
背景介绍:在数据库表中,存储的数据经常是稀疏数据(sparse data),而不是稠密数据(dense data)。先来了解一下什么是稀疏数据,比如一个产品销售情况表(比如有产品名、销售时间(精确到年月)、销售量3个列),假设某个时间某些产品它没有销售,一般也不会将这些产品的销售量存储为0,而是不存储,这样在产品销售情况表中就会产生很多缺失的行(gap rows),导致的结果就是特定产品销售数据按时间维度进行排序,是不连续的,或者说此产品销售在时间序列上是有缺失的。顾名思义,稠密数据是相对于稀疏数据来说的,还是用上面的假设说明,也就是说产品在某个时间没有销售,也必须存储此产品销售情况,销售量置0存储,这样对某个特定产品来说它在时间序列就是连续的,但是事实经常不是如此,所以才有将稀疏数据稠密化的过程,数据稠密化在数据仓库应用中很常见。
当然销售情况表只是一个典型的情况,在实际应用中,有各种各样的缺失数据情况。如果决策者看销售情况统计表,他可不希望有的产品按时间序列断断续续,而应该给他提供时间序列连续的分析报表,他可能需要看到每个产品每个时间的销售情况,就算在某个时间没有销售,也必须置0,这样的报表对决策者才有意义,而且可以进行更细粒度的分析,比如使用分析函数对每个产品按年月汇总计算销售偏移量,这样可以方便对比每个产品每个月的销售情况,从而为决策支持提供强大保障。
为了实现将稀疏数据转为稠密数据,Oracle10g提供了Partitioned Outer Join语法,和一般的OUTER JOIN类似(但是不支持Full Outer Join,只支持Left和Right两种),只不过增加了PARTITION BY的语法,根据PARTITION BY将表逻辑分区,然后对每个分区进行OUTER JOIN,这样就可以达到填补缺失行,实现数据稠密化的目的,也相当于对每个分区里的数据OUTER JOIN后进行UNION操作,理解这个很重要,否则经常不知道到底是哪个表哪些列该分区,不知道到底是用LEFT JOIN还是用RIGHT JOIN,在后面的例子会详细分析这个语法如何使用。
1.1 Partitioned Outer Join语法
Partitioned Outer Join语法如下:
| SELECT ….. FROM table_reference PARTITION BY (expr [, expr ]… ) RIGHT OUTER JOIN table_reference SELECT ….. FROM table_reference LEFT OUTER JOIN table_reference PARTITION BY (expr [, expr ]… ) |
Partitioned Outer Join语法很简单,也就是在JOIN的表后面ON条件之前加入PARTITION BY语句即可。上面只列出了最简单的两表(内联视图,视图等其他结果集)连接,多个对象的连接类似,其他复杂的语法结构省略了,语法结构上PARTITION BY是可以放在任何合法连接对象后面的,而且和一般的PARTITION BY没有区别,可以有多个分区列(表达式),然后用外连接,注意一定要搞清楚是用LEFT JOIN还是用RIGHT JOIN,比如第1个语法结构在JOIN之前的对象使用了PARTITION BY,那么就是对第1个对象填充缺失数据,所以必须用RIGHT JOIN,第2个语法结构类似。
当然也可以直接用JOIN,不用OUTER JOIN,但是这样无法填充缺失数据,没有意义,另外注意不能使用86的外连接语法+,这是不行的,必须使用92语法。一般来说,根据需求确定PARTITION BY的键值,PARTITION BY语句要紧跟需要分区的对象后面,然后根据PARTITION BY的位置决定用LEFT JOIN还是RIGHT JOIN,否则可能会出错或获得不正确的结果。
1.2 Partitioned Outer Join实例
本节主要从相关实例中研究Partitioned Outer Join的使用,主要实例有填充一维缺失数据、填充多维缺失数据、填充数据到清单表中等。例子中的建表等语句请参考代码poj.sql。
1) 填充一维缺失数据
t表是一个产品销售情况表,数据如下:
| DINGJUN123>SELECT * FROM t 2 ORDER BY years,months,product_name; YEARS MONTHS PRODUCT_NAME SALES ———- ———- ——————– ———- 2008 1 A 1000 2008 1 B 1500 2008 2 A 2000 2008 2 B 3000 2008 2 C 1000 2008 3 A 3000 已选择6行。 |
上面的表数据是很简单的,在实际应用中,这个数据可能是语句的中间结果。从结果上可以看到,有2008年1、2、3这3个月的销售数据,但是有些产品的销售数据在某些月份是缺失的,比如2008年1月产品C就没有数据。现在需要一个报表,能够填充所有产品对应2008年前3月缺失的数据,销售字段sales置0,要实现这样的报表,如何做呢?
