
最近公司在MySQL的数据库上由于采用了高速的如PCIe卡以及大内存,去年在压力测试的时候突然发现数据库的流量可以把一个千M网卡压满了。随着数据库的优化,现在流量可以达到150M,所以我们采用了双网卡,在交换机上绑定,做LB的方式,提高系统的吞吐量。
但是在最近压测试的一个数据库中,mpstat发现其中一个核的CPU被软中断耗尽:
Mysql QPS 2W左右
| ——– —–load-avg—- —cpu-usage— —swap— -QPS- -TPS- -Hit%- time | 1m 5m 15m |usr sys idl iow| si so| ins upd del sel iud| lor hit| 13:43:46| 0.00 0.00 0.00| 67 27 3 3| 0 0| 0 0 0 0 0| 0 100.00| 13:43:47| 0.00 0.00 0.00| 30 10 60 0| 0 0| 0 0 0 19281 0| 326839 100.00| 13:43:48| 0.00 0.00 0.00| 28 10 63 0| 0 0| 0 0 0 19083 0| 323377 100.00| 13:43:49| 0.00 0.00 0.00| 28 10 63 0| 0 0| 0 0 0 19482 0| 330185 100.00| 13:43:50| 0.00 0.00 0.00| 26 9 65 0| 0 0| 0 0 0 19379 0| 328575 100.00| 13:43:51| 0.00 0.00 0.00| 27 9 64 0| 0 0| 0 0 0 19723 0| 334378 100.00| |
mpstat -P ALL 1说:
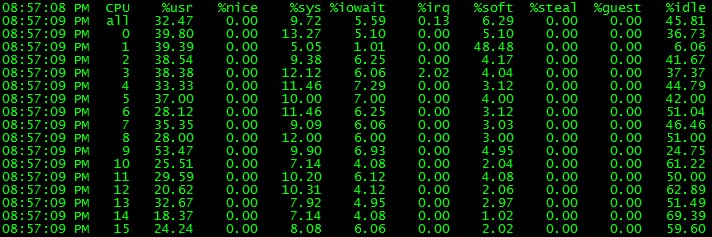
针对这个问题,我们利用工具,特别是systemtap, 一步步来调查和解决问题。
首先我们来确认下网卡的设置:
| $uname -r 2.6.32-131.21.1.tb399.el6.x86_64 $ lspci -vvvv 01:00.0 Ethernet controller: Broadcom Corporation NetXtreme II BCM5709 Gigabit Ethernet (rev 20) Subsystem: Broadcom Corporation NetXtreme II BCM5709 Gigabit Ethernet Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- Latency: 0, Cache Line Size: 256 bytes Interrupt: pin A routed to IRQ 114 Region 0: Memory at f6000000 (64-bit, non-prefetchable) [size=32M] Capabilities: <access denied> 01:00.1 Ethernet controller: Broadcom Corporation NetXtreme II BCM5709 Gigabit Ethernet (rev 20) Subsystem: Broadcom Corporation NetXtreme II BCM5709 Gigabit Ethernet Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- Latency: 0, Cache Line Size: 256 bytes Interrupt: pin B routed to IRQ 122 Region 0: Memory at f8000000 (64-bit, non-prefetchable) [size=32M] Capabilities: <access denied> $cat /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v3.6.0 (September 26, 2009) Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: em1 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Slave Interface: em1 MII Status: up Link Failure Count: 0 Permanent HW addr: 78:2b:cb:1f:eb:c9 Slave queue ID: 0 Slave Interface: em2 MII Status: up Link Failure Count: 0 Permanent HW addr: 78:2b:cb:1f:eb:ca Slave queue ID: 0 |
从上面的信息我们可以确认二块 Broadcom Corporation NetXtreme II BCM5709 Gigabit Ethernet (rev 20)网卡在做bonding。
我们的系统内核组维护的是RHEL 6.1, 很容易可以从/proc/interrupts和/proc/softirqs得到中断和软中断的信息的信息。
我们特别留意下softirq, 由于CPU太多,信息太乱,我只列出7个核心的情况:
| $cat /proc/softirqs|tr -s ‘ ‘ ‘t’|cut -f 1-8 CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 HI: 0 0 0 0 0 0 TIMER: 401626149 366513734 274660062 286091775 252287943 258932438 NET_TX: 136905 10428 17269 25080 16613 17876 NET_RX: 1898437808 2857018450 580117978 26443 11820 15545 BLOCK: 716495491 805780859 113853932 132589667 106297189 104629321 BLOCK_IOPOLL: 0 0 0 0 0 0 0 TASKLET: 190643874 775861235 0 0 1 0 SCHED: 61726009 66994763 102590355 83277433 144588168 154635009 HRTIMER: 1883420 1837160 2316722 2369920 1721755 1666867 RCU: 391610041 365150626 275741153 287074106 253401636 260389306 |
从上面我们粗粗可以看出网卡的软中断接收和发送都不平衡。
单单这些信息还不够,还是无法区别为什么一个核心被压垮了,因为我们的机器上还有个中断的大户:fusionIO PCIe卡,在过去的测试中该卡也会吃掉大量的CPU,所以目前无法判断就是网卡引起的,因而我们用stap来double check下:
| $cat i.stp global hard, soft, wq probe irq_handler.entry { hard[irq, dev_name]++; } probe timer.s(1) { println(“==irq number:dev_name”) foreach( [irq, dev_name] in hard- limit 5) { printf(“%d,%s->%dn”, irq, kernel_string(dev_name), hard[irq, dev_name]); } println(“==softirq cpu:h:vec:action”) foreach( 1 in soft- limit 5) { printf(“%d:%x:%x:%s->%dn”, c, h, vec, symdata(action), soft1); } println(“==workqueue wq_thread:work_func”) foreach( [wq_thread,work_func] in wq- limit 5) { printf(“%x:%x->%dn”, wq_thread, work_func, wq[wq_thread, work_func]); } println(“n”) delete hard delete soft delete wq } probe softirq.entry { soft[cpu(), h,vec,action]++; } probe workqueue.execute { wq[wq_thread, work_func]++ } probe begin { println(“~”) } $sudo stap i.stp ==irq number:dev_name 73,em1-6->7150 50,iodrive-fct0->7015 71,em1-4->6985 74,em1-7->6680 69,em1-2->6557 ==softirq cpu:h:vec:action 1:ffffffff81a23098:ffffffff81a23080:0xffffffff81411110->36627 1:ffffffff81a230b0:ffffffff81a23080:0xffffffff8106f950->2169 1:ffffffff81a230a0:ffffffff81a23080:0xffffffff81237100->1736 0:ffffffff81a230a0:ffffffff81a23080:0xffffffff81237100->1308 1:ffffffff81a23088:ffffffff81a23080:0xffffffff81079ee0->941 ==workqueue wq_thread:work_func ffff880c14268a80:ffffffffa026b390->51 ffff880c1422e0c0:ffffffffa026b390->30 ffff880c1425f580:ffffffffa026b390->25 ffff880c1422f540:ffffffffa026b390->24 ffff880c14268040:ffffffffa026b390->23 #上面软中断的action的符号信息: $addr2line -e /usr/lib/debug/lib/modules/2.6.32-131.21.1.tb411.el6.x86_64/vmlinux ffffffff81411110 /home/ads/build22_6u0_x64/workspace/kernel-el6/origin/taobao-kernel-build/kernel-2.6.32-131.21.1.el6/linux-2.6.32-131.21.1.el6.x86_64/net/core/ethtool.c:653 $addr2line -e /usr/lib/debug/lib/modules/2.6.32-131.21.1.tb411.el6.x86_64/vmlinux ffffffff810dc3a0 /home/ads/build22_6u0_x64/workspace/kernel-el6/origin/taobao-kernel-build/kernel-2.6.32-131.21.1.el6/linux-2.6.32-131.21.1.el6.x86_64/kernel/relay.c:466 $addr2line -e /usr/lib/debug/lib/modules/2.6.32-131.21.1.tb411.el6.x86_64/vmlinux ffffffff81079ee0 /home/ads/build22_6u0_x64/workspace/kernel-el6/origin/taobao-kernel-build/kernel-2.6.32-131.21.1.el6/linux-2.6.32-131.21.1.el6.x86_64/include/trace/events/timer.h:118 $addr2line -e /usr/lib/debug/lib/modules/2.6.32-131.21.1.tb411.el6.x86_64/vmlinux ffffffff8105d120 /home/ads/build22_6u0_x64/workspace/kernel-el6/origin/taobao-kernel-build/kernel-2.6.32-131.21.1.el6/linux-2.6.32-131.21.1.el6.x86_64/kernel/sched.c:2460 |
这次我们可以轻松的定位到硬中断基本上是平衡的,软中断都基本压在了1号核心上,再根据符号查找确认是网卡的问题。
好了,现在定位到了,问题解决起来就容易了:
1. 采用多队列万M网卡。
2. 用google的RPS patch来解决软中断平衡的问题, 把软中断分散到不同的核心去,参见这里.
我们还是用穷人的方案,写了个shell脚本来做这个事情:
| $cat em.sh #! /bin/bash for i in `seq 0 7` do echo f|sudo tee /sys/class/net/em1/queues/rx-$i/rps_cpus >/dev/null echo f|sudo tee /sys/class/net/em2/queues/rx-$i/rps_cpus >/dev/null done $sudo ./em.sh $mpstat -P ALL 1 |
就可以看到我们的成果:
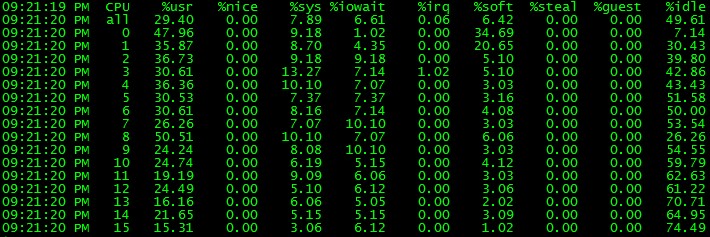
网卡的软中断成功分到二个核心上了,不再把一个核心拖死。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
如何在数据库应用中发挥SSD的优势
在数据库应用中发挥SSD技术的优势是具有挑战性的。本文列举了处理AWS应用的一些注意事项。
-
甲骨文宣布MySQL Cluster 7.4全面上市
甲骨文公司今天宣布MySQL Cluster 7.4全面上市。MySQL Cluster是一款ACID兼容的开源事务处理型数据库,具有实时内存性能和99.999%的可用性。
-
解读MySQL数据库的双向复制
在主-从复制中,主机影响从机。但从数据库中的任何更改不会影响主数据库,这篇文章将帮助你实现双向复制。
-
多种不同的MySQL数据库SSL配置
SSL通过加密网络防止有针对性的监听。在与正确的服务器进行交互时,可以有效应对中间人攻击。本文介绍了不同的使用MySQL数据库的SSL配置方法。