
redis是个内存全集的kv数据库,不存在部分数据在磁盘部分数据在内存里的情况,所以提前预估和节约内存非常重要.本文将以最常用的string和zipmap两类数据结构在jemalloc内存分配器下的内存容量预估和节约内存的方法.
先说说jemalloc,传说中解决firefox内存问题freebsd的默认malloc分配器,area,thread-cache功能和tmalloc非常的相识.在2.4版本被redis引入,在antirez的博文中提到内节约30%的内存使用.相比glibc的malloc需要在每个内存外附加一个额外的4字节内存块,jemalloc可以通过je_malloc_usable_size函数获得指针实际指向的内存大小,这样redis里的每个key或者value都可以节约4个字节,不少阿.
下面是jemalloc size class categories,左边是用户申请内存范围,右边是实际申请的内存大小.这张表后面会用到.
| 1 – 4 size class:4 5 – 8 size class:8 9 – 16 size class:16 17 – 32 size class:32 33 – 48 size class:48 49 – 64 size class:64 65 – 80 size class:80 81 – 96 size class:96 97 – 112 size class:112 113 – 128 size class:128 129 – 192 size class:192 193 – 256 size class:256 257 – 320 size class:320 321 – 384 size class:384 385 – 448 size class:448 449 – 512 size class:512 513 – 768 size class:768 769 – 1024 size class:1024 1025 – 1280 size class:1280 1281 – 1536 size class:1536 1537 – 1792 size class:1792 1793 – 2048 size class:2048 2049 – 2304 size class:2304 2305 – 2560 size class:2560 |
string
string类型看似简单,但还是有几个可优化的点.先来看一个简单的set命令所添加的数据结构.
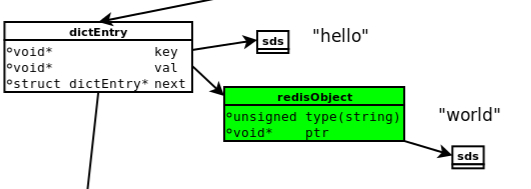
一个set hello world命令最终(中间会malloc,free的我们不考虑)会产生4个对象,一个dictEntry(12字节),一个sds用于存储key,还有一个redisObject(12字节),还有一个存储string的sds.sds对象除了包含字符串本生之外,还有一个sds header和额外的一个字节作为字符串结尾共9个字节.
| sds.c ======== 51 sds sdsnewlen(const void *init, size_t initlen) { 52 struct sdshdr *sh; 53 54 sh = zmalloc(sizeof(struct sdshdr)+initlen+1); sds.h ======= 39 struct sdshdr { 40 int len; 41 int free; 42 char buf[]; 43 }; |
根据jemalloc size class那张表,这个命令最终申请的内存为16(dictEtnry) + 16 (redisObject) + 16(“hello”) + 16(“world”),一共64字节.注意如果key或者value的字符串长度+9字节超过16字节,则实际申请的内存大小32字节.
提一下string常见的优化方法
尽量使value为纯数字
这样字符串会转化成int类型减少内存的使用.
| redis.c ========= 37 void setCommand(redisClient *c) { 38 c->argv[2] = tryObjectEncoding(c->argv[2]); 39 setGenericCommand(c,0,c->argv[1],c->argv[2],NULL); 40 } object.c ======= 275 o->encoding = REDIS_ENCODING_INT; 276 sdsfree(o->ptr); 277 o->ptr = (void*) value; |
可以看到sds被释放了,数字被存储在指针位上,所以对于set hello 1111111就只需要48字节的内存.
调整REDIS_SHARED_INTEGERS
如果value数字小于宏REDIS_SHARED_INTEGERS(默认10000),则这个redisObject也都节省了,使用redis Server启动时的share Object.
| object.c ======= 269 if (server.maxmemory == 0 && value >= 0 && value < REDIS_SHARED_INTEGERS && 270 pthread_equal(pthread_self(),server.mainthread)) { 271 decrRefCount(o); 272 incrRefCount(shared.integers[value]); 273 return shared.integers[value]; 274 } |
这样一个set hello 111就只需要32字节,连redisObject也省了.所以对于value都是小数字的应用,适当调大REDIS_SHARED_INTEGERS这个宏可以很好的节约内存.
出去kv之外,dict的bucket逐渐变大也需要消耗内存,bucket的元素是个指针(dictEntry**), 而bucket的大小是超过key个数向上求整的2的n次方,对于1w个key如果rehash过后就需要16384个bucket.