先来看下传统做法:既然填充每个产品对应月份缺失的数据,那么肯定需要构造一个结果集存储了每个产品每个时间对应的数据,这样再与原始表外连接,则可以达到填充缺失数据的目的,为了实现这个目的,很容易想到需要将表中对应的时间year、month与产品做笛卡尔积(每个部分数据都是唯一的,是这样的数据做笛卡尔积),生成每个产品每个时间的结果数据,然后与原始表外连接。下面用SQL实现:
–1.WITH子句将时间和product_name固定下来,然后在查询中生成笛卡尔积,这样就有每个产品的所有时间段数据,当然
–这里的WITH子句也可以直接生成笛卡尔积
–2.笛卡尔积和原始表t做外连接,从而实现数据稠密化过程,当然这里可以使用t RIGHT JOIN …这样就不需要写那么
–多+号了。
–这里的WITH子句从原始表中DISTINCT,如果原始表很大,效率不好,实际应用经常是从其他关联表获取或自己构造
| WITH year_month AS (SELECT DISTINCT years,months FROM t), product AS (SELECT DISTINCT product_name FROM t) SELECT m.years,m.months,m.product_name,NVL(t.sales,0) sales FROM t, (SELECT years,months,product_name FROM year_month,product) m WHERE t.years(+) = m.years AND t.months(+) = m.months AND t.product_name(+) = m.product_name ORDER BY 1,2,3; |
–按照上面说的改进的SQL,WITH直接生成笛卡尔积,然后使用SQL92新的外连接语法,省略了很多+号,更容易理解
| WITH m AS (SELECT years,months,product_name FROM (SELECT DISTINCT years,months FROM t), (SELECT DISTINCT product_name FROM t) ) SELECT m.years,m.months,m.product_name,NVL(t.sales,0) sales FROM t RIGHT JOIN m ON t.years = m.years AND t.months = m.months AND t.product_name = m.product_name ORDER BY 1,2,3; |
传统填充缺失数据,往往就要通过笛卡尔积构造完整数据集,然后与原始表外连接。根据上面的SQL,这个结果应该是生成所有产品所有年月的销售数据,如果原始表中没有,则对应缺失年月的数据为0,执行上面的SQL结果为:
| YEARS MONTHS PRODUCT_NAME SALES ———- ———- ——————– ———- 2008 1 A 1000 2008 1 B 1500 2008 1 C 0 2008 2 A 2000 2008 2 B 3000 2008 2 C 1000 2008 3 A 3000 2008 3 B 0 2008 3 C 0 已选择9行。 |
现在填充了3行缺失数据,实现了所有产品对应2008年前3月时间序列上的稠密化报表目的,你是否发现到传统做法比较复杂,这里是很简单的一维缺失数据的填充,如果是多维缺失数据填充呢?在实际应用中SQL经常很复杂,这个销售表t也许都是SQL的中间结果,那么这样的做法需要通过笛卡尔积生成所有组合情况,性能可能不好,而且SQL比较复杂。
下面看10g对填充数据专门做的改进,使用PARTITIONED OUTER JOIN实现数据稠密化工作,更加简单,而且往往性能往往要比传统做法要好。通过前面对PARTITUONED OUTER JOIN的分析以及传统实现数据稠密化的方法,使用PARTITIONED OUTER JOIN只需要对产品进行分区然后和所有时间外连接,则可以补全缺失数据,如下:
–这里的m是从原始表中获取的,实际应用中一般自己构造或从其他关联表获取,从原始表获取DISTINCT,可能效率不好。
| SELECT m.years,m.months,t.product_name,NVL(t.sales,0) sales FROM t PARTITION BY (t.product_name) RIGHT JOIN (SELECT DISTINCT years,months FROM t) m ON t.years = m.years AND t.months = m.months ORDER BY 1,2,3; |
一定要理解PARTITIONED OUTER JOIN的两种语法结构,这里的PARTITION BY是紧跟在表t后面的,相当于对每个按product_name分区的每个分区内的行和中间结果m外连接,这样就能补起数据了,相当于每个按product_name划分的行与m外连接的UNION ALL结果,通过这个例子,就可以很好地理解PARTITIONED OUTER JOIN的使用,这样你就能正确用多种方法进行改写了。这个语句的结果和上面的一致,不再列出。如果你理解了上面说的话,就可以使用LEFT JOIN来改写:
