
基本概念
- 锁的基本类型
A. 共享锁(Shared Lock)也叫读锁
B. 排他锁(Exclusive Lock)也叫写锁
- S、X锁的兼容性矩阵
| S X S + – X – – + 代表兼容, -代表不兼容 |
- 锁的粒度
A. 表锁(Table Lock)
B. 行锁(Row Lock)
- 意向锁(Intention Lock)
因为表锁覆盖了行锁的数据,所以表锁和行锁也会产生冲突。如:
A. trx1 BEGIN
B. trx1 给 T1 加X锁,修改表结构
C. trx2 BEGIN
D. trx2 给 T1 的一行记录加S或X锁(事务被阻塞,等待加锁成功)
trx1要操作整个表,锁住了整个表。那么trx2就不能再对T1的单条记录加X或S锁,去读取或修这条记录。
为了方便检测表级锁和行级锁之间的冲突,就引入了意向锁。
A. 意向锁分为意向读锁(IS)和意向写锁(IX)
B. 意向锁是表级锁,但是却表示事务正在读或写某一行记录,而不是整个表
所以意向锁之间不会产生冲突,真正的冲在加行锁时检查。
C. 在给一行记录加锁前,首先要给该表加意向锁。也就是要同时加表意向锁和行锁。
采用了意向锁后,上面的例子就变成了:
| A. trx1 BEGIN B. trx1 给 T1 加X锁,修改表结构 C. trx2 BEGIN D. trx2 给 T1 加IX锁(事务被阻塞,等待加锁成功,然后在给某一行记录加X锁。) |
- 表锁的兼容性矩阵
| IS IX S X IS + + + – IX + + – – S + – + – X – – – – + 代表兼容, -代表不兼容 |
A. 意向锁之间不会冲突, 因为意向锁仅仅代表要对某行记录进行操作。在加行锁时,会判断是否冲突。
行锁
直观的理解,行锁就是要锁住一行记录,阻止其他事务操作该行记录。这里有一个隐含的逻辑:
A. 插入操作永远不会被阻止,因为插入操作不会操作一条存在的记录(这里不考虑Insert
duplicate的处理)。这个逻辑是对的吗? 这和用户的使用情况相关,有些情况下是用户能接受的,有些情况下是用户不能接受的。
- 幻读(Phantom Read)
如果不阻止INSERT操作,就会产生幻读。MySQL手册中有幻读的介绍。
A. MVCC 可以避免幻读。但是MVCC只对SELECT语句有效,对于SELECT … [LOCK IN SHARE MODE | FOR UPDATE], UPDATE, DELETE语句无效。
B. 为了能够通过锁避免幻读,采用了next-key的机制。next-key通过锁住2个记录之间的间隙,来阻止INSERT操作。
- 行锁的模式
行锁S、X锁上做了一些精确的细分,在代码中称作Precise Mode。这些精确的模式,使的锁的粒度更细小。可以减少冲突。
A. 间隙锁(Gap Lock),只锁间隙
B. 记录锁(Record Lock)只锁记录
C. Next-Key Lock(代码中称为Ordinary Lock),同时锁住记录和间隙
D. 插入意图锁(Insert Intention Lock),插入时使用的锁。在代码中,插入意图锁,实际上是GAP锁上加了一个LOCK_INSERT_INTENTION的标记
MySQL手册对这些模式有详细的介绍。
- 行锁模式的兼容性矩阵
| G I R N (已经存在的锁,包括等待的锁) G + + + + I – + + – R + + – – N + + – – + 代表兼容, -代表不兼容。I代表插入意图锁,G代表Gap锁,I代表插入意图锁,R代表记录锁,N代表Next-Key锁。 |
S锁和S锁是完全兼容的,因此在判别兼容性时不需要对比精确模式。
精确模式的检测,用在S、X和X、X之间。
这个矩阵是从lock0lock.c:lock_rec_has_to_wait()的代码推出来的。从这个矩阵可以看到几个特点:
A. INSERT操作之间不会有冲突
B. GAP,Next-Key会阻止Insert
C. GAP和Record,Next-Key不会冲突
D. Record和Record、Next-Key之间相互冲突
E. 已有的Insert锁不阻止任何准备加的锁
同时也有几个疑问:
A. 为什么插入意图锁不阻止间隙锁?在特定的情况下会导致INSERT操作被无限期延迟。

