
sds(Simple Dynamic Strings)是 Redis中最基本的底层数据结构, 它既是 Redis 的 String 类型的底层实现, 也是实现 Hash 、 List 和 Set 等复合类型的基石。
除此之外,sds 还是 Redis 内部实现所使用的字符串类型, 经过 robj 结构包装之后的 sds 被广泛用于 Redis 自身的构建当中: 比如用作 KEY 、作为函数参数、保存 Redis 命令和用作命令的回复(reply),等等。
本文通过分析源码文件 sds.c 和 sds.h ,了解 sds 数据结构的实现,籍此加深对 Redis 的理解。
数据类型定义
与 sds 实现有关的数据类型有两个,一个是 sds :
| // 字符串类型的别名 typedef char *sds; |
另一个是 sdshdr :
| // 持有 sds 的结构 struct sdshdr { // buf 中已被使用的字符串空间数量 int len; // buf 中预留字符串空间数量 int free; // 实际储存字符串的地方 char buf[]; }; |
其中, sds 只是字符数组类型 char* 的别名, 而 sdshdr 则用于持有和保存 sds 的信息。
比如 sdshdr.len 可以用于在 O(1) 复杂度下获取 sdshdr.buf 中储存的字符串的实际长度,而sdshdr.free 则用于保存 sdshdr.buf 中还有多少预留空间。
(虽然文档和源码中都没有说明,但 sdshdr 应该是 sds handler 的缩写。)
将 sdshdr 用作 sds
Sds 模块对 sdshdr 结构使用了一点小技巧(trick):通过指针运算,它使得 sdshdr 结构可以像sds 类型一样被传值和处理,并在需要的时候恢复成 sdshdr 类型。
理解这一小技巧的方法就是看以下一组函数的定义和它们的代码示例。
sdsnewlen 函数返回一个新的 sds 值,实际上,它创建的却是一个 sdshdr 结构:
| // 根据给定初始化值和初始化长度 // 创建或重分配一个 sds sds sdsnewlen(const void *init, size_t initlen) { struct sdshdr *sh; if (init) { // 创建 sh = zmalloc(sizeof(struct sdshdr)+initlen+1); } else { // 重分配 sh = zcalloc(sizeof(struct sdshdr)+initlen+1); } if (sh == NULL) return NULL; sh->len = initlen; sh->free = 0; // 刚开始时 free 为 0 // 设置字符串值 if (initlen && init) memcpy(sh->buf, init, initlen); sh->buf[initlen] = ‘�’; // 只返回 sh->buf 这个字符串部分 return (char*)sh->buf; } |
通过使用变量持有一个 sds 值,在遇到那些只处理 sds 值本身的函数时,可以直接将 sds 传给它们。比如说, sdstoupper 函数就是其中的一个例子:
| sds s = sdsnewlen(“hello moto”, 10); sdstolower(s); // 现在 s 的值应该是 “HELLO MOTO” |
sdstoupper 函数将字符串内的字符全部转换为大写:
| void sdstoupper(sds s) { int len = sdslen(s), j; for (j = 0; j < len; j++) s[j] = toupper(s[j]); } |
但是,有时候,我们不仅需要处理 sds 值本身 (也即是 sdshdr.buf 属性),还需要对 sdshdr中其他属性,比如 sdshdr.len 和 sdshdr.free 进行处理。
使用指针运算,可以从 sds 值中计算出相应的 sdshdr 结构:
| // s 是一个 sds 值 struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr))); |
s – (sizeof(struct sdshdr)) 表示将指针向前移动到 struct sdshdr 的起点,从而得出一个指向 sdshdr 结构的指针:
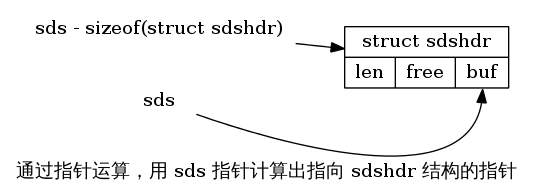
sdslen 函数是使用这种技巧的其中一个例子:
| // 返回字符串内容的实际长度 static inline size_t sdslen(const sds s) { // 从 sds 中计算出相应的 sdshdr 结构 struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr))); return sh->len; } |
函数实现
Sds 模块中的大部分函数都是对常见字符串处理函数的重新实现或包装,这些函数的实现都非常直观,这里就不一一详细介绍了,需要了解实现细节的话,可以直接看带注释的源码。
唯一一个需要提及的,和 Redis 的实现决策相关的函数是 sdsMakeRoomFor :