开始string类型的容量预估测试, 脚本如下
| #! /bin/bash redis-cli info|grep used_memory: for (( start = 10000; start < 30000; start++ )) do redis-cli set a$start baaaaaaaa$start > /dev/null done redis-cli info|grep used_memory: |
根据上面的总结我们得出string公式
string类型的内存大小 = 键值个数 * (dictEntry大小 + redisObject大小 + 包含key的sds大小 + 包含value的sds大小) + bucket个数 * 4
下面是我们的预估值
| >>> 20000 * (16 + 16 + 16 + 32) + 32768 * 4 1731072 |
运行一下测试脚本
| hoterran@~/Projects/redis-2.4.1$ bash redis-mem-test.sh used_memory:564352 used_memory:2295424 |
计算一下差值
| >>> 2295424 – 564352 1731072 |
都是1731072,说明预估非常的准确, ^_^
zipmap
这篇文章已经解释zipmap的效果,可以大量的节约内存的使用.对于一个普通的subkey和value,只需要额外的3个字节(keylen,valuelen,freelen)来存储,另外的hash key也只需要额外的2个字节(zm头尾)来存储subkey的个数和结束符.
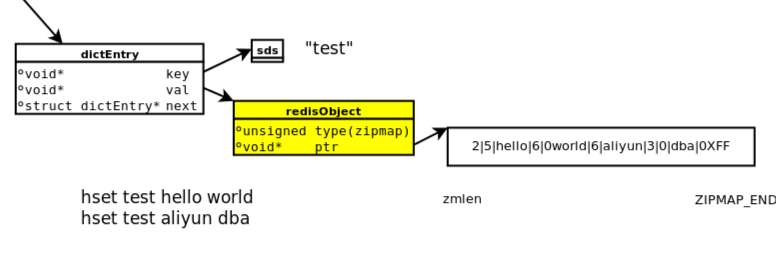
zipmap类型的内存大小 = hashkey个数 * (dictEntry大小 + redisObject大小 + 包含key的sds大小 + subkey的总大小) + bucket个数 * 4
开始容量预估测试,100个hashkey,其中每个hashkey里包含300个subkey, 这里key+value的长度为5字节
| #! /bin/bash redis-cli info|grep used_memory: for (( start = 100; start < 200; start++ )) do for (( start2 = 100; start2 < 400; start2++ )) do redis-cli hset test$start a$start2 “1” > /dev/null done done redis-cli info|grep used_memory: |
这里subkey是同时申请的的,大小是300 * (5 + 3) + 2 =2402字节,根据上面jemalloc size class可以看出实际申请的内存为2560.另外100hashkey的bucket是128.所以总的预估大小为
| >>> 100 * (16 + 16 + 16 + 2560) + 128 * 4 261312 |
运行一下上面的脚本
| hoterran@~/Projects/redis-2.4.1$ bash redis-mem-test-zipmap.sh used_memory:555916 used_memory:817228 |
计算一下差值
| >>> 817228 – 555916 261312 |
是的完全一样,预估很准确.
另外扯扯zipmap的一个缺陷,zipmap用于记录subkey个数的zmlen只有一个字节,超过254个subkey后则无法记录,需要遍历整个zipmap才能获得subkey的个数.而我们现在常把hash_max_zipmap_entries设置为1000,这样超过254个subkey之后每次hset效率都很差.
| 354 if (zm[0] < ZIPMAP_BIGLEN) { 355 len = zm[0]; //小于254,直接返回结果 356 } else { 357 unsigned char *p = zipmapRewind(zm); //遍历zipmap 358 while((p = zipmapNext(p,NULL,NULL,NULL,NULL)) != NULL) len++; 359 360 /* Re-store length if small enough */ 361 if (len < ZIPMAP_BIGLEN) zm[0] = len; 362 } |
简单把zmlen设置为2个字节(可以存储65534个subkey)可以解决这个问题,今天和antirez聊了一下,这会破坏rdb的兼容性,这个功能改进推迟到3.0版本,另外这个缺陷可能是weibo的redis机器cpu消耗过高的原因之一.
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
2017年1月数据库流行度排行榜 新年新气象
新年新气象,数据库知识网站DB-engines最近更新了2017年1月份数据库流行度榜单。TechTarget数据库网站将与您分享1月份的榜单排名情况,让我们拭目以待。
-
创建NoSQL数据建模符号 企业架构师亲自上阵
新兴的NoSQL数据风格促使创新的应用程序快速发展,但NoSQL同时也带来了挑战。NoSQL系统能够快速投入生产,有时甚至根本不用创建任何的前期模式。
-
深入理解Amazon DynamoDB NoSQL云数据库服务
Amazon DynamoDB NoSQL云数据库即服务主要为跨移动设备、网页web端、游戏、数字营销和物联网领域的应用提供支持。
-
2016年10月数据库流行度排行榜 两组数据库棋逢对手
数据库知识网站DB-engines更新了2016年10月份的数据库流行度排行榜,10月份的榜单又有哪些变化,哪些惊喜呢?