
本文是该系列文章的第二部分,点击阅读第一部分:由浅入深理解索引的实现
教科书上的B+Tree是一个简化了的,方便于研究和教学的B+Tree。然而在数据库实现时,为了更好的性能或者降低实现的难度,都会在细节上进行一定的变化。下面以InnoDB为例,来说说这些变化。
04 – Sparse Index中的数据指针
在“由浅入深理解索引的实现第一部分”中提到,Sparse Index中的每个键值都有一个指针指向所在的数据页。这样每个B+Tree都有指针指向数据页。如图Fig.1所示:
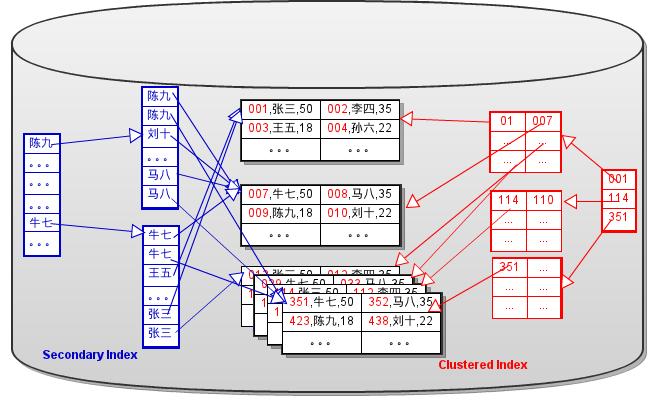
Fig.1
如果数据页进行了拆分或合并操作,那么所有的B+Tree都需要修改相应的页指针。特别是Secondary B+Tree(辅助索引对应的B+Tree), 要对很多个不连续的页进行修改。同时也需要对这些页加锁,这会降低并发性。
为了降低难度和增加更新(分裂和合并B+Tree节点)的性能,InnoDB 将 Secondary B+Tree中的指针替换成了主键的键值。如图Fig.2所示:
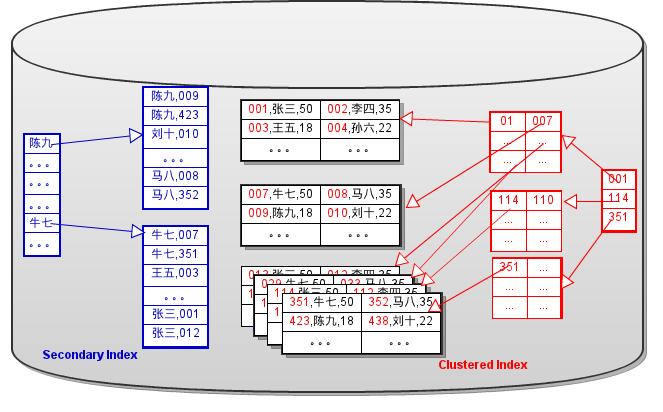
Fig.2
这样就去除了Secondary B+Tree对数据页的依赖,而数据就变成了Clustered B+Tree(簇索引对应的B+Tree)独占的了。对数据页的拆分及合并操作,仅影响Clustered B+Tree. 因此InnoDB的数据文件中存储的实际上就是多个孤立B+Tree。
接下来看一下数据操作在B+Tree上的基本实现。
- 用主键查询
直接在Clustered B+Tree上查询。
- 用辅助索引查询
A. 在Secondary B+Tree上查询到主键。
B. 用主键在Clustered B+Tree
可以看出,在使用主键值替换页指针后,辅助索引的查询效率降低了。
A. 尽量使用主键来查询数据(索引遍历操作除外).
B. 可以通过缓存来弥补性能,因此所有的键列,都应该尽量的小。
- INSERT
A. 在Clustered B+Tree上插入数据
B. 在所有其他Secondary B+Tree上插入主键。
- DELETE
A. 在Clustered B+Tree上删除数据。
B. 在所有其他Secondary B+Tree上删除主键。
- UPDATE 非键列
A. 在Clustered B+Tree上更新数据。
- UPDATE 主键列
A. 在Clustered B+Tree删除原有的记录(只是标记为DELETED,并不真正删除)。
B. 在Clustered B+Tree插入新的记录。
C. 在每一个Secondary B+Tree上删除原有的数据。(有疑问,看下一节。)
D. 在每一个Secondary B+Tree上插入原有的数据。
- UPDATE 辅助索引的键值
A. 在Clustered B+Tree上更新数据。
B. 在每一个Secondary B+Tree上删除原有的主键。
C. 在每一个Secondary B+Tree上插入原有的主键。
更新键列时,需要更新多个页,效率比较低。
A. 尽量不用对主键列进行UPDATE操作。
B. 更新很多时,尽量少建索引。
05 – 非唯一键索引
教科书上的B+Tree操作,通常都假设”键值是唯一的“。但是在实际的应用中Secondary Index是允许键值重复的。在极端的情况下,所有的键值都一样,该如何来处理呢?