| /* Enlarge the free space at the end of the sds string so that the caller * is sure that after calling this function can overwrite up to addlen * bytes after the end of the string, plus one more byte for nul term. * * Note: this does not change the *size* of the sds string as returned * by sdslen(), but only the free buffer space we have. */ // 扩展 sds 的预留空间, 确保在调用这个函数之后, // sds 字符串后的 addlen + 1 bytes(for NULL) 可写 sds sdsMakeRoomFor(sds s, size_t addlen) { struct sdshdr *sh, *newsh; size_t free = sdsavail(s); size_t len, newlen; // 预留空间可以满足本次拼接 if (free >= addlen) return s; len = sdslen(s); sh = (void*) (s-(sizeof(struct sdshdr))); // 设置新 sds 的字符串长度 // 这个长度比完成本次拼接实际所需的长度要大 // 通过预留空间优化下次拼接操作 newlen = (len+addlen); if (newlen < SDS_MAX_PREALLOC) newlen *= 2; else newlen += SDS_MAX_PREALLOC; // 重分配 sdshdr newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1); if (newsh == NULL) return NULL; newsh->free = newlen – len; // 只返回字符串部分 return newsh->buf; } |
从 newlen 变量的设置可以看出,如果 newlen 小于 SDS_MAX_PREALLOC ,那么 newlen 的实际值会比所需的长度多出一倍;如果 newlen 的值大于 SDS_MAX_PREALLOC ,那么 newlen 的实际值会加上 SDS_MAX_PREALLOC (目前 2.9.7 版本的 SDS_MAX_PREALLOC 默认值为 1024 * 1024)。
这种内存分配策略表明, 在对 sds 值进行扩展(expand)时,总会预留额外的空间,通过花费更多的内存,减少了对内存进行重分配(reallocate)的次数,并优化下次扩展操作的处理速度。
优化扩展操作的一个例子就是 APPEND 命令: APPEND 命令在执行时会调用 sdsMakeRoomFor ,多预留一部分空间。当下次再执行 APPEND 的时候,如果要拼接的字符串长度 addlen 不超过sdshdr.free (上次 APPEND 时预留的空间),那么就可以略过内存重分配操作,直接进行字符串拼接操作。
相反,如果不使用这种策略,那么每次进行 APPEND 都要对内存进行重分配。
注意,初次创建 sds 值时并不会预留多余的空间(查看前面给出的 sdsnewlen 定义),只有在调用 sdsMakeRoomFor 起码一次之后, sds 才会有预留空间,而且 sds 模块中也有相应的紧缩空间函数 sdsRemoveFreeSpace 。因此,Redis 对 sds 值的这种扩展策略实际上不会浪费多少内存,但它对一些需要多次执行字符串拼接的 Redis 模式来说,却会获得不错的优化效果(因为频繁的内存重分配是一种比较昂贵的工作)。
结语
以上就是本篇文章的全部内容了,文章首先介绍了 sds 类型和 sdshdr 结构,接着说明 Redis 是如何通过指针运算,从而将 sdshdr 当作 sds 来处理的,最后介绍了 Redis 的 sds 重分配策略是如何优化字符串拼接操作的。
如果对 sds.h 和 sds.c 源码的全部细节感兴趣,可以在 github 查看带有详细注释的源码:https://github.com/huangz1990/reading_redis_source 。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
OpenWorld18大会:Ellison宣布数据库的搜寻和破坏任务
在旧金山举行的甲骨文OpenWorld 2018大会中,甲骨文首席技术官(CTO)兼创始人Larry Elli […]
-
ObjectRocket着力发展Azure MongoDB服务
MongoDB吸引了微软公司的注意力,微软公司计划针对运行于该公司2017年发布的Azure Cosmos D […]
-
2017年1月数据库流行度排行榜 新年新气象
新年新气象,数据库知识网站DB-engines最近更新了2017年1月份数据库流行度榜单。TechTarget数据库网站将与您分享1月份的榜单排名情况,让我们拭目以待。
-
创建NoSQL数据建模符号 企业架构师亲自上阵
新兴的NoSQL数据风格促使创新的应用程序快速发展,但NoSQL同时也带来了挑战。NoSQL系统能够快速投入生产,有时甚至根本不用创建任何的前期模式。