
题目其实并不太准确,因为数据库并不会提供分页、排名等功能,提供的只是数据的存取,分页排名这些都是我们基于数据库的实用案例而已。然而无论是Redis还是MongoDB,通常都有一些常规的做分页和排名的方法。本文就通过一些测试数据来向大家介绍Redis和MongoDB(以及传统关系型数据库)在这方面的性能差别。
分页
首先我们来做一个分页,在MongoDB中示例数据如下所未:
| db.scores.find(); {lid: ObjectId(“4fe506dabb2bfa742d000001”), score: 1, name: ‘user_1’} {lid: ObjectId(“4fe506dabb2bfa742d000001”), score: 2, name: ‘user_2’} {lid: ObjectId(“4fe506dabb2bfa742d000001”), score: 3, name: ‘user_3’} {lid: ObjectId(“4fe506dabb2bfa742d000001”), score: 4, name: ‘user_4’} |
其中lid字段用于区分不同的纬度,主要用在筛选上,在测试collection中,一共有五个不同的lid值,每一个对应1,200,000条数据,一共6,000,000条数据。索引在lid 和 score上。(下面的查询能使用到索引)
然后我们进行下面的性能测试:
| collection = Mongo::Connection.new.db(‘test’).collection(‘scores’) Benchmark.bmbm do |x| x.report(“mongo small”) do 100.times do |i| collection.find({:lid => lids.sample}, {:fields => {:_id => false, :score => true, :user => true}}).sort({:score => -1}).limit(20).skip(i * 20).to_a end end x.report(“mongo medium”) do 100.times do |i| collection.find({:lid => lids.sample}, {:fields => {:_id => false, :score => true, :user => true}}).sort({:score => -1}).limit(20).skip(i * 1000).to_a end end x.report(“mongo large”) do 100.times do |i| collection.find({:lid => lids.sample}, {:fields => {:_id => false, :score => true, :user => true}}).sort({:score => -1}).limit(20).skip(i * 10000).to_a end end end |
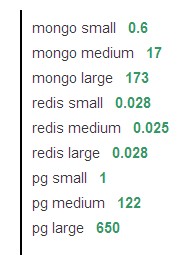
上面分别对skip条数比较小,中等大小和非常大三种情况进行了测试。而limit指定获取的数据都一样是20条。这三种情况下的测试结果分别是:0.6 秒, 17 秒,173 秒。
我们可以看到,对MongoDB来说,skip的大小严重影响性能,应该严格避免特别大的skip操作。
下面我们将类似的数据用Redis的Sorted Sets进行存储。并进行相应的性能测试
| redis = Redis.new(:driver => :hiredis) Benchmark.bmbm do |x| x.report(“redis small”) do 100.times do |i| start = i * 20 redis.zrevrange(lids.sample, start, start + 20, :with_scores => true) end end x.report(“redis medium”) do 100.times do |i| start = i * 1000 redis.zrevrange(lids.sample, start, start + 20, :with_scores => true) end end x.report(“redis large”) do 100.times do |i| start = i * 10000 redis.zrevrange(lids.sample, start, start + 20, :with_scores => true) end end |
这里skip的值和上面MongoDB中是一样的,那么Redis的表现如何呢。这三种情况下的测试结果分别是:0.028 秒, 0.025 秒, 0.028 秒。
采用类似于MongoDB的数据结构存储在PostgreSQL中并进行相同的测试,其结果比MongoDB还要差一点。具体结果如下:
排名
排名功能与分页功能类似,不同的是排名是通过计算大于某个值的条数来做的。
比如:
| //sql select count(*) from scores where lid = $1 and score > $2 //mongo db.scores.find({lid: lid, score: {$gt: score}}).count() |
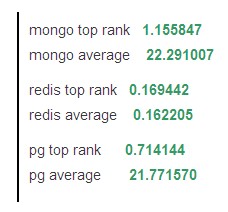
由于排名和分页实现原理上类似,所以结果实际上差不多。测试结果如下:
结论
上面做了对比,那么本文要说一个什么问题呢?
首先,在MongoDB中,尽量避免进行比较大的skip操作,比如在分页中,如果你能知道需要获取数据的上一条score是多少,那么可能能够用下面的方法来获取你要的数据,而不是通过一次很大的skip操作。
| db.scores.find({lid: lid, score: {$lt: last_score}}).sort({score: -1}).limit(20) |
另外,如果你需要进行比较大的skip操作或者count比较大的数量,那么可以考虑采用Redis的Sorted Sets来做。
后记
本文在微博上引起了一些技术朋友的讨论,对于对比的问题这里做一个说明。
我们知道,Redis是内存数据库,而MongoDB不是,所以有朋友质疑这里的对比是否只是内存与磁盘的对比。实际上这一说法不无道理,上面的测试数据出自原作者文章,其文章也并未提及MongoDB是否都在内存中。根据我个人的实验结果,当数据全部能够在内存中时,确实不会出现如本文中所说的MongoDB性能严重差异。但是,随着skip的变大,操作时间还是在显著变长,而Redis的Sorted Sets则相对稳定。
同时也欢迎更多实验对比数据和原理分析的讨论。感谢大家。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
MongoDB与Cassandra数据库对比
MongoDB和Cassandra都属于NoSQL数据库系列,它们也恰好都是开源,但是,它们的相似之处仅此而已 […]
-
eHarmony公司利用Redis NoSQL数据库进行热存储
虽然关系型数据库不会消失,但关系型数据库管理系统有时仅在会话管理、推荐引擎和模式匹配等关键Web应用程序中担当 […]
-
2017年1月数据库流行度排行榜 新年新气象
新年新气象,数据库知识网站DB-engines最近更新了2017年1月份数据库流行度榜单。TechTarget数据库网站将与您分享1月份的榜单排名情况,让我们拭目以待。
-
2016年12月数据库流行度排行榜 几家欢乐几家愁
在过去的6个月中,数据库排行榜的前二十名总体上没有太大的变动,那么数据库知识网站DB-engines最近更新的2016年12月份数据库流行度排名情况是否一如既往的沉寂、低调呢?