
Spanner是Google最近公开的新一代分布式数据库,它既具有NoSQL系统的可扩展性,也具有关系数据库的功能。例如,它支持类似SQL的查询语言、支持表连接、支持事务(包括分布式事务)。Spanner可以将一份数据复制到全球范围的多个数据中心,并保证数据的一致性。一套 Spanner集群可以扩展到上百个数据中心、百万台服务器和上T条数据库记录的规模。目前,Google广告业务的后台(F1)已从MySQL分库分表 方案迁移到了Spanner上。
数据模型
传统的 RDBMS(例如MySQL)采用关系模型,有丰富的功能,支持SQL查询语句。而NoSQL数据库多是在key-value存储之上增加有限的功能,如 列索引、范围查询等,但具有良好的可扩展性。Spanner继承了Megastore的设计,数据模型介于RDBMS和NoSQL之间,提供树形、层次化 的数据库schema,一方面支持类SQL的查询语言,提供表连接等关系数据库的特性,功能上类似于RDBMS;另一方面整个数据库中的所有记录都存储在 同一个key-value大表中,实现上类似于BigTable,具有NoSQL系统的可扩展性。
在Spanner中,应用可以在一个数据库里创建多个表,同时需要指定这些表之间的层次关系。例如,图1中创建的两个表——用户表(Users)和相册表(Albums),并且指定用户表是相册 表的父节点。父节点和子节点间存在着一对多的关系,用户表中的一条记录(一个用户)对应着相册表中的多条记录(多个相册)。此外,要求子节点的主键必须以 父节点的主键作为前缀。例如,用户表的主键(用户ID)就是相册表主键(用户ID+相册ID)的前缀。

图1 schema示例,表之间的层次关系,记录排序后交错的存储(点击放大)
显然所有表的主键都将根节点的主键作为前缀,Spanner将根节点表中的一条记录,和以其主键作为前缀的其他表中的所有记录的集合称作一个 Directory。例如,一个用户的记录及该用户所有相册的记录组成了一个Directory。Directory是Spanner中对数据进行分区、 复制和迁移的基本单位,应用可以指定一个Directory有多少个副本,分别存放在哪些机房中,例如把用户的Directory存放在这个用户所在地区 附近的几个机房中。
这样的数据模型具有以下好处。
- 一个Directory中所有记录的主键都具有相同前缀。在存储到底层key-value大表时,会被分配到相邻的位置。如果数据量不是非常大,会位于同一个节点上,这不仅提高了数据访问的局部性,也保证了在一个Directory中发生的事务都是单机的。
- Directory还实现了从细粒度上对数据进行分区。整个数据库被划分为百万个甚至更多个Directory,每个Directory可以定义自己的复 制策略。这种Directory-based的数据分区方式比MySQL分库分表时Table-based的粒度要细,而比Yahoo!的PNUTS系统 中Row-based的粒度要粗。
- Directory提供了高效的表连接运算方式。在一个Directory中,多张表上的记录按主键排序,交错(interleaved)地存储在一起,因此进行表连接运算时无需排序即可在表间直接进行归并。
复制和一致性
Spanner使用Paxos协议在多个副本间同步redo日志,从而保证数据在多个副本上是一致的。Google的工程师钟情于Paxos协议,Chubby、Megastore和Spanner等一系列产品都是在Paxos协议的基础上实现一致性的。
