
在所有先进的应用程序中,不管是购物站点还是社交网络乃至风景名胜站点,搜索都扮演着关键的角色。Lucene搜索程序库事实上已经成为实现搜索引擎的标准。苹果、IBM、Attlassian(Jira)、Wolfram以及很多大家喜欢的公司【1】都使用了这种技术。因此,大家对任何能够提升Lucene的可伸缩性和性能的实现都很感兴趣。
Lucene简介
Lucene中可搜索的实体都表现为文档(document),它由字段(field)和值(value)组成。每个字段值都由一个或多个可搜索的元素——即词汇(term)——组成。Lucene搜索基于反向索引,其中包含了关于可搜索文档的信息。在使用正常索引时,你可以搜索文档,以了解它包含哪些字段,但使用反向索引与之不同,你会搜索字段的词汇,以了解所有包括该词汇的文档。
图1显示的是高层次的Lucene架构【2】。它的主要组件包括IndexSearcher、IndexReader、IndexWriter 和Directory。IndexSearcher实现了搜索逻辑。IndexWriter为每个插入的文档写入反向索引。IndexReader会在IndexSearcher的支持下读取索引的内容。IndexReader和IndexWriter都依赖于Directory,它会提供操作索引数据集的API,而该API会直接模拟文件系统API。
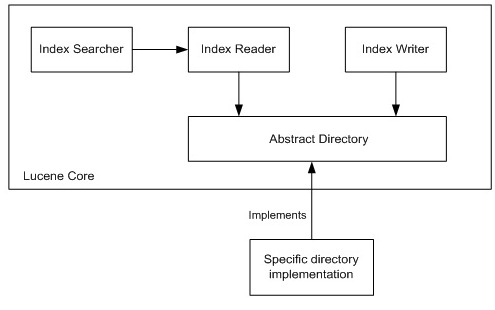
图1: 高层次的Lucene架构
标准的Lucene分发包中有多个目录实现,包括基于文件系统和基于内存的[1]。
标准基于文件系统的后端的缺点在于,随着索引增加性能会下降。人们使用了各种不同的技术来解决这个问题,包括负载均衡和索引分片(index sharding)——在多个Lucene实例之间切分索引。尽管分片功能很强大,但它让总体的实现架构变得更复杂,并且需要大量对期望文档的预测知识,才能对Lucene索引进行合适地分片。
另一种不同的方法是,让索引后端自身对数据进行正确地分片,并基于这样的后端构建出实现。这种后端可以是NoSQL数据库。在本文中我们会描述基于HBase的实现【4】。
实现方法
正如在【3】中所说明的,在高层次上,Lucene会操作两个单独的数据集:
- 索引数据集中保存了所有字段/词汇对(还有其他信息,像术语频率、位置等),以及在恰当的字段包含这些词汇的文档。
- 文档数据集中存储所有文档,包括存储的字段等。
正如我们已经在上面提到的,想要把Lucene移植到新的后端中,直接实现directory接口并不总会是最简单(最方便)的方法。所以,很多对Lucene的移植,包括从Lucene的contrib.module支持的优先内存索引、Lucandra【5】和HBasene【6】分别采用了不同的方法【2】,不仅重写了directory,还重写了高级的Lucene类——IndexReader和IndexWriter,从而绕开了Directory的API(如图2)。
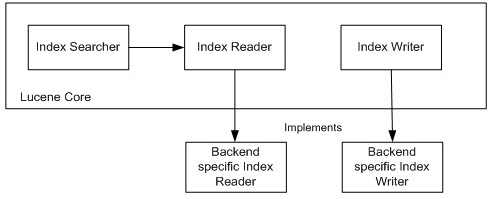
图2: 将Lucene和没有文件系统的后端整合
尽管这种方法通常需要更多工作【2】,但是它能够带来更强大的实现,让我们可以完全利用后端的本地功能。
文中所展现的实现[2]也遵循了这种方法。
总体架构
总体上的实现(如图3)是在基于内存的后端之上构建的,并将其用作内存缓存、同步缓存和HBase后端的机制。
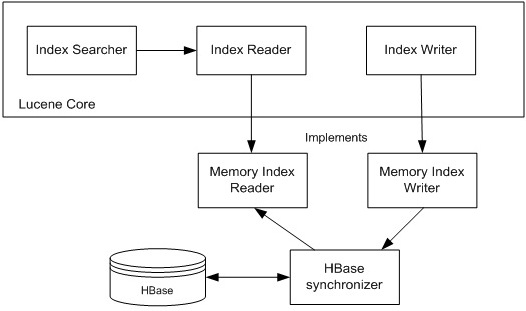
图3: 基于HBase的Lucene实现的总体架构
该实现试图平衡两种相互冲突的需求,性能: 在内存中,缓存能够最小化HBase用于搜索和文件返回的数据读取量,从而极大提升性能;可伸缩性: 按照需要运行为多个Lucene示例以支持日益增长的搜索客户端的能力。后者需要最小化缓存的生命周期,从而和HBase实例(上面提到实例的副本)中的内容同步。通过为活动参数实现可配置的缓存时间,限制每个Lucene实例中展现的缓存,我们可以达成一种折中方案。
