
MongoDB 的 PHP 客户端有一个 MongoCursor 类,它是用于获取一次查询结果集的句柄(或者叫游标),这个简单的取数据操作,内部实现其实不是那么简单。本文就通过对 MongoCursor 类一些操作进行分析,向大家揭开 MongoDB 客户端服务器通信的一些内部细节。
getNext与网络请求
通常来说,每一次find操作都会返回一个MongoCursor对象,在这个对象上调用getNext方法,就能够获得一条结果数据。循环调用getNext方法就能获取多条数据。下面我们就来看看其内部取数据的具体逻辑。
首先我们用最简单的方法来生成一个MongoCursor对象:
| $m = new Mongo(); $collection = $m->demoDb->demoCollection; $cursor = $collection->find(); |
当我们调用 find 方法的时候,会生成一个 MongoCursor 对象,而这时候只是生成一个内存中的对象而已,并不会把我们的 find 查询发送到服务端,因为在生成 MongoCursor 对象后,我们还可能对它做一些其它操作,比如 sort,limit 等等。这就对查询条件进行了改变。
那什么时候 PHP 会对 MongoDB 发起 find 的网络请求呢,是在 MongoCursor 调用 getNext 方法的时候。比如我们在上面代码的基础上,再执行 sort 和 getNext 两个方法:
| $cursor->sort( array( ‘name’ => 1 ) ); $result = $cursor->getNext(); |
这时候第二行代码就会触发 find 的网络请求,具体请求的内容如下图,下图是对这次请求的二进制协议进行解析后的数据结构展示:
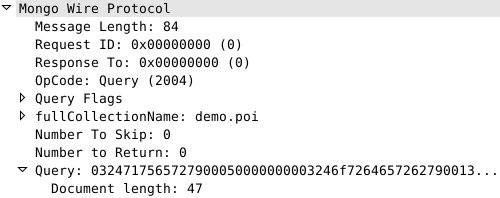
从上面图中我们可以看到,Number to Return 字段是0,MongoDB 协议里0表示不做限制,获取全部数据。所以这一次的 find 操作会把所有这个 collection 中的所有数据都拿到。而我们调用一次 getNext 实际上只拿到一条数据。那是不是说我们每调一次 getNext,PHP 就会进行一次网络请求获取一条数据呢?结果当然是否定的,这样效率未免也太低了。那好,那是不是 PHP 在第一次调用 getNext 就把所有数据拿回来,存在内存中,然后后续的 getNext 调用都在本地内存里取就行了呢?结果还是否定的,这样数据量大点 PHP 就容易被暴菊了吧。
所以事实上是怎么做的呢?我们来看下面一张图:
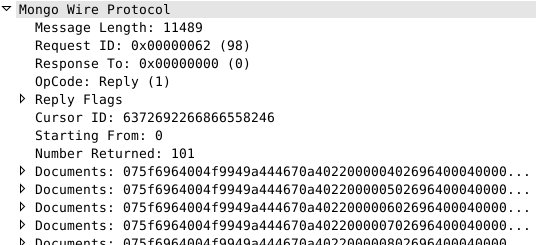
图上的 Number Returned 的值是101,也就是说 MongoDB 给我们返回了101条数据,这个101实际上就是服务器默认的 batchSize 大小。也就是说在没有指定返回多少条的情况下,会默认返回101条数据。这101条数据会存在 PHP 的内存中,这样后续的100次 getNext 调用,都不会再进行网络请求,而是直接从内存中返回数据。
如果我们在上面的 getNext 后再进行下面的调用。
| // skip the other 100 docs for ($i = 0; $i < 100; $i++) { $cursor->getNext(); } // request document 102: $result = $cursor->getNext(); |
上面先循环调用了100次 getNext,内存中的101项数据就都已经被取光了,然后当我们再次调用 getNext 去获取第102条数据的时候,PHP 内存中已经没有数据可以提供了,这时候又会再发起一次向 MongoDB 服务器的请求,去获取更多的数据。客户端这次会发起如下请求:
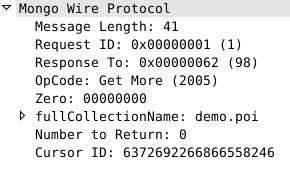
这次我们看到,请求的码变成了 Get More。也就是在上次的基础上获取更多数据。这时候实际 MongoDB 不会再按一个特定的条数返回数据,而是按一个特定的大小,目前是4M,也就是说,这一次,MongoDB 会返回最多4M的数据。对上面的请求,MongoDB 的返回如下:
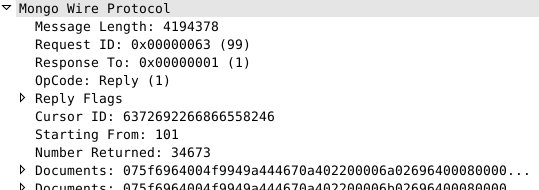
这次返回结果中,标识了是从第101条开始,共返回了34673条数据。大小是4194378,正好是4M。
设置batchSize
上面我们说了,MongoDB 默认的 batchSize 是101条,这个条数实际上我们可以通过客户端来设定的。在 PHP 中,通过 batchSize 函数来进行设置。比如我们用下面命令设定 batchSize 为25:
| $cursor = $collection->find()->sort( array( ‘name’ => 1 ) ); $cursor->batchSize(25); $result = $cursor->getNext(); |
上面代码调用了一次 getNext,按上面讲到的,会一次性批量取N条数据回客户端。上面代码运行时产生的网络请求如下:
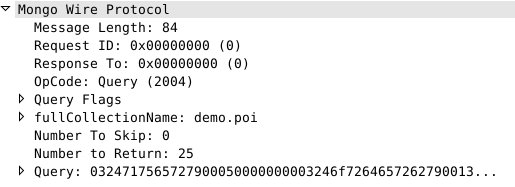
我们可以看到,Number to Return被设置为了25。
如果我们再循环执行getNext函数25次,加上上面代码一共执行26次,那么因为第一次只返回了25条记录,所以第26次调用getNext函数时会再一次触发网络请求。请求体如下:
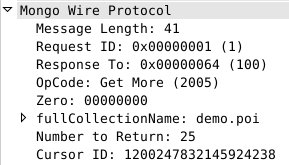
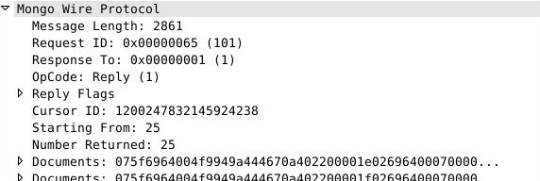
由于我们设定了 batchSize 为25,所以这一次要求返回的也只有25条。服务端返回的数据也就只有25条。
使用limit
除了 batchSize 函数以外,还有一个方法可以控制每次网络请求批量返回的记录条数,那就是在 MongoCursor 上调用 limit 函数,直接设置需要获取的记录条数。
比如下面代码,我们通过设置 limit 查询前50000条记录:
| $cursor = $c->find()->sort( array( ‘name’ => 1 ) ); $cursor->limit( 50000 ); $res = $cursor->getNext(); |
上面代码会发出下面的请求
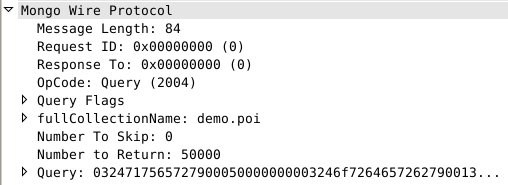
我们看到,要求返回的数目是50000条,那么MongoDB服务器是不是就乖乖返回50000条数据了呢。让我们直接来看一下具体的返回数据包
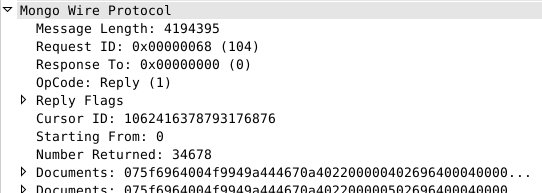
很遗憾,MongoDB 服务端只返回了34678条,而不是我们理想中的50000条,其实原因也很简单,从 Message Length 的值就能看出来,因为目前请求包已经达到4M大小了,这个上限无法逾越。所以只能返回34678条数据了。
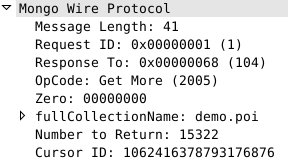
而同时,客户端在收到返回的数据包时,发现只有34678条数据,不够自己要求的50000条,还差 50000 – 34678 = 15322 条,所以会再发起一次请求,要求服务器返回剩余的15322条记录。如下:
batchSize 和 limit 相组合