Paxos 的基本协议很简单。协议中有三个角色:Proposer、Acceptor和Learner,Learner和Proposer分别是读者和写 者,Acceptor相当于存储节点。整个协议描述的是,当系统中有多个Proposer和Acceptor时,每次Proposer写一个变量就会启动 一轮决议过程(Paxos instance),如图2所示。决议过程可以保证即使多个Proposer同时写,结果也不会在Acceptor节点上不一致。确切地说,一旦某个 Proposer提交的值被大多数Acceptor接受,那么这个值就被选中,在整轮决议的过程中该变量就不会再被修改为其他值。如果另一个 Proposer要写入其他值,必须启动下一轮决议过程,而决议过程之间是串行(serializable)的。
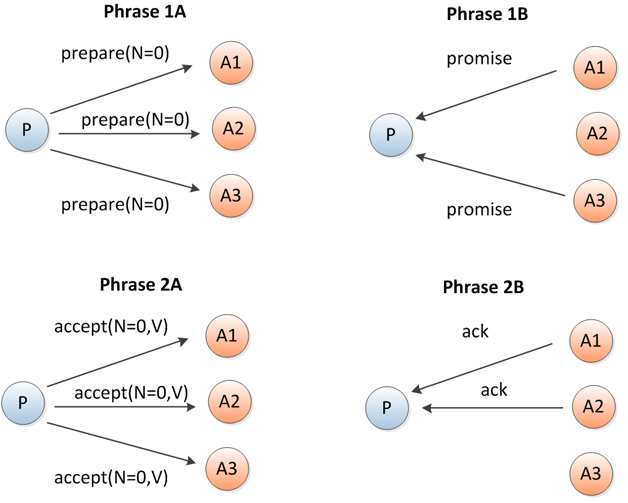
图2 Paxos协议正常执行流程(点击放大)
一轮决议过程分为两个阶段,即prepare阶段和accept阶段。
- 第一阶段A:Proposer向所有Acceptor节点广播prepare消息,消息中只包含一个序号——N。Proposer需要保证这个序号在这轮 决议过程中是全局唯一的(这很容易做到,假如系统中有两个Proposer,那么一个Proposer使用1,3,5,7,9,……,另一个 Proposer则使用0,2,4,6,8,……)。
- 第一阶段B:Acceptor接收到prepare消息后,如果N是到目前为止见过的最大序号,就返回一个promise消息,承诺不会接受序号小于N的请求;如果已接受过其他Proposer提交的值,则会将这个值连同提交这个值的请求的序号一同返回。
- 第二阶段A:当Proposer从大多数Acceptor节点收到了promise消息后,就可以选择接下来要向Acceptor提交的值了。一般情况 下,当然选原本打算写入的值,但如果从收到的promise消息中发现已经有其他值被Acceptor接受了,那么为了避免造成数据不一致的风险,这时 Proposer就必须“大义灭亲”,放弃自己打算写入的值,从其他Proposer提交的序号中选择一个最大的值。接下来Proposer向所有的 Acceptor节点发送accept包,其中包含在第一阶段中挑选的序号N和刚才选择的值V。
- 第二阶段B:Acceptor收到accept包之后,如果N的大小不违反对其他Proposer的承诺,就接受这个请求,记录下值V和序号N,返回一个ack消息。反之,则返回一个reject消息。
如果Proposer从大多数Acceptor节点收到了ack消息,说明写操作成功。而如果在写操作过程中失败,Proposer可以增大序号,重新执行第一阶段。
基本的Paxos协议可以保证值一旦被选出后就一定不会改变,但不能保证一定会选出值来。换句话说,这个投票算法不一定收敛。有两个方法可以加速收敛的过 程:一个是在出现冲突后通过随机延迟把机会让给其他Proposer,另一个是尽量让系统中只有一个Proposer去提交。在Chubby和 Spanner系统中这两种方法都用上了,先用随机延迟的方法通过一轮Paxos协议,在多个Proposer中选举出一个leader节点。接下来所有 的写操作都通过这个leader节点,而leader节点一般还是比较“长寿”的,在广域网环境下平均“任期”可以达到一天以上。而Megastore系 统中没有很好地解决这个问题,所有的Proposer都可以发起写操作,这是Megastore写入性能不高的原因之一。