内存缓存中的底层数据模型
正如之前所提到的,内部Lucene数据模型基于两种主要的数据集——索引和文档,它们会被实现为两种模型——IndexMemoryModel和DocumentMemoryModel。在我们的实现中,读写操作(IndexReader/IndexWriter)都是通过内存缓存完成的,但是它们的实现有很大区别。对于读取操作,缓存首先会检查所需要的数据是否在内存中,并且没有过期[3],如果那样的话就会直接使用。否则缓存就会从HBase读取或者刷新数据,然后把它返回给IndexReader。相反,对于写操作,数据会直接写入到HBase,而不会在内存中存储。尽管这在实际的数据可用性方面会有延迟,但是它会让实现过程非常简单——我们不需要考虑把新建或者更新的数据发送给哪个缓存。这里的延迟可以通过设置合适的缓存过期时间来控制,从而符合业务需求。
IndexMemoryModel
索引内存模型的类图如图4所示。
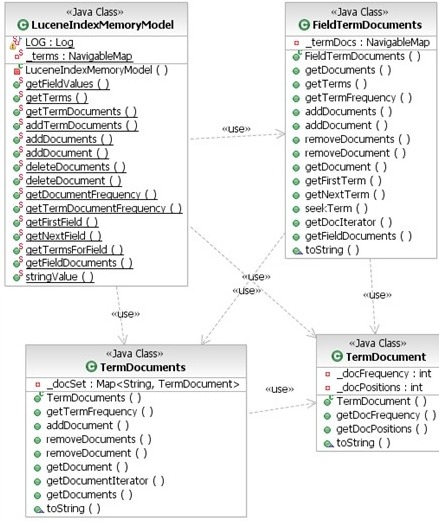
图4: IndexMemoryModel类图
在这个实现中:
- LuceneIndexMemoryModel类包含了当前存在于内存中所有字段的FieldTermDocuments类。它还提供了所有对于实现IndexReader和IndexWriter必要的内部API。
- FieldTermDocuments类会为每个字段值管理TermDocuments。通常,对于可扫描的数据库,字段的列表和字段值的列表可以组合在可导航的字段/词汇值列表中。对于基于内存的缓存实现,我们已经把它们切分为两个独立的部分,从而让搜索的时间更可预测。
- TermDocuments类为每个文档ID包含了一系列TermDocument类。
- TermDocument类包含了针对给定文档在索引中存储的信息——文档使用频度和位置的数组。
DocumentMemoryModel
文档内存模型的类图如图5所示。
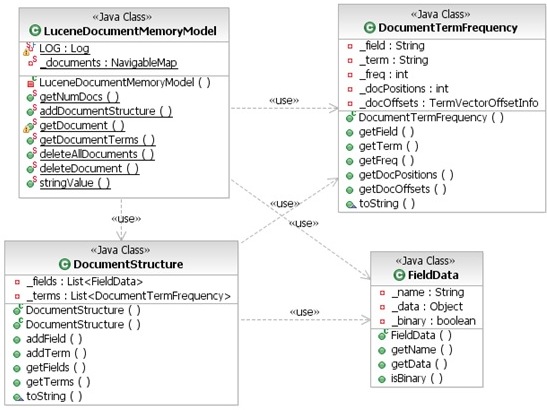
图5: DocumentMemoryModel类图
在这个实现中:
- LuceneDocumentMemoryModel类包含DocumentStructure类与每个被索引文档的映射关系。
- DocumentStructure类中包含了单个文档的信息。针对每个文档,它都包含了为每个索引后字段保存的字段和信息。
- FieldData类包含为存储字段(stored field)所保存的信息,包括字段名称、值和二进制或者字符串型的标识。
- DocumentTermFrequency类包含了关于每个被索引字段的信息,包括对相应索引结构(索引、词汇)的向后引用、文档中词汇使用频率、词汇在文档中的位置以及从文档开始的偏移量。
LuceneDocumentNormMemoryModel
正如在【9】中说明的,规范(norm)是用于表现文档或字段的加权因子,从而提供更好的搜索结果排序,这需要耗费大量内存。类的实现基于对映射的映射(map of maps),内部映射会存储规范和文档的映射关系,而外部映射会存储规范和字段的映射关系。
尽管规范信息的键值是字段名称,从而可以添加到LuceneIndexMemoryModel类中,但是我们还是决定把对规范的管理实现为单独的类——LuceneDocumentNormMemoryModel。这么做的原因在于,在Lucene使用规范是可选的操作。
IndexWriter
有了之前所描述的底层内存模型,实现索引写入程序就很简单了。因为Lucene不会定义IndexWriter接口,所以想要实现IndexWriter,我们需要实现所有标准Lucene实现中的方法。这个类的主要内容在于addDocument方法。这个