插入操作延迟
B. 如果不阻止任何锁,这个锁还有必要存在吗?
目前看到的作用是,通过加锁的方式来唤醒等待线程。
但这并不意味着,被唤醒后可以直接做插入操作了。需要再次判断是否有锁冲突。
C. GAP+LOCK_INSERT_INTENTION标记的方式,能否直接变成INSERT_INTENTION锁?
目前还在看。
- B+Tree 行锁
InnoDB的行锁并不是简单的数据行锁的概念。而是指每个B+Tree上的行锁,也可以理解为每个
Index上的行锁。因此操作一行记录时,有可能会加多个行锁在不同的B+Tree上。如:
| CREATE TABLE t1(c1 INT KEY, c2 int, c3 int, INDEX(c2)); INSERT INTO t1 VALUES(1, 1, 1), (3, 3, 3) UPDATE t1 c3 = 10 WHERE c2 <= 2 |
UPDATE语句会同时在Secondary Index和Clustered Index上加锁。
- 行锁模式的使用
行锁的这些模式都在什么情况下使用呢?MySQL手册有详细的介绍。
A. Next-Key 使用在被WHERE条件用到的索引上(准确的说是用来做Search的索引上)
上面的例子中,Index(c2)上使用 Next-Key Lock。
B. Record Lock使用在没有被WHERE条件使用的索引上。上面的例子中,簇索引上使用Record
Lock。因此上面的UPDATE语句会同时在加Index(c2)的键1上加Next-Key,在主键1上加record
锁。当另一个session并发插入(2,5,2),(3,5,2)时可以成功,但是(2,2,2)时会被阻塞
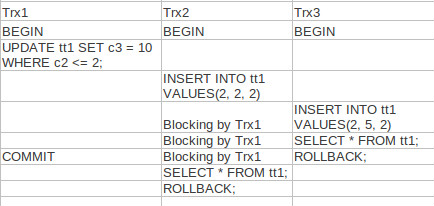
Next-Key And Record
测试时发现,SELECT…[FOR UPDATE |LOCKIN SHARE MODE]可能会导致全部记录被锁住。
当表很小时,SELECT会采用全表扫描的方法。在使用这种方法时,遍历了所有的数据,
因此所有数据都被锁住了。尽管对不符合条件的记录调用了ha_innobase::unlock_row(),
但是在Repeatable Read级别时不会被释放。也许该算一个Bug。
C. A、B同时适用于SELECT…[FOR UPDATE | LOCK IN SHARE MODE], UPDATE、DELETE语句
D. GAP锁显然也是使用在WHERE条件使用的索引上。和Next-Key不同的是,GAP锁只加在上边界(第一个大于符合条件的记录)上。而Next-Key加在所有符合条件的记录上。上面例子中的条件c2=2的记录,需要在c2=3上加一个GAP锁。
? 正向查询时,InnoDB中实际上在边界上加的是Next-Key锁。 这可能是受实现的限制。
目前使用GAP情况有:
Supremum记录上始终是一个GAP锁
反向查询(ORDER BY DESC)时
等值匹配一个确切的键值时,对下一条记录加GAP锁
等值匹配一个确切的键值的前缀时,对下一条记录加GAP锁
E. INSERT时,通常不加锁。只有当其他事务在插入点加了Gap或Next-key锁需要等待时,才会创建一个插入意图锁。这个锁是在waiting状态
- 隔离级别对Next-Key锁的影响
A. Read Uncommitted和Read Committed时,不需要在间隙上加锁,Nexk-Key变成Record锁
B. Repeatable Reads 和 Serializable时,通常情况下使用Next-key锁
有2中情况不需要对间隙加锁:
查询一个唯一的值,如 WHERE c1 = 1, c1 是主键或唯一键,并且查询结果中不含NULL字段。
当innodb_locks_unsafe_for_binlog被开启。这里还是有一些值得思考的问题:
? 从这个情况来看,UPDATE,DELETE时加间隙锁完全是为了防止Master和Slave数据不一致。
那么不使用binlog时就没有必要对DELETE, UPDATE加间隙锁。
? Row Format Binlog时,不加间隙锁是否会引起Master, Slave不一至。
? 即便设置了innodb_locks_unsafe_for_binlog,SELECT…[]是否可以不加间隙锁。
判断加什么锁的主要工作在row0sel.c:row_search_for_mysql()中。
延迟加锁机制
如果一个表有很多的索引,那么操作一个记录时,岂不是要加很多锁到不同的B-Tree上吗?