基本的Paxos 协议还存在性能上的问题,一轮决议过程通常需要进行两个回合通信,而一次跨机房通信的代价为几十到一百毫秒不等,因此两个回合的通信就有点开销过高了。不 过幸运的是,绝大多数情况下,Paxos协议可以优化到仅需一个回合通信。决议过程的第一阶段是不需要指定值的,因此可以把 prepare/promise的过程捎带在上一轮决议中完成,或者更进一步,在执行一轮决议的过程中隐式地涵盖接下来一轮或者几轮决议的第一阶段。这 样,当一轮决议完成之后,其他决议的第一阶段也已经完成了。如此看来,只要leader不发生更替,Paxos协议就可以在一个回合内完成。为了支持实际 的业务,Paxos协议还需要支持并发,多轮决议过程可以并发执行,而代价是故障恢复会更加复杂。
因为leader节点上有最新的数据,而 在其他节点上为了获取最新的数据来执行Paxos协议的第一阶段,需要一个回合的通信代价。因此,Chubby中的读写操作,以及Spanner中的读写 事务都仅在leader节点上执行。而为了提高读操作的性能,减轻leader节点的负载,Spanner还提供了只读事务和本地读。只读事务只在 leader节点上获取时间戳信息,再用这个时间戳在其他节点上执行读操作;而本地读则读取节点上最新版本的数据。
与Chubby、 Spanner这种读写以leader节点为中心的设计相比,Megastore体现了一定的“去中心化”设计。每个客户端都可以发起Paxos写操作, 而读操作则尽可能在本地执行。如果客户端发现本地数据不是最新的,会启动catchup流程更新数据,再执行本地读操作返回给客户端。
最后,对比下其他系统中replication的实现。在BigTable系统中每个tablet服务器是没有副本的,完全依赖底层GFS把数据存到多台机 器上。数据的读写都通过单个tablet服务器,在tablet服务器出现故障的时需要master服务器将tablet指派到其他tablet服务器上 才能恢复可用。Dynamo系统则贯彻了“去中心化”的思想,将数据保存在多个副本上,每个副本都可以写入(update everywhere)。而不同副本同时写入的数据可能会存在不一致,则需要使用版本向量(version vector)记录不同的值和时间戳,由应用去解释或合并不一致的数据。尽管Dynamo系统还提供了NWR的方式来支持有一致性保证的读写操作,但总的 来说Dynamo为了高可用性牺牲了一致性。ZooKeeper、MongoDB与Chubby、Spanner类似,通过leader选举协议从多个副 本中选择一个leader,所有写操作都在经过leader节点序列化后,同步到其他副本上。ZooKeeper则是在写入大多数节点后返回,而 MongoDB主要采用异步的主从复制方式。
分布式事务
Spanner 系统中的分布式事务通过两阶段提交协议(2PC)实现。2PC是一类特殊的一致性协议,假设一个分布式事务涉及了多个数据节点,2PC可以保证在这些节点 上的操作要么全部提交,要么全部失败,从而保证了整个分布式事务的原子性(ACID里的A)。协议中包含两个角色:协调者(coordinator)和参 与者(participant/cohort)。协调者是分布式事务的发起者,而参与者是参与了事务的数据节点。在协议最基本的形式中,系统中有一个协调 者和多个参与者。
顾名思义,2PC也包含两个阶段,即投票阶段和提交阶段(如图3所示)。
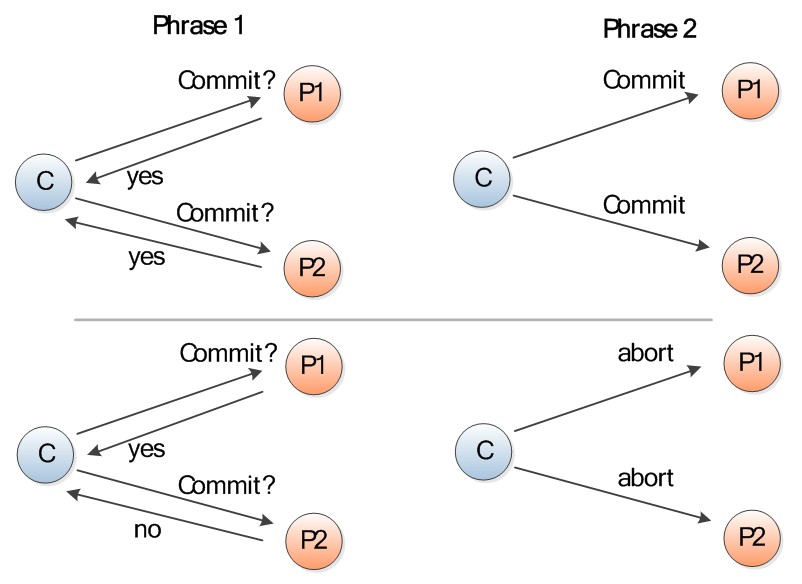
图3 两阶段提交协议(点击放大)
- 在第一阶段,协调者向所有的参与者发送投票请求,每个参与者决定是否要提交事务。如果打算提交的话需要写好redo、undo等日志,并向协调者回复yes或no。