InnoDB 的 Secondary B+Tree中,主键也是此键的一部分。
Secondary Key = 用户定义的KEY + 主键。如图Fig.3所示:
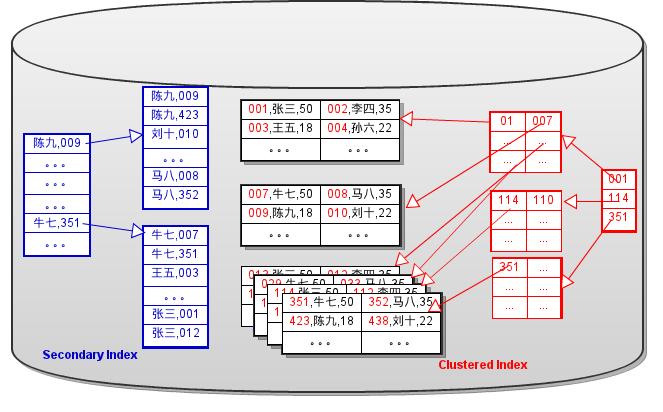
Fig.3
因为主键是唯一的,Secondary Key也是唯一的。按理说,如果辅助索引是唯一的,就不需要这样做。可是,InnoDB对所有的Secondary B+Tree都这样创建。当然,在插入数据时,还是会根据用户定义的Key,来判断唯一性。
06 – <Key, Pointer>对
标准的B+Tree的每个节点有K个键值和K+1个指针,指向K+1个子节点。如图Fig.4:
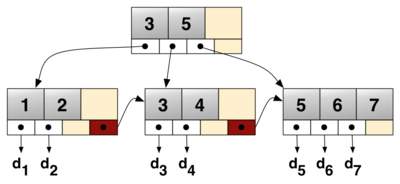
Fig.4(图片来自于WikiPedia)
而在“由浅入深理解索引的实现(1)”中Fig.9的B+Tree上,每个节点有K个键值和K个指针。InnoDB的B+Tree也是如此。如图Fig.5所示:
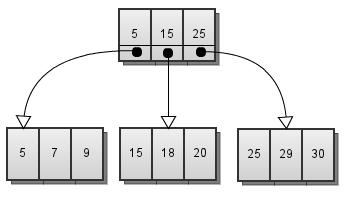
Fig.5
这样做的好处在于,键值和指针一一对应。我们可以将一个对看作一条记录。这样就可以用数据块的存储格式来存储索引块。因为不需要为索引块定义单独的存储格式,就降低了实现的难度。
- 插入最小值
当考虑在变形后的B+Tree上进行INSERT操作时,发现了一个有趣的问题。如果插入的数据的健值比B+Tree的最小键值小时,就无法定位到一个适当的数据块上去(中的Key代表了子节点上的键值是>=Key的)。例如,在Fig.5的B+Tree中插入键值为0的数据时,无法定位到任何节点。
在标准的B+Tree上,这样的键值会被定位到最左侧的节点上去。这个做法,对于Fig.5中的B+Tree也是合理的。Innodb的做法是,将每一层(叶子层除外)的最左侧节点的第一条记录标记为最小记录(MIN_REC).在进行定位操作时,任何键值都比标记为MIN_REC的键值大。因此0会被插入到最左侧的记录节点上。如Fig.6所示:
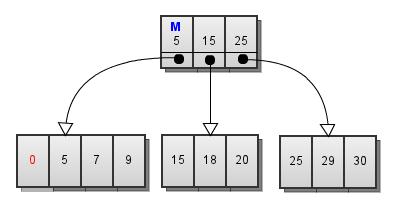
Fig.6
07 – 顺序插入数据
Fig.7是B-Tree的插入和分裂过程,我们看看有没有什么问题?
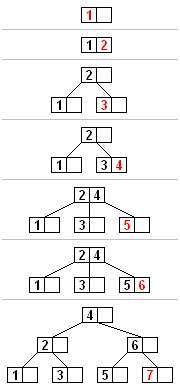
Fig.7(图片来自于WikiPedia)
标准的B-Tree分裂时,将一半的键值和数据移动到新的节点上去。原有节点和新节点都保留一半的空间,用于以后的插入操作。当按照键值的顺序插入数据时,左侧的节点不可能再有新的数据插入。因此,会浪费约一半的存储空间。
解决这个问题的基本思路是:分裂顺序插入的B-Tree时,将原有的数据都保留在原有的节点上。创建一个新的节点,用来存储新的数据。顺序插入时的分裂过程如Fig.8所示:
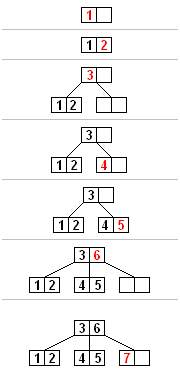
Fig.8
以上是以B-Tree为例,B+Tree的分裂过程类似。InnoDB的实现以这个思路为基础,不过要复杂一些。因为顺序插入是有方向性的,可能是从小到大,也可能是从大到小的插入数据。所以要区分不同的情况。如果要了解细节,可参考以下函数的代码。
| btr_page_split_and_insert(); btr_page_get_split_rec_to_right(); btr_page_get_split_rec_to_right(); |
InnoDB的代码太复杂了,有时候也不敢肯定自己的理解是对的。因此写了一个小脚本,来打印InnoDB数
据文件中B+Tree。这样可以直观的来观察B+Tree的结构,验证自己的理解是否正确。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
2017年5月数据库流行度排行榜 MySQL与Oracle“势均力敌”
数据库知识网站DB-engines.com最近更新了2017年5月的数据库流行榜单。TechTarget继续与您一起分享最新的榜单情况。
-
2017年3月数据库流行度排行榜 Oracle卫冕之路困难重重
时隔一个月,数据库市场经过一轮“洗牌”,旧的市场格局是否会被打破,曾经占巨大市场份额的企业是否可能失去优势?
-
2017年2月数据库流行度排行榜 攻城容易守城难
2016年下半年,数据库排行榜的前二十名似乎都“固守阵地”,在排名上没有太大的变动。随着2017年的悄然而至,数据库的排名情况是否会有新的看点?
-
MySQL管理特性:让企业适合交易平台
当Alexander Culiniac和他的同事在TickTrade系统公司建立一个基于云的交易平台时,面临一些基本的约束。那就是,系统必须在云上工作良好并且经济实用。