| SELECT m.years,m.months,t.product_name,NVL(t.sales,0) sales FROM (SELECT DISTINCT years,months FROM t) m LEFT JOIN t PARTITION BY (t.product_name) ON t.years = m.years AND t.months = m.months ORDER BY 1,2,3; |
执行结果和上面的RIGHT JOIN完全一样的,为什么上面又变成LEFT JOIN了呢?原因是现在t PARTITION BY移到JOIN后面了,当然要左连接所有的时间才可以填充缺失数据,所以要使用第2种语法结构。下面看下此语句的执行计划:
| 执行计划 ———————————————————- Plan hash value: 1692607762 ————————————————————————————- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ————————————————————————————- | 0 | SELECT STATEMENT | | 1 | 46 | 10 (40)| 00:00:01 | | 1 | SORT ORDER BY | | 1 | 46 | 10 (40)| 00:00:01 | | 2 | VIEW | | 1 | 46 | 9 (34)| 00:00:01 | | 3 | MERGE JOIN PARTITION OUTER| | 1 | 72 | 9 (34)| 00:00:01 | | 4 | SORT JOIN | | 6 | 156 | 5 (40)| 00:00:01 | | 5 | VIEW | | 6 | 156 | 4 (25)| 00:00:01 | | 6 | HASH UNIQUE | | 6 | 156 | 4 (25)| 00:00:01 | | 7 | TABLE ACCESS FULL | T | 6 | 156 | 3 (0)| 00:00:01 | |* 8 | SORT PARTITION JOIN | | 6 | 276 | 4 (25)| 00:00:01 | | 9 | TABLE ACCESS FULL | T | 6 | 276 | 3 (0)| 00:00:01 | ————————————————————————————- Predicate Information (identified by operation id): ————————————————— 8 – access(“T”.”YEARS”=”M”.”YEARS”) filter(“T”.”MONTHS”=”M”.”MONTHS” AND “T”.”YEARS”=”M”.”YEARS”) |
PARTITIONED OUTER JOIN的效果体现在第3到第8步,其中第8步就是将数据排序然后放入分区内,第3步就是外连接产生填充后的结果集,当然这里的MERGE JOIN可以为NESTED LOOP JOIN,也可以使用hint,比如use_nl(m,t)来让它走NESTED LOOP PARTITION OUTER。这个执行计划会与后面改写的语句执行计划做对比,如果没有第3步和第8步,那么PARTITIONED OUTER JOIN是不起作用的。使用PARTITIONED OUTER JOIN的过程如图所示:
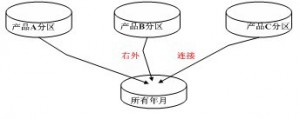
图1-1
上面语句的实现的功能就是3个外连接的UNION ALL结果,其他复杂的数据稠密化以此类推。其实10g的MODEL也可以实现数据填充,但是MODEL语句比较复杂,比如上面可以用MODEL简单改写为:
–只考虑2008年前3月,如需详细学习MODEL子句,请参考相关文档,MODEL很强大,可以实现很多复杂功能
| SELECT years,months,product_name,NVL(sales,0) FROM t MODEL PARTITION BY (product_name) DIMENSION BY (years,months) MEASURES(sales) RULES (sales[2008, FOR months IN (1,2,3)] = sales[2008,CV()]) ORDER BY 1,2,3; |
如果是多维或其它复杂情况的改写,会很麻烦,对于数据稠化建议使用使用10g的PARTITIONED OUTER JOIN。
如果你不仔细地研究语法结构,那么可能写的语句不报错,但是结果却不是正确的,当然也有可能出错,比如上面的RIGHT JOIN改写为:
| SELECT m.years,m.months,t.product_name,NVL(t.sales,0) sales FROM t RIGHT JOIN (SELECT DISTINCT years,months FROM t) m PARTITION BY (t.product_name) ON t.years = m.years AND t.months = m.months ORDER BY 1,2,3; |