先来看一个事务的状态信息:
| CREATE TABLE t1(c1 INT KEY, c2 INT); BEGIN; INSERT INTO t1 VALUES(1, 1); INSERT INTO t1 VALUES(2, 2); SHOW ENGINE INNODB STATUS; |
状态信息:
| LIST OF TRANSACTIONS FOR EACH SESSION: —TRANSACTION 501, ACTIVE 0 sec 1 lock struct(s), heap size 376, 0 row lock(s), undo log entries 2 |
- 隐式锁
Lock 是一种悲观的顺序化机制。它假设很可能发生冲突,因此在操作数据时,就加锁。
如果冲突的可能性很小,多数的锁都是不必要的。
Innodb 实现了一个延迟加锁的机制,来减少加锁的数量,在代码中称为隐式锁(Implicit Lock)。
隐式锁中有个重要的元素,事务ID(trx_id)。隐式锁的逻辑过程如下:
A. InnoDB的每条记录中都一个隐含的trx_id字段,这个字段存在于簇索引的B+Tree中
B. 在操作一条记录前,首先根据记录中的trx_id检查该事务是否是活动的事务(未提交或回滚)
如果是活动的事务,首先将隐式锁转换为显式锁(就是为该事务添加一个锁)。
C. 检查是否有锁冲突,如果有冲突,创建锁,并设置为waiting状态。如果没有冲突不加锁,跳到E。
D. 等待加锁成功,被唤醒,或者超时。
E. 写数据,并将自己的trx_id写入trx_id字段。Page Lock可以保证操作的正确性。
相关代码:
| A. lock_rec_convert_impl_to_expl()将隐式锁转换成显示锁。 B. 加锁和测试行锁冲突都用lock_rec_lock(),它的第一个参数表示是否是隐式锁。所以要特别注意这个参数。如果为TRUE,在没有冲突时并不会加锁。 C. 测试行锁的冲突的具体内容在lock_rec_has_wait() D. 创建waiting锁是lock_rec_enqueue_waiting() E. 创建行锁是lock_rec_add_to_queue() |
- 隐式锁的特点
A. 只有在很可能发生冲突时才加锁,减少了锁的数量。
B. 隐式锁是针对被修改的B+Tree记录,因此都是Record类型的锁。不可能是Gap或Next-Key类型。
- 隐式锁的使用
A. INSERT操作只加隐式锁,不需要显示加锁。
B. UPDATE,DELETE在查询时,直接对查询用的Index和主键使用显示锁,其他索引上使用隐式锁。
理论上说,可以对主键使用隐式锁的。提前使用显示锁应该是为了减少死锁的可能性。
INSERT,UPDATE,DELETE对B+Tree们的操作都是从主键的B+Tree开始,因此对主键加锁可以
有效的阻止死锁。
- Secondary Index上的隐式锁
前边说了,trx_id只存在于主键上,那么辅助索引上如何来实现隐式索引呢?