- 在第二阶段,协调者收到所有参与者的回复,如果都是yes,那么决定提交这个事务,写好日志后向所有参与者广播提交事务的通知。反之,则中止事务并且通知所有参与者。参与者收到提交/中止事务的命令后,执行相应操作,如果提交的话还需要写日志。
协议过程包括两回合的通信,在协调者和参与者端需要多次写日志,而且整个过程中所有参与者都占有读锁、写锁,可见2PC开销不菲。
2PC 最令人诟病之处还不在于性能,而是在有些故障条件下,会造成所有参与者占有读锁、写锁堵塞在第二阶段,需要人工干预才能继续,存在严重的可用性隐患。假设 故障发生在第二阶段,协调者在做出决定后,通知完一个参与者就宕机了,更糟糕的是被通知的这位参与者在执行完“上级指示”之后也宕机了,这时对其他参与者 来说,就必须堵塞在那里等待结果。
Spanner利用基于Paxos协议的复制技术,改善了2PC的可用性问题。2PC协议过程中的协调者 和参与者生成的日志都会利用Paxos协议复制到所有副本中,这样无论是协调者或参与者宕机,都会有其他副本代替它们,完成2PC过程而不至于堵塞。在 Paxos协议上实现2PC这一思路很巧妙,Paxos协议保证了大多数节点在线情况下的可用性,而2PC保证了分布式协议的一致性。
事件的顺序
传统上,在设计一个分布式系统时,都会假设每个节点的运行速度和时钟的快慢各不相同的情况,并且在节点之间进行同步的唯一方法就是异步通信。系统中的每个节 点都扮演着观察者的角色,并从其他节点接收事件发生的通知。判断系统中两个事件的先后顺序主要依靠分析它们的因果关系,包括Lamport时钟、向量时钟 等算法,而这一切都存在通信开销。
因此,Spanner提出了一种新的思路,在不进行通信的情况下,利用高精度和可观测误差的本地时钟 (TrueTime API)给事件打上时间戳,并且以此比较分布式系统中两个事件的先后顺序。利用这个方法,Spanner实现了事务之间的外部一致性(external consistency)(如图4所示),也就是说,一个事务结束后另一个事务才开始,Spanner可以保证第一个事务的时间戳比第二个事务的时间戳要 早,从而两个事务被串行化后也一定能保持正确的顺序。
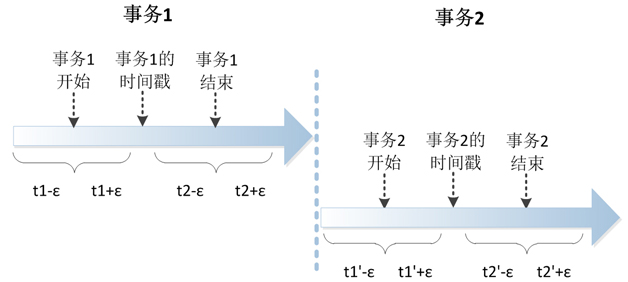
图4 事务外部一致性的实现(点击放大)
TrueTime API是一个提供本地时间的接口,但与Linux上gettimeofday接口不一样的是,它除了可以返回一个时间戳t,还会给出一个误差ε。例如,返 回的时间戳是1分30秒350毫秒,而误差是5毫秒,那么真实的时间在1分30秒345毫秒到355毫秒之间。真实的系统中ε平均下来是4毫秒。
利用TrueTime API,Spanner可以保证给出的事务标记的时间戳介于事务开始的真实时间和事务结束的真实时间之间。假如事务开始时TrueTime API返回的时间是{t1, ε1},此时真实时间在 t1-ε1到t1+ε1之间;事务结束时TrueTime API返回的时间是{t2, ε2},此时真实时间在t2-ε2到t2+ε2之间。Spanner会在t1+ε1和t2-ε2之间选择一个时间点作为事务的时间戳,但这需要保证 t1+ε1小于t2-ε2,为了保证这点,Spanner会在事务执行过程中等待,直到t2-ε2大于t1+ε1时才提交事务。由此可以推导 出,Spanner中一个事务至少需要2ε的时间(平均8毫秒)才能完成。
由此可见,这种新方法虽然避免了通信开销,却引入了等待时间。为了保证外部一致性,写延迟是不可避免的,这也印证了CAP定理所揭示的法则,一致性与延迟之间是需要权衡的。
