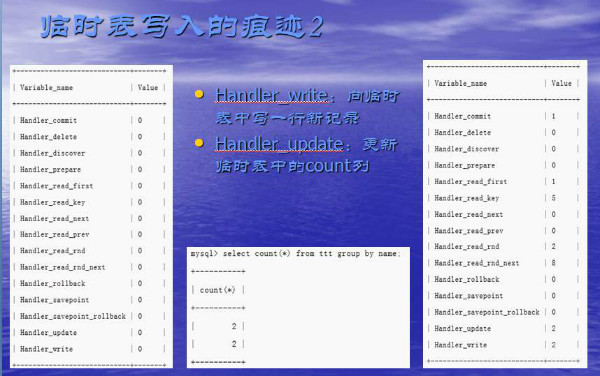
group by使用索引时,不需要临时表
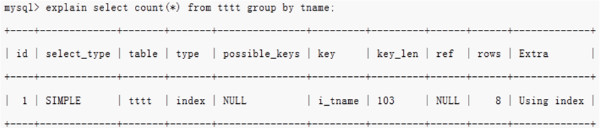
从索引中读取记录,计算count,由于索引是按照group by的key排序的,因此可以边读记录边计算当前key的count,当读的key值要变化时,则刚刚计算的count值就是那个key的最终count值,把结果发送给客户端,再继续从索引读以下记录。
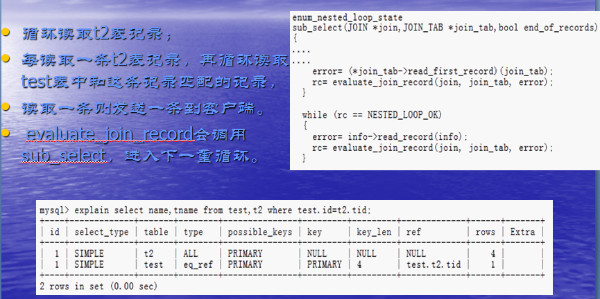
什么是Nested Loop Join(嵌套循环算法)
DEPENDENT SUBQUERY
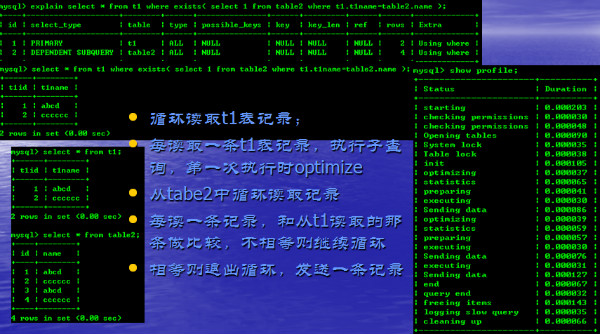
DERIVED(派生表)
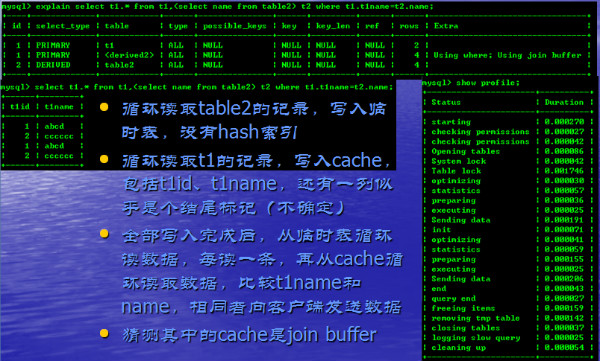
两表JOIN + ORDER BY

循环读取ttt表的记录,写入cache,直至都写完
循环从tttt表中读取记录
每读一条,再循环读取cache中记录,并做比较
满足条件的记录写入临时表
对临时表排序
发送结果

Using join buffer是循环读取big表并与join buffer中的保存的table2记录比较
Using temporary是保存匹配的记录,然后需要排序
总结
之前看手册上的诸多概念,有空中楼阁的感觉
通过跟踪源码,则逐渐有脚踏实地的感觉
希望真正看懂explain的输出
不积跬步,无以至千里;不积小流,无以成江海——《劝学》荀子
吾生也有涯,而知也无涯。以有涯随无涯,殆已——《养生主》庄子
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
OpenWorld18大会:Ellison宣布数据库的搜寻和破坏任务
在旧金山举行的甲骨文OpenWorld 2018大会中,甲骨文首席技术官(CTO)兼创始人Larry Elli […]
-
ObjectRocket着力发展Azure MongoDB服务
MongoDB吸引了微软公司的注意力,微软公司计划针对运行于该公司2017年发布的Azure Cosmos D […]
-
Notre Dame对云端SQL Server性能基准的探索实践
确立SQL Server的性能基准,对于云端迁移来说是至关重要的第一步,一位来自于University of Notre Dame 的DBA表示,他正在试图通过数据库监控软件,找出SQL server的性能基准。
-
DBA必须掌握的数据库恢复管理技术
如果没有备份副本,数据库管理员就无法还原数据库,所以DBA在恢复之前倾向于考虑备份是合乎逻辑的。 但是,对我来说,这种逻辑一直是错误的。