这个语句不会报错,但是结果:
| YEARS MONTHS PRODUCT_NAME SALES ———- ———- ——————– ———- 2008 1 A 1000 2008 1 B 1500 2008 2 A 2000 2008 2 B 3000 2008 2 C 1000 2008 3 A 3000 已选择6行。 |
将本来应该放在表t后面的PARTITION BY移到了m后面,没有实现填充缺失行的目的,原因是ORACLE对这种语法结构不会按照PARTITIONED OUTER JOIN实现填充行的目的进行支持,看下执行计划就明白了,计划如下:
| 执行计划 ———————————————————- Plan hash value: 3441530730 —————————————————————————— | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | —————————————————————————— | 0 | SELECT STATEMENT | | 6 | 432 | 9 (34)| 00:00:01 | | 1 | SORT ORDER BY | | 6 | 432 | 9 (34)| 00:00:01 | |* 2 | HASH JOIN OUTER | | 6 | 432 | 8 (25)| 00:00:01 | | 3 | VIEW | | 6 | 156 | 4 (25)| 00:00:01 | | 4 | HASH UNIQUE | | 6 | 156 | 4 (25)| 00:00:01 | | 5 | TABLE ACCESS FULL| T | 6 | 156 | 3 (0)| 00:00:01 | | 6 | TABLE ACCESS FULL | T | 6 | 276 | 3 (0)| 00:00:01 | —————————————————————————— Predicate Information (identified by operation id): ————————————————— 2 – access(“T”.”MONTHS”(+)=”M”.”MONTHS” AND “T”.”YEARS”(+)=”M”.”YEARS”) |
上面这个语句的计划和去掉PARTITION BY的语句计划完全一致,没有原来的第3步和第8步的PARTITION操作。为什么我这么强调PARTITION OUTER JOIN的语法结构呢?因为如果不理解这个语法结构,必然会导致不正确的结果,如果理解了这个语法结构,那么一切就变得很简单,其他改写的错误类似,还有一种错误是直接报错,如下:
| DINGJUN123>SELECT m.years,m.months,t.product_name,NVL(t.sales,0) sales 2 FROM t 3 LEFT JOIN 4 (SELECT DISTINCT years,months FROM t) m 5 PARTITION BY (t.product_name) 6 ON t.years = m.years 7 AND t.months = m.months 8 ORDER BY 1,2,3; PARTITION BY (t.product_name) * 第 5 行出现错误: ORA-00904: : 标识符无效 |
为什么会出错,因为这里是LEFT JOIN,那么基表是t,在m后面使用PARTITION BY并且引用了t的字段,那么是引用不到的,所以出错,如果是RIGHT JOIN,则正确,但是又不符合语法结构,导致PARTITION BY白写。只有前面说的两种正确写法才是对的,特别在多表连接以及多维度填充缺失行的时候一定要注意PARTITION BY的位置和其引用的字段有关,一定要放在紧跟要引用的对象后面,然后根据语法结构规则使用LEFT JOIN还是RIGHT JOIN,否则要么不正确,要么错误。
OK,现在已经实现了数据稠密化工作,那么稠密化工作的意义何在呢?比如要做按时间序列表示销售情况波动图,要求每个产品每个时间序列上都有数据,不产生gap值,是很有意义的,也可以进一步对数据进行明细分析,比如使用分析函数分析对比当月和上月的销售情况,决策人员看到所有产品所有时间点的数据,这样可以很好地做决策,如果你给他缺失行的分析报表,他怎么能看到某个时间点某个产品没有销售呢,如何分析造成此情况的原因呢?下面就做一个使用分析函数对比销售情况的报表:
–使用分析函数对比产品当前月销售与上月销售情况,计算递增量,可以对决策支持提供很清晰的报表
| SELECT years,months,product_name,sales, sales-NVL(LAG(sales) OVER(PARTITION BY product_name ORDER BY years,months) ,0) add_last_sales FROM ( SELECT m.years,m.months,t.product_name,NVL(t.sales,0) sales FROM (SELECT DISTINCT years,months FROM t) m LEFT JOIN t PARTITION BY (t.product_name) ON t.years = m.years AND t.months = m.months ); |
