
曾经写过一篇文章介绍MySQL中创建及优化索引组织结构的思路,但是没有提及关于SQL语句中隐性转换的问题,近期一位网友发现他们系统中业务场景中存在此问题,为此专门分析数据类型隐性转换的威力,告诉大家编写SQL语句时,也许一对单引号就可以引发一场血案。
示例校验的环境
软件环境
MySQL版本:5.1.40、5.1.15
存储引擎:Innodb
操作系统:Linux version 2.6.18-194.el5
数据环境
创建用于测试的表结构:
| CREATE TABLE tmp_index_len(ID INT UNSIGNED NOT NULL AUTO_INCREMENT, cate_id MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, brand_name VARCHAR(50) NOT NULL DEFAULT ”, CreateDate TIMESTAMP NOT NULL DEFAULT ’0000-00-00 00:00:00′, PRIMARY KEY(ID), INDEX idx_cid_bname(cate_id,brand_name) )ENGINE=InnoDB CHARACTER SET ‘utf8′ COLLATE ‘utf8_general_ci’; |
编写用于生成测试数据的存储过程代码:
| DELIMITER && DROP PROCEDURE IF EXISTS `usp_tmp_index_len_insert()` && CREATE PROCEDURE usp_tmp_index_len_insert(iNum MEDIUMINT ) BEGIN DECLARE iFlag TINYINT DEFAULT 0; WHILE iNum>0 DO IF iFlag=0 THEN START TRANSACTION; END IF; INSERT INTO tmp_index_len(cate_id,brand_name,CreateDate) VALUES(SUBSTRING(RAND(),4,5),SUBSTRING_INDEX(UUID(),’-‘,1),DATE_ADD(NOW(), INTERVAL -SUBSTRING(RAND(),4,3) DAY)); SET iFlag=iFlag+1; IF iFlag=100 THEN COMMIT; SET iFlag=0; END IF; SET iNum=iNum-1; END WHILE; END && DELIMITER ; |
执行存储过程的SQL语句:
| CALL usp_tmp_index_len_insert(500000); |
随机获得一条可用于测试的数据:
| root@localhost : test 09:16:51> select SUBSTRING(RAND(),4,5); +———————–+ | SUBSTRING(RAND(),4,5) | +———————–+ | 10342 | +———————–+ root@localhost : test 09:16:52> select * from tmp_index_len limit 10342,1; +——-+———+————+———————+ | ID | cate_id | brand_name | CreateDate | +——-+———+————+———————+ | 10343 | 46639 | b2bbbc22 | 2008-12-28 08:59:49 | +——-+———+————+———————+ |
编写SQL语句及生成其执行计划
SQL_1:

SQL_2:

SQL_3:

SQL_4:

SQL_5:

备注:5.1.40和5.1.15二大版本得到的执行计划一致。
易贷网朋友提供的SQL语句及执行计划截图:
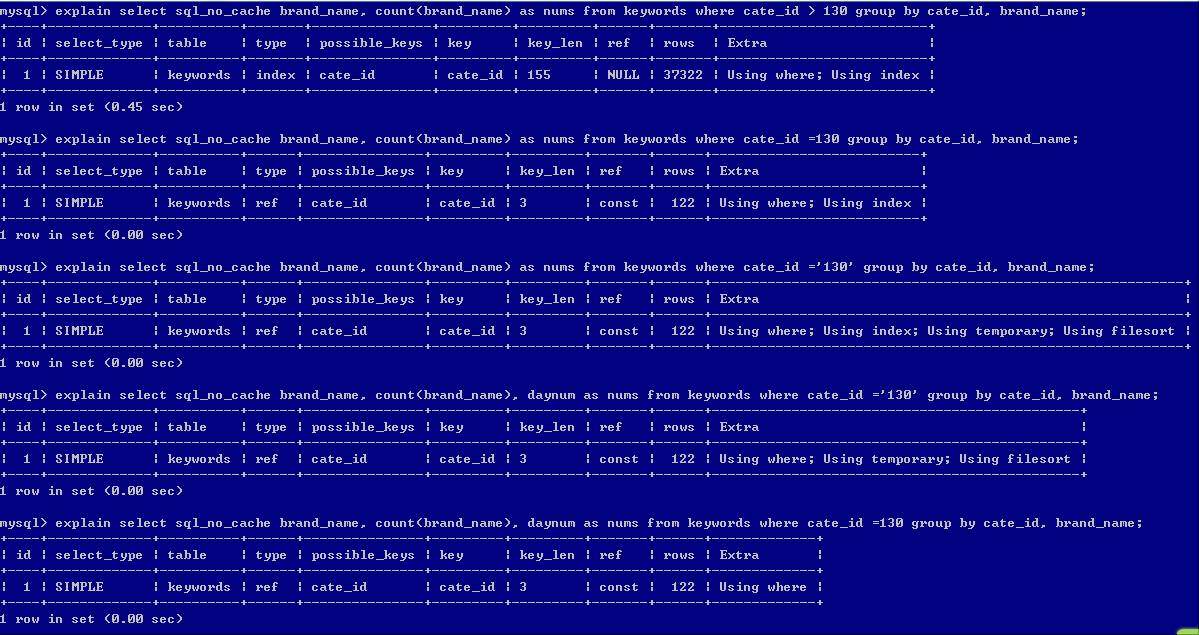
使用易贷网类似的表结构,以及索引结构,数据也是通过随机的方式生成,尽量模拟其真实数据环境,编写的SQL语句也基本上一样,但是编号SQL_1的执行计划不一样,差异点如下:
易贷网的SQL_1执行计划为:使用了索引全扫描,且索引的2个部分都使用了;
模拟的SQL_1执行计划为:使用了索引的范围扫描,只使用了索引的第一个字段;
SQL语句和执行计划的分析
SQL_1的执行计划分析
(1). 索引的范围扫描;
(2). 联合索引只使用了前缀字段:cate_id;
(3). 分组计算及排序借助组合索引完成;
SQL_2的执行计划分析
(1). 索引值的等值查找;
(2). 联合索引只使用了前缀字段:cate_id;
(3). 分组计算及排序借助组合索引完成;
SQL_3、SQl_4的执行计划分析
(1). WHERE字句出现:cate_id=’46639′
(2). 索引值的等值查找;
(3). 联合索引只使用了前缀字段:cate_id;
(4). 分组计算及排序没有借助组合索引完成,而是临时表;
SQL_5的执行计划分析
(1). 索引值的等值查找;
(2). 联合索引只使用了前缀字段:cate_id;
(3). 分组计算及排序借助组合索引完成;
(4). 查询结果集从数据文件中通过WHERE字句过滤获得;
总结
(1). SQL_1、SQL_2需要查询和统计的数据,是组合索引idx_cid_bname(cate_id,brand_name)的全部,为此只要借助组合索引即可获得记录,不需要阅读表的元数据,这个可以借助逻辑IO分析去验证;
(2). SQL_3、SQL_4的WHERE字句传入的值为字符串类型,而字段类型为INT,为此优化器把传入的值转换成了INT类型,若是传入一个无法转换的字符串,将会被默认转换成0,大家可以测试下,为此数据查找和过滤的时候,能使用组合索引,但是数据被读出的时候,Cate_id的值被隐含地转换成与传入值一致的数据类型:字符,为此导致分组计算和排序不得不使用临时表,并且进行二次排序完成;
(3). SQL_5的记录集中增加了一列非组合索引涉及的字段,为此不能继续只使用组合索引满足查询记录集的要求,不得不通过索引再读表中的元数据,另外因为无数据类型的隐性转换,可以先借助索引完成分组计算和排序,再读元数据;
(4). 对于易贷网朋友提供的第一个查询计划,可能是数据量、索引字段数据分布率、统计信息等原因,造成查询优化器认为索引全扫描更快;
结尾
本文讲述的是字段传入的值类型与字段类型不一样,另外有一种显示的类型转换,就是对传入值加上对应的函数,比如DATE_FORMAT()函数强制传入的值转换成日期类型及日期格式,不过大家千万别把显示转换函数加到字段上,那么优化器也无能为力,将SQL导致使用上索引。对于隐性转换的问题,出现一些隐蔽性,有些优化器能纠正,有些时候MySQL将会用默认值替换,并且给出一个警告,例如:

日常工作中,程序代码中最容易出现字符类型和整数类型之间的隐性转换,而且还报错误信息,因为mysql默认情况下的要求很低(注:可调整SQL_MODE参数)。最后重复下那句话:莫让一对单引号引发一场灾难!
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
MariaDB InnoDB表空间碎片整理
从MariaDB 10.1开始,MariaDB把Facebook的碎片整理代码合并进来了,并且把所有代码都调整到InnoDB/XtraDB层去实现,因而只需要使用现成的 OPTIMIZE TABLE 命令就行。
-
甲骨文宣布MySQL Cluster 7.4全面上市
甲骨文公司今天宣布MySQL Cluster 7.4全面上市。MySQL Cluster是一款ACID兼容的开源事务处理型数据库,具有实时内存性能和99.999%的可用性。
-
不同事务隔离级别对MySQL性能的影响
在这篇文章里,我们将讨论InnoDB 事务隔离模式,还有它们与MVCC(多版本并发控制)的关系,以及它们是如何影响MySQL性能的。
-
解读MySQL数据库的双向复制
在主-从复制中,主机影响从机。但从数据库中的任何更改不会影响主数据库,这篇文章将帮助你实现双向复制。