
Cassandra的数据模型借鉴自Google的BigData模型,简单来说就是将写操作放在一个内存块中,当内存块大小达到一定大小时,将内存中的数据排序后写成一个sstable文件,而这种方式会有一些问题,而前段时间Google的Chromium团队开发的一个开源的key-value存储以其分层压缩机制给了大家一种新的思路,Cassandra也适时的将这种思路引入,也就是今天我们要介绍的Cassandra的分层压缩。
目前的压缩机制:Tiered Compaction
在讲分层压缩之前,我们先来看一下Cassandra目前的数据存储模型和数据压缩机制。
像我们上面说的一样,Cassandra在内存数据达到一定大小时,会将数据排序写入磁盘生成一个sstable文件块,当第一级的sstable数目达到四个时,由于这四个sstable相当于是按时间划分的一段时间的数据快照,所以这四个块中会有一些相同的数据。我们将这四个sstable会进行合并压缩,就可憎减小空间。具体过程如下图所未:

上图绿色块就表示一个sstable,当第一级的sstable达到四个,就会合并成一个新的第二级的sstable。当然,当第二级的sstable也达到四个,就会再进行合并生成第三级的sstable,以此类推。如果下图所未,当一二三四级sstable都已经有三个,可能这个合并就会一直进行下去。

由于sstable之间可能有重复的数据,也就是同一个数据的不同版本可能存在在多个sstable中,所以上面的方式在更新比较频繁的系统中,可能会有下面一些问题:
第一是性能的影响,由于一条记录可能存在在多个sstable中,最BT的情况下可能某一条记录会存在在所有sstable中,所以具体需要合并多个少sstable才能保证一条记录在所有sstable中只存了一次就变得不太确定了。
这种方式在存储空间上也比较浪费,因为一个被删除的记录可能的老版本可能会一直存在在一些老的sstable中,直到进行一次完整的合并才行。这对于一个经常会有删除操作的系统来说会造成空间的极大浪费。
在不怎么删除的系统上,也会造成一些空间的浪费,最坏的情况下,如果一条记录都没有重复,那么合并操作实际上完全是浪费时间,合并后的数据大小和合并前相比不会变,但是合并操作本身会需要和当前数据集一样大的空间成本。
新的压缩机制:Leveled Compaction
新的压缩机制借鉴自LevelDB,这种机制最大的特点在于其同一层的各个sstable之间不会有重复的数据。所以在某一层和它上一层的数据块进行合并时,可以明确的知道某个key值处在哪个数据块中,可以一个数据块一个数据块的合并,合并后生成新块就丢掉老块。不用一直到所有合并完成后才能删除老的块。
另外,新的分层式压缩方式将数据分成条个层,最底层的叫L0,其上分别是L1,L2….,每一层的数据大小是其上的那一层数据最大大小的10倍,其中最底层L0的大小为5M
如下图所未,当浅绿色的L0块生成时,它会马上和L1层的数据进行合并,并生成新的L1块(蓝色块),当L1的块越来越多,大于这一层的最大大小时,这些块又会和L2层的数据进行合并并生新的L2层的块(紫色块)
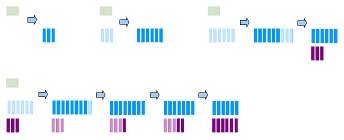
可以这样理解,层级越小的块,其保存的数据越少,也越新,比如L0层保存的就是最新的数据版本,但是其只会保存5M数据,其上的L1层会保存50M数据,但是并不是最新的。当一个系统运行的时间足够长,那么其数据结构可能会如下图所未:
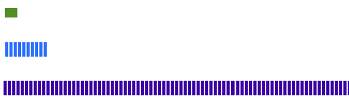
这种方式的优点是同一层的块之间没有重复数据,带来的好处就是在合并操作的时候,并不需要扫描一层中的所有数据块。合并的开销变小了。具体能够保证以下一些优点:
可以保证90%的读操作只需要对一个sstable进行随机读操作。而最坏情况下,也能保证读操作最大只会等于层数,如果10T数据的话,也只有七层,只需要七次随机读操作。
在空间利用上,可以保证最多只有10%的空间会浪费在无用数据上。
在压缩合并操作的开销上,也最多只会使用10倍于sstable大小的空间。
你可以通过在创建Column Family时指定compaction_strategy参数为LeveledCompactionStrategy来使用新的分层压缩策略。
当然,这种策略也不是万能的,对于一个更新操作和删除操作比较多的系统,使用分层压缩是比较合适的。因为这种系统会产生同一份数据的多个版本。但是由于这种压缩会在压缩中进行更多的IO操作,所以如果是一个主要是insert操作的系统,建议不要使用分层压缩方法。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
翻译
相关推荐
-
MongoDB与Cassandra数据库对比
MongoDB和Cassandra都属于NoSQL数据库系列,它们也恰好都是开源,但是,它们的相似之处仅此而已 […]
-
NoSQL性能管理仍不完备 你该如何应对?
NoSQL技术现在仍然处于相对初级的阶段,众多NoSQL软件类型和产品服务令人眼花缭乱,选择合适的性能管理方案也成为一件颇具挑战性的事。
-
NoSQL——未来数据库家族的一员
NoSQL是对数据库由内而外的全方位改造,从而创造出一个高容量、高速度和高可变性的架构。然而,NoSQL供应商在可变性部分却正在遭遇失败。
-
GPU技术仅局限于游戏领域?当心大数据应用的小船说翻就翻
GPU技术的使用是一些机器学习应用的前沿和核心。Facebook,百度、亚马逊和其他一些公司正在使用的GPU集群来研究深层神经网络相关的机器学习应用程序。