结果如下:
| YEARS MONTHS PRODUCT_NAME SALES ADD_LAST_SALES ———- ———- ——————– ———- ————– 2008 1 A 1000 1000 2008 2 A 2000 1000 2008 3 A 3000 1000 2008 1 B 1500 1500 2008 2 B 3000 1500 2008 3 B 0 -3000 2008 1 C 0 0 2008 2 C 1000 1000 2008 3 C 0 -1000 已选择9行。 |
现在这个报表是不是很有意义了呢!决策者可以专门对add_last_sales<=0的数据做分析,找出原因,从而改进销售。
2) 填充多维缺失数据
在例1中已经详细说了使用PARTITIONED OUTER JOIN解决一维缺失数据填充问题,重点讲解了如何理解PARTITIONED OUTER JOIN的语法结构以及注意一些错误问题,其实,理解了例1的内容,多维缺失数据填充思想完全一致,下面就在例1的基础上对销售表t增加一个字段regions,然后填充多维缺失数据。
| DINGJUN123>SELECT * FROM t 2 ORDER BY years,months,product_name,regions; YEARS MONTHS PRODUCT_NAME REGIONS SALES ———- ———- ——————– ——————– ———- 2007 2 C 北区 2000 2008 1 A 东区 1000 2008 1 A 西区 2500 2008 1 B 东区 1500 2008 2 A 南区 2000 2008 2 A 西区 500 2008 2 B 东区 3000 2008 2 C 北区 1000 2008 3 A 东区 3000 已选择9行。 |
这个报表不是我想看的最终报表,我需要的报表是稠密报表,也就是对于每个产品,横跨所有年、所有区域都应该有汇总数据,但是现在缺失了很多数据,比如对于产品A来说,少了07年4个区域的汇总数据,08年少了北区的汇总数据,最终的报表数据应该有年数目(2)*产品数(3)*区域数(4)=24行记录。
现在需要填补每个产品所有年份和所有区域2维缺失数据,那么怎么做呢?首先需要补全每个产品所有年或者每个产品所有区域的数据,然后按产品和年分区或产品和区域分区再与所有区域或所有年外连接,这样就能填充缺失数据了,所有对2维缺失数据填充可以用2步PARTITIONED OUTER JOIN,当然也可以将年份和区域做笛卡尔积,然后转为1维数据填充,这样的好处很明显,因为年份和区域很少,这样可以减少表的扫描,强烈推荐此方法,见方法4,其他维度的类似。
–方法1:首先补全每个产品所有区域的汇总数据,然后按产品和区域分区与所有年份外连接,从而补全每个产品横跨年和区域的汇–总数据。
| WITH v1 AS (SELECT years,product_name,regions,SUM(sales) sum_sales FROM t GROUP BY years,product_name,regions), v2 AS (SELECT DISTINCT regions FROM t), v3 AS (SELECT DISTINCT years FROM t) SELECT v3.years,v4.product_name,v4.regions,v4.sum_sales FROM (SELECT v1.years,v1.product_name,v2.regions,v1.sum_sales FROM v1 PARTITION BY (v1.product_name) RIGHT JOIN v2 ON v1.regions = v2.regions ) v4 PARTITION BY (product_name,regions) RIGHT JOIN v3 ON v3.years = v4.years ORDER BY 2,1,3; |
–方法2:先补全每个产品所有年的汇总数据,然后按产品和年分区与区域外连接,从而实现年和区域的二维数据稠密–化
| WITH v1 AS (SELECT years,product_name,regions,SUM(sales) sum_sales FROM t GROUP BY years,product_name,regions), v2 AS (SELECT DISTINCT regions FROM t), v3 AS (SELECT DISTINCT years FROM t) SELECT v4.years,v4.product_name,v2.regions,v4.sum_sales FROM (SELECT v3.years,v1.product_name,v1.regions,v1.sum_sales FROM v1 PARTITION BY (v1.product_name) RIGHT JOIN v3 ON v1.years = v3.years ) v4 PARTITION BY (product_name,years) RIGHT JOIN v2 ON v2.regions = v4.regions ORDER BY 2,1,3; |