最后介绍一下TrueTime API的实现。TrueTime API的实现大体上类似于网络时间协议(NTP),但只有两个层次。第一层次,服务器是拥有高精度计时设备的,每个机房若干台,大部分机器都装备了GPS 接收器,剩下少数机器是为GPS系统全部失效的情况而准备的,叫做“末日”服务器,装备了原子钟。所有的Spanner服务器都属于第二层,定期向多个第 一层的时间服务器获取时间来校正本地时钟,先减去通信时间,再去除异常值,最后求交集。
NewSQL
六年前,BigTable展示了一个简洁、优美、具有高可扩展性的分布式数据库系统,引起了NoSQL浪潮。然而Spanner的设计者们指出了BigTable在应用中遇到的一些阻力。
- 缺少类似SQL的界面,缺少关系数据库拥有的丰富的功能。
- 只支持单行事务,缺少跨行事务。
- 需要在跨数据中心的多个副本间保证一致性。
这些来自应用开发者的需求催生了Spanner,一个既拥有key-value系统的高可扩展性,也拥有关系数据库的丰富功能(包括事务、一致性等特性)的 系统。这类兼顾可扩展性和关系数据库功能的产品被称为“NewSQL”,Spanner的公开会不会开启NewSQL的时代呢?我们拭目以待。
总结
最后从CAP定理的角度来分析下Spanner。
CAP 定理是指在网络可能出现分区故障的情况下,一致性和可用性不可得兼。形式化地说就是,P => 非(A与P),可以更进一步地总结为,一致性和延迟之间必须进行权衡。Paxos协议在C和A之间选择了严格的一致性,而A则降级为大多数一致性 (majority available)。
Spanner还通过在事务中增加延迟的方法实现了外部一致性,每个事务需要至少两倍的时钟误 差才能完成。如果时钟出现故障造成误差增长,那么完成事务所需的时间也就随之增长。在这里,时钟故障也应当认为是P的一种形式。在发生时钟故障(P)的情 况下,为了保证一致性(C),而必须增加延迟(A),这一点充分印证了CAP定理。
从Spanner系统中,我们可以学习到一些经验。
- MegaStore、Spanner和F1系统所选择的树形、层次化的数据库schema是很精妙的,它能支持高效的表连接,这既提供了类似关系模型的范式,也提供了一个合适的粒度进行数据分区,具有好的可扩展性,H-Store也采用了这样的schema。
- 跨数据中心的多个副本间保持一致是可行的,Paxos协议的性能可以优化到一个可接受的范围。
- 在Paxos协议的基础之上实现的两阶段提交的可用性得到了提高。
- 在一个分布式系统中,本地时钟的作用可以比我们之前想象的大很多。
作者曹伟,淘宝核心系统数据库组技术专家,从事高性能服务器、IM、P2P、微博等各类型分布式系统、海量存储产品的开发,关注系统高可用性和一致性及分布式事务领域。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
NoSQL性能管理仍不完备 你该如何应对?
NoSQL技术现在仍然处于相对初级的阶段,众多NoSQL软件类型和产品服务令人眼花缭乱,选择合适的性能管理方案也成为一件颇具挑战性的事。
-
NoSQL——未来数据库家族的一员
NoSQL是对数据库由内而外的全方位改造,从而创造出一个高容量、高速度和高可变性的架构。然而,NoSQL供应商在可变性部分却正在遭遇失败。
-
GPU技术仅局限于游戏领域?当心大数据应用的小船说翻就翻
GPU技术的使用是一些机器学习应用的前沿和核心。Facebook,百度、亚马逊和其他一些公司正在使用的GPU集群来研究深层神经网络相关的机器学习应用程序。
-
【NoSQL数据库四大类型解析】如何选择列族数据库和图形数据库?
NoSQL数据库有多少类型?如何选择合适的NoSQL数据库?我们将介绍选择列族数据库和图型数据库必须考虑的因素。