
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
例如这样一个查询:select * from table1 where id=44。如果没有索引,必须遍历整个表,直到ID等于44的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),直接在索引里面找44(也就是在ID这一列找),就可以得知这一行的位置,也就是找到了这一行。可见,索引是用来定位的。
索引分为聚簇索引和非聚簇索引两种,聚簇索引 是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。
概述
建立索引的目的是加快对表中记录的查找或排序。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
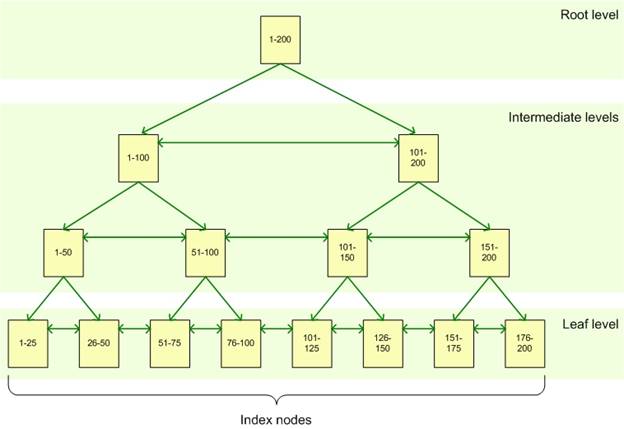
B树索引-Sql Server索引方式
为什么要创建索引
创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
在哪建索引
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列上创建索引:
在经常需要搜索的列上,可以加快搜索的速度;
在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少,不利于使用索引。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改操作远远多于检索操作时,不应该创建索引。
数据库优化
此外,除了数据库索引之外,在LAMP结果如此流行的今天,数据库(尤其是MySQL)性能优化也是海量数据处理的一个热点。下面就结合自己的经验,聊一聊MySQL数据库优化的几个方面。
首先,在数据库设计的时候,要能够充分的利用索引带来的性能提升,至于如何建立索引,建立什么样的索引,在哪些字段上建立索引,上面已经讲的很清楚了,这里不在赘述。另外就是设计数据库的原则就是尽可能少的进行数据库写操作(插入,更新,删除等),查询越简单越好。如下:

数据库设计
其次,配置缓存是必不可少的,配置缓存可以有效的降低数据库查询读取次数,从而缓解数据库服务器压力,达到优化的目的,一定程度上来讲,这算是一个“围魏救赵”的办法。可配置的缓存包括索引缓存(key_buffer),排序缓存(sort_buffer),查询缓存(query_buffer),表描述符缓存(table_cache),如下图:

配置缓存
第三,切表,切表也是一种比较流行的数据库优化方法。分表包括两种方式:横向分表和纵向分表,其中,纵向分表比较有使用意义,但是分表会造成查询的负担,因此在数据库设计之初,要想好:

分表
第四,日志分析,在数据库运行了较长一段时间以后,会积累大量的LOG日志,其实这里面的蕴涵的有用的信息量还是很大的。通过分析日志,可以找到系统性能的瓶颈,从而进一步寻找优化方案。

性能分析
以上讲的都是单机MySQL的性能优化的一些经验,但是随着信息大爆炸,单机的数据库服务器已经不能满足我们的需求,于是,多多节点,分布式数据库网络出现了,其一般的结构如下:
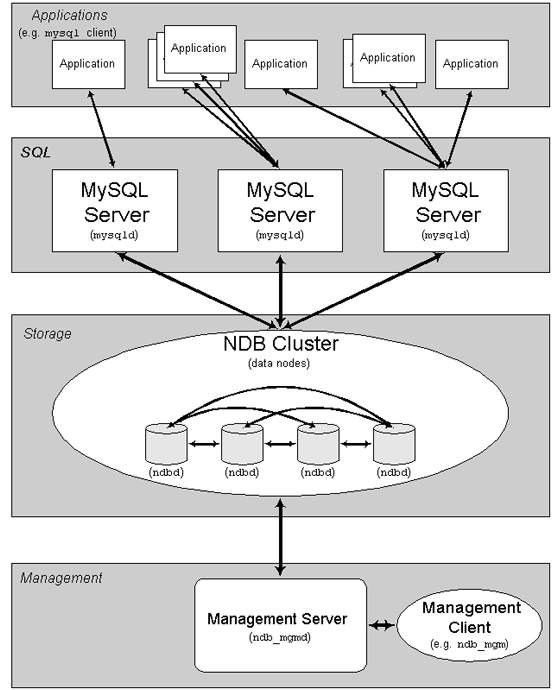
分布式数据库结构
这种分布式集群的技术关键就是“同步复制”。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
发现那些未被使用的数据库索引
为了确保快速访问数据,和其他关系型数据库系统一样SQL Server会利用索引来快速的查找数据。然而有太多索引的缺点是不得不维护这些索引,维护也需要代价。
-
如何为你的数据库事务日志减肥?
在大多数SQL Server的工作环境中,尤其是在OLTP环境中,数据库的事务日志性能出现瓶颈时往往会导致事务完成需要更多的时间。
-
如何在数据库应用中发挥SSD的优势
在数据库应用中发挥SSD技术的优势是具有挑战性的。本文列举了处理AWS应用的一些注意事项。
-
解读BigTable类NoSQL数据库的选型与设计
BigTable类数据库系统(HBase、Cassandra等)是为了解决海量数据规模的存储需要设计的。