–方法3:
/**前面已经说了,这里WITH子句中很多DISTINCT数据都是从原始表来的,如果销售表t几百万行几千万行,这种DISTINCT必然影响效率,这个一般不符合实际情况,我只是做个例子而已,–在实际应用中一般要么自己构造,要么从其他配置表中获取,比如regions应该有独立的区域表,存储的数据不多,这样–可以提高效率,比如years,一般统计的年份都是固定的,可以自己构造或从其他表中获取,可能有个时间表。
| **/ WITH v1 AS (SELECT years,product_name,regions,SUM(sales) sum_sales FROM t GROUP BY years,product_name,regions), –这里的f_str2list是自己写的函数,将逗号分割的字符串分割为多行数据 v2 AS (SELECT COLUMN_VALUE regions FROM TABLE(CAST (f_str2list(‘东区,南区,西区,北区’) AS varchar2_tt)) ), –自己构造指定时间维度数据 v3 AS (SELECT 2007+LEVEL-1 years FROM DUAL CONNECT BY LEVEL<3 ) SELECT v3.years,v4.product_name,v4.regions,v4.sum_sales FROM (SELECT v1.years,v1.product_name,v2.regions,v1.sum_sales FROM v1 PARTITION BY (v1.product_name) RIGHT JOIN v2 ON v1.regions = v2.regions ) v4 PARTITION BY (product_name,regions) RIGHT JOIN v3 ON v3.years = v4.years ORDER BY 2,1,3; |
–方法4:最佳方法,将缺失的维度用笛卡尔积补齐,转为一维数据填充,外连接和表的访问次数减少
| WITH v1 AS (SELECT years,product_name,regions,SUM(sales) sum_sales FROM t GROUP BY years,product_name,regions), v2 AS (SELECT ‘东区’ regions FROM DUAL UNION ALL SELECT ‘南区’ regions FROM DUAL UNION ALL SELECT ‘西区’ regions FROM DUAL UNION ALL SELECT ‘北区’ regions FROM DUAL ), v3 AS (SELECT 2007+LEVEL-1 years FROM DUAL CONNECT BY LEVEL<3 ) SELECT v5.years,v1.product_name,v5.regions,v1.sum_sales FROM v1 PARTITION BY (v1.product_name) RIGHT JOIN (SELECT regions,years FROM v2,v3) v5 ON v1.regions = v5.regions AND v1.years = v5.years ORDER BY 2,1,3; |
第3个方法效率要比前2个好点,第4个方法明显最好,因为年份和区域的数据很少,笛卡尔积的数据量也不大,但是如果用两次Partition Outer Join明显扫描的数据增多。这里的测试表也没有建立索引,具体调整和优化过程可以根据实际情况选择,上面4个SQL的结果一致,如下:
| YEARS PRODUCT_NAME REGIONS SUM_SALES ——— ——————– ——————– ———- 2007 A 东区 2007 A 北区 2007 A 南区 2007 A 西区 2008 A 东区 4000 2008 A 北区 2008 A 南区 2000 2008 A 西区 3000 2007 B 东区 2007 B 北区 2007 B 南区 2007 B 西区 2008 B 东区 4500 2008 B 北区 2008 B 南区 2008 B 西区 2007 C 东区 2007 C 北区 2000 2007 C 南区 2007 C 西区 2008 C 东区 2008 C 北区 1000 2008 C 南区 2008 C 西区 已选择24行。 |
现在对所有产品实现了时间(年)和区域这两个维度的汇总数据填充,总共有24行,符合预期分析的结果。读者应该掌握上面说的从一维到多维数据稠密化的方法,当然,多维数据稠密化也可以用传统方法解决,这里不再叙述。
3) 使用LAST_VALUE填充缺失数据
