
hbase Coprocessor是很多人对hbase-0.92的重大期待之一。它让离线分析和在线应用很好地结合在了一起,另外也极大地拓展了hbase的应用丰富性,不再是简单的k-v类应用。hbase coprocessor的设计来源于hbase-2000和hbase-2001两个issue。那么几年过去了,hbase coprocessor究竟发展到什么程度,可以将它们用于哪些地方呢?下文主要内容来源于Trend Micro Hadoop Group的成员,同时也是hbase coprocessor的作者,不愿意看底下啰嗦废话的同学可以直接跳到最后面的总结看。
https://blogs.apache.org/hbase/entry/coprocessor_introduction
hbase coprocessor随着0.92的release而完整地release出来了,它的设计来源于google bigtable的coprocessor(Jeff Dean的一篇演讲)。coprocessor其实是一个类似mapreduce的分析组件,不过它极大简化了mapreduce模型,只是将请求独立地在各个region中并行地运行,并且提供了一套框架能够让用户非常灵活地编写自定义的coprocessor。hbase的coprocessor与google的coprocessor最大的区别是,hbase的coprocessor是一套在regionserver和master进程内的框架,可以在运行期动态执行用户的代码,而google的coprocessor则是拥有自己独立的进程和地址空间。看起来似乎hbase的coprocessor更加高效,但其实并非如此,拥有独立的地址空间的好处是可以通过与计算资源的绑定更高效地使用硬件,比如通过cgroup的方式绑定到独立的cpu上去工作。
现在hbase的coprocessor有两种完全不同的实现,分别是observer模式与endpoint模式,它们分别对应2000和2001两个issue。我们可以将observer模式看成数据库中的触发器,而endpoint可以看成是存储过程。
关于coprocessor我们可以从类继承关系上看到,如下图所示:
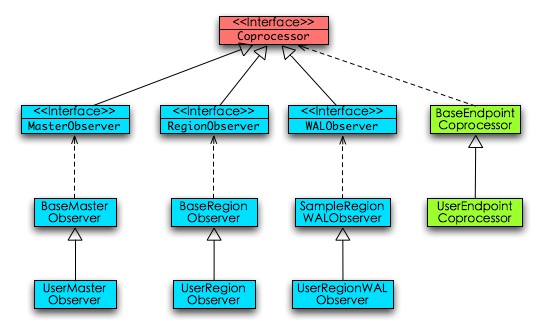
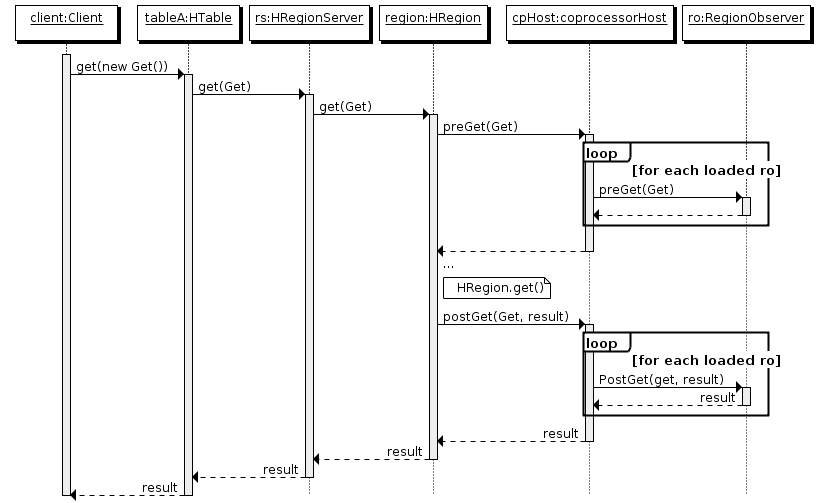
共有三个Observer对象,即MasterObserver,RegionObserver和WALObserver。它们的工作原理类似于钩子函数,在真实的函数实现前加入pre(),实现后加入post()方法,来实现对操作进行一些嵌入式的改变。效率上的影响仅仅取决于嵌入的钩子函数本身的影响。如下图所示:
比如下面这段代码就实现了在get之前做权限检查:
| publicclassAccessControlCoprocessorextends BaseRegionObserver { @Override public void preGet(final ObserverContext c, final Get get, final List result) throws IOException throws IOException { // check permissions.. if (!permissionGranted()) { thrownewAccessDeniedException(“User is not allowed to access.”); } } // override prePut(), preDelete(), etc. } |
在hbase的社区中,己经有很多人提出了各种基于Observer的实现方法,来做一些有意义的事。比如可以通过regionObserver实现刚才说的权限,还有故障隔离,优先级等工作。通过MasterObserver则可以实现对ddl操作的监控。通过WALObserver则可以实现二级索引、replication等工作。不过遗憾的是,很少有想法实现了,主要原因还是大家都比较忙,而相应的需求在现阶段还不强烈,所以留待后面来做。由于Observer框架的灵活性和扩展性,用户可以方便地自定义各种符合自己需求的实现。