显然是要通过辅助索引中的主键值,在主键B+Tree上进行二次查找。这个开销是很大的。
InnoDB对这个过程有一个优化:
A. 每个页上有一个MAX_TRX_ID,每次修改辅助索引的记录时,都会更新这个最大事务ID。
B. 当判断是否要将隐式锁变为显式锁时,先将页面的max_trx_id和事务列表的最小trx_id
比较。如果max_trx_id比事务列表的最小trx_id还小,那么就不需要转换为显示锁了。
代码在lock_sec_rec_some_has_impl_off_kernel()中
| /* Some transaction may have an implicit x-lock on the record only if the max trx id for the page >= min trx id for the trx list, or database recovery is running. We do not write the changes of a page max trx id to the log, and therefore during recovery, this value for a page may be incorrect. */ |
| if (page_get_max_trx_id(page) < trx_list_get_min_trx_id() && !recv_recovery_is_on()) { return(NULL); } |
锁的实现
- 锁的存放
A. table->locks 存放一个表的所有表级锁。
B. lock_sys->rec_hash存放所有表的行锁。Hash值根据(spaceid, pageno)来计算。
C. trx->trx_locks存放事务的所有锁,包括表级锁和行级锁。一个事务的所有锁,在事务
结束时,一起释放。代码在lock_release_off_kernel().如果有等待的锁可以被授权,
则会将等待的锁,转变为被授权的锁,并唤醒相应的事务。
- 行锁的唯一识别
第一印象想到的是,用每行记录的键值来做行锁的唯一识别。但是键值占用空间比较大。
InnoDB使用Page NO.+Heap NO.来做行锁的唯一识别。我们可以将Heap no.理解为页面上的一个自增数值。每条物理记录在被创建时,都会分配一个唯一的heap no。
A. 键值可以理解为一个逻辑值,page no. + heap no. 是物理的。
B. 物理的虽然占用空间小,但是处理要复杂一些。如:在分裂一个B+Tree页面时,一半的记录要移到新的页面中,因此要对存在的锁进行迁移。
锁移动的d函数有:
| lock_move_reorganize_page(), lock_move_rec_list_start(), lock_move_rec_list_end(). |
在删除和插入数据时,也要进行GAP锁的继承。
| lock_rec_inherit_to_gap() lock_rec_inherit_to_gap_if_gap_lock(). |
- 死锁(Deadlock)
A. 超时机制。当要加的锁和其他锁冲突时,添加一个waiting锁,并且返回DB_LOCK_WAIT错误。
row_mysql_handle_error调用srv_suspend_mysql_thread来挂起一个线程。
B. 死锁检测检测机制。每当创建waiting锁,都要调用lock_deadlock_occurs()进行死锁的检测。
死锁检测方法是Waits-For Graph.在lock_deadlock_recursive()中实现。
当发现死锁后要选择其中的一个事务,将其回滚,来解除死锁。选择哪一个事务回滚能?
如果一个事务修改了non-transactional表(如MyISAM表,修改不能回滚),另一个表没有。则没有修改non-transactional的会被回滚。
如果2个事务都修改了non-transactional表或者都没有。则比较2个事务修改的记录数和加的锁数量。总和小的事务会被回滚。trx_weight_ge()实现这个逻辑。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
OpenWorld18大会:Ellison宣布数据库的搜寻和破坏任务
在旧金山举行的甲骨文OpenWorld 2018大会中,甲骨文首席技术官(CTO)兼创始人Larry Elli […]
-
ObjectRocket着力发展Azure MongoDB服务
MongoDB吸引了微软公司的注意力,微软公司计划针对运行于该公司2017年发布的Azure Cosmos D […]
-
2017年5月数据库流行度排行榜 MySQL与Oracle“势均力敌”
数据库知识网站DB-engines.com最近更新了2017年5月的数据库流行榜单。TechTarget继续与您一起分享最新的榜单情况。
-
2017年3月数据库流行度排行榜 Oracle卫冕之路困难重重
时隔一个月,数据库市场经过一轮“洗牌”,旧的市场格局是否会被打破,曾经占巨大市场份额的企业是否可能失去优势?