还有一种填充缺失数据的常用方法是使用LAST_VALUE+IGNORE NULLS(注意使用FIRST_VALUE含义就不一样了,找的就不是最近行了),对指定维度的数据有缺失,则使用最近时间的数据填充,这在报表中是很常见的,这样的报表可以有很好的分析和对比功能。比如:
| DINGJUN123>ALTER SESSION SET NLS_DATE_FORMAT=’YYYY-MM-DD’; 会话已更改。 DINGJUN123>SELECT * FROM t 2 ORDER BY product_name,done_date; PRODUCT_NAME DONE_DATE SALES ——————– ———- ———- A 2010-07-01 1000 A 2010-07-05 2000 B 2010-07-02 3000 B 2010-07-04 4000 已选择4行。 |
现在需求是:首先对每个产品的所有时间(精确到天)销售实现数据填充,其次如果当天没有销售,则用此产品最近时间的销售数据填充或者增加一行显示当天没有销售的产品的最近时间销售数据。对于实现维度数据的填充,前面已经说了使用PARTITIONED OUTER JOIN,实现产品没有销售则找最近时间此产品的销售,想到了可以使用分析函数LAST_VALUE+IGNORE NULLS实现,11g的LAG也可以加IGNORE NULLS实现(同样不能用LEAD)。SQL如下:
| WITH v1 AS (SELECT DATE’2010-07-01′+LEVEL-1 done_date FROM DUAL CONNECT BY LEVEL<6) SELECT product_name,done_date,sales, LAST_VALUE(sales IGNORE NULLS) OVER(PARTITION BY product_name ORDER BY done_date) recent_sales FROM ( SELECT t.product_name,v1.done_date,t.sales FROM t PARTITION BY (t.product_name) RIGHT JOIN v1 ON t.done_date = v1.done_date ); |
显示结果如下:
| PRODUCT_NAME DONE_DATE SALES RECENT_SALES ——————– ———- ———- ———— A 2010-07-01 1000 1000 A 2010-07-02 1000 A 2010-07-03 1000 A 2010-07-04 1000 A 2010-07-05 2000 2000 B 2010-07-01 B 2010-07-02 3000 3000 B 2010-07-03 3000 B 2010-07-04 4000 4000 B 2010-07-05 4000 已选择10行。 |
现在实现了上述需求,还有一行recent_sales为空,因为它是产品B的第1个时间点的数据。使用LAST_VALUE+IGNORE NULLS结合PARTITIONED OUTER JOIN实现上述报表是很常见的,实现报表数据稠密化思想主要就是上面这些,当然MODEL语句也可以实现,但是没有PARTITIONED OUTER JOIN简单。
1.3 Partitioned Outer Join总结
传统方法填补缺失数据,经常需要使用笛卡尔积构造中间结果,然后与原始数据外连接,往往性能不是很好,而且SQL比较复杂,10g提供的PARTITIONED OUTER JOIN的语法简单,可以高效地实现报表数据稠化,使用PARTITIONED OUTER JOIN一定要掌握语法结构中的2种结构:首先确定分区键,然后确定使用LEFT JOIN还是RIGHT JOIN,此语法结构对FULL JOIN不支持。另外MODEL等语法也可以实现类似的功能,但是与PARTITIONED OUTER JOIN相比,就复杂多了,为了很好地使用PARTITIONED OUTER JOIN实现数据稠化,一定要分析清楚需求,然后根据本部分说的使用步骤以及一些注意点,比如如何高效地使用DISTINCT构造结果集(常自己构造或从关联表获取),这样才能正确高效地实现报表数据的稠化。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
甲骨文自治数据库亮相 带来云计算新希望
早前甲骨文还不在云计算公司之列,而现在该公司正在迅速弥补其失去的时间。甲骨文的云计算核心是甲骨文自治数据库(O […]
-
2017年12月数据库流行度排行榜 定格岁末排名瞬间
数据库知识网站DB-engines最近更新的2017年12月份数据库流行度排名情况是否能提供更多的看点呢?TechTarget数据库网站将与您分享12月份的榜单排名情况,让我们拭目以待。
-
2017年11月数据库流行度排行榜 半数以上数据库积分减少
数据库知识网站DB-engines更新了2016年11月份的数据库流行度排行榜。TechTarget数据库网站将与您一同关注11月份的榜单排名情况。
-
控制合约 不再畏惧Oracle
许多公司都与Oracle有无限制授权协议,他们害怕离开这个协议,所以就证明他们在使用Oracle的软件,即使因为需求单独购买部分授权许可也可能总体是省钱的。