有时候我们可能会需要取很多条数据,比如上面的,通过设置limit为50000来获取50000条数据,而取这50000条数据的获取可能会超出我们设置的 MongoCursor 的 timeout 限制,抛出 Cursor 超时的异常。这时候我们可以在设置 limit 的同时,设置 batchSize 来控制每两次请求服务器的时间间隔。以免由于获取大量数据导致的 MongoCursor 超时。
比如下面的例子里,我们要获取128条数据,但是通过设置 batchSize 来控制每次只从服务器取回50条。这样在后续的 getNext 调用中,就会发生三次网络请求,分别请求数目是50条,50条,28条。
| $cursor = $c->find()->sort( array( ‘name’ => 1 ) ); $cursor->limit( 128 )->batchSize( 50 ); $res = $cursor->getNext(); // retrieve the other 127 documents that we still want for ($i = 0; $i < 127; $i++) { $cursor->getNext(); } |
关于 batchSize 函数的小问题
上面我们说了通过设置 batchSiz e来控制客户端与 MongoDB 服务器的数据交换。但是这里有一个特例,当 batchSize 被设置为1,或者是负数时,MongoDB 只会返回第一次请求的数据包,然后直接关闭掉这个连接。也就是说,如果我们执行下面的命令:
| $cursor = $c->find()->sort( array( ‘name’ => 1 ) ); $cursor->batchSize( 1 )->limit( 10 ); $cursor->getNext(); var_dump( $cursor->getNext() ); |
会发现最后一个 var_dump 打出来的总是 NULL。因为每一次按 batchSize 的设置只返回了1条数据,然后连接就关闭了。
而我们只需要稍做修改,将 batchSize 改成2,情况就大为不同
| $cursor = $c->find()->sort( array( ‘name’ => 1 ) ); $cursor->batchSize( 2 )->limit( 10 ); $cursor->getNext(); // item 1 $cursor->getNext(); // item 2 var_dump( $cursor->getNext() ); // item 3 |
可以看到,虽然第一次网络返回包被设置只返回两条数据,但是每三次调 getNext 时还是返回数据了,也就是说还是从服务器第二次获取到数据了。
实际上,通过上面的实验结果,我们已经大致对 MongoDB 客户端服务器通信协议有了大致的了解,更详细的内容我们可以直接在 MongoDB 官方文档中找到(Mongo Wire Protocal)。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
MongoDB与Cassandra数据库对比
MongoDB和Cassandra都属于NoSQL数据库系列,它们也恰好都是开源,但是,它们的相似之处仅此而已 […]
-
eHarmony公司利用Redis NoSQL数据库进行热存储
虽然关系型数据库不会消失,但关系型数据库管理系统有时仅在会话管理、推荐引擎和模式匹配等关键Web应用程序中担当 […]
-
2017年5月数据库流行度排行榜 MySQL与Oracle“势均力敌”
数据库知识网站DB-engines.com最近更新了2017年5月的数据库流行榜单。TechTarget继续与您一起分享最新的榜单情况。
-
2017年3月数据库流行度排行榜 Oracle卫冕之路困难重重
时隔一个月,数据库市场经过一轮“洗牌”,旧的市场格局是否会被打破,曾经占巨大市场份额的企业是否可能失去优势?