BaseEndpoint类则是直接实现了Coprocessor接口,它实际上是client-side的实现,即客户端包装了一个HTable的实现,将类似于getMin()的操作包装起来,内部则通过并行scan等操作来实现。这就很类似一个简单的mapreduce,map就是在目标region server上的那些region,而reduce则是客户端。这个方法对于习惯于编写map reduce代码的人来说非常直观,可以很容易地实现sum,min等接口。由于这一层包装,可以屏蔽掉很多开发上的细节,让开发应用的人专注于开发应用,将底层实现交给mapreduce programmer。
一个简单的Endpoint例子如下:
| public T getMin(ColumnInterpreter ci, Scan scan) throws IOException { T min = null; T temp; InternalScanner scanner = ((RegionCoprocessorEnvironment) getEnvironment()) .getRegion().getScanner(scan); List results = new ArrayList(); byte[] colFamily = scan.getFamilies()[0]; byte[] qualifier = scan.getFamilyMap().get(colFamily).pollFirst(); try { boolean hasMoreRows = false; do { hasMoreRows = scanner.next(results); for (KeyValue kv : results) { temp = ci.getValue(colFamily, qualifier, kv); min = (min == null || ci.compare(temp, min) < 0) ? temp : min; } results.clear(); } while (hasMoreRows); } finally { scanner.close(); } log.info(“Minimum from this region is ” + ((RegionCoprocessorEnvironment) getEnvironment()).getRegion() .getRegionNameAsString() + “: ” + min); return min; } |
Coprocessor可以让用户随时加载自己实现的代码,而不需要重启系统。它可以通过配置来加载,也可以通过shell或java程序来加载。
总结:
- hbase coprocessor是脱胎于google bigtable coprocessor,区别是hbase coprocessor并非独立进程,而是在原来进程中嵌入框架
- hbase coprocessor的实现分为observer与endpoint,其中observer类似于触发器,主要在服务端工作,而endpoint类似于存储过程,主要在client端工作
- observer可以实现权限管理、优先级设置、监控、ddl控制、二级索引等功能,而endpoint可以实现min、mas、avg、sum等功能
- coprocessor可以动态加载
- coprocessor的性能取决于想要加载的方法的性能,不过为了有一个直观的了解,我们仍然近期打算对hbase coprocessor的一些典型场景做性能测试。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
OpenWorld18大会:Ellison宣布数据库的搜寻和破坏任务
在旧金山举行的甲骨文OpenWorld 2018大会中,甲骨文首席技术官(CTO)兼创始人Larry Elli […]
-
ObjectRocket着力发展Azure MongoDB服务
MongoDB吸引了微软公司的注意力,微软公司计划针对运行于该公司2017年发布的Azure Cosmos D […]
-
创建NoSQL数据建模符号 企业架构师亲自上阵
新兴的NoSQL数据风格促使创新的应用程序快速发展,但NoSQL同时也带来了挑战。NoSQL系统能够快速投入生产,有时甚至根本不用创建任何的前期模式。
-
深入理解Amazon DynamoDB NoSQL云数据库服务
Amazon DynamoDB NoSQL云数据库即服务主要为跨移动设备、网页web端、游戏、数字营销和物联网领域的应用提供支持。