
微博上看到的一张关于HDFS的图片,形象生动的解释的HDFS的工作原理,再确切一点是 写操作的的基本过程:
1 一个集群中只有一个NameNode,可以有多个DataNodes
2 namenode 承担数据的位置存储信息,并将存储位置信息告诉client端!
3 得到位置信息后,client端开始写数据
4 写数据的时候是将数据分块,并存储为多份(一般为3份),放在不同的datanode 节点!
5 client 先将数据写到第一个节点,在第一个节点接收数据的同时,又将它所接收的数据推送到第二个,第二个推送到第三个节点,如果有多个节点,依次类推。。
6 从图中可以知道 NameNode 不参与 数据块的IO的!相当于mongodb 集群中的 mongos 和config 服务器的双重角色!
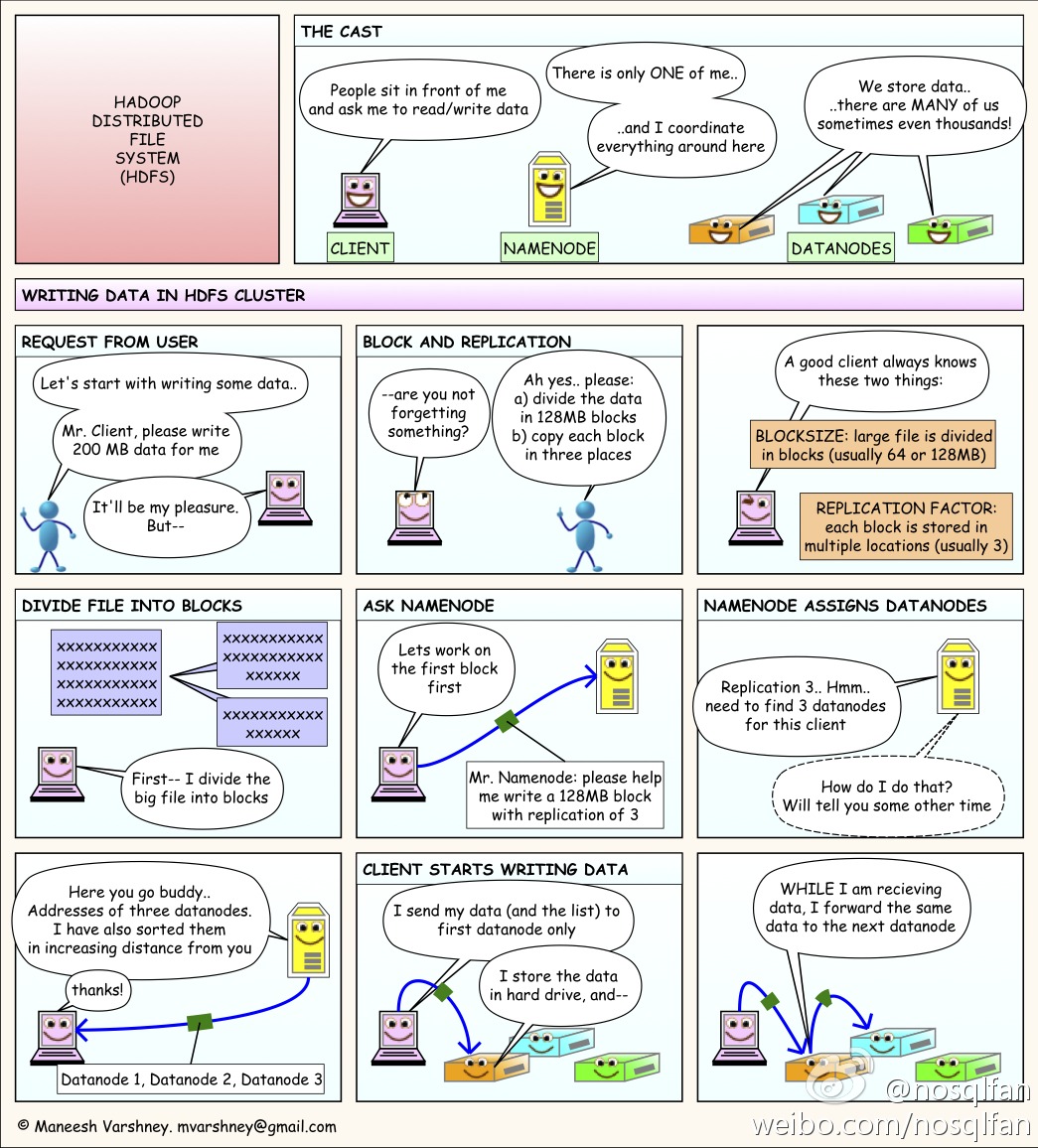
点击放大
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Cloudera-Hortonworks合并或将减少Hadoop用户的选择
近日大数据领域两家顶级供应商达成交易协议,这可能会影响Hadoop和其他开源数据处理框架,并使大数据用户的技术 […]
-
Azure数据湖分析从U-SQL中获得提升
大数据的发展已经让许多精通SQL的数据专业人员不知所措。微软的U-SQL编程语言试图让这些人回归数据查询游戏。
-
进入机器学习时代,数据库何去何从?
Vertica之前就已经能够对Hadoop数据进行访问,但Vertica8.0分析引擎则能够与Hadoop数据适当协作,如此一来就能减少数据迁移。
-
NoSQL——未来数据库家族的一员
NoSQL是对数据库由内而外的全方位改造,从而创造出一个高容量、高速度和高可变性的架构。然而,NoSQL供应商在可变性部分却正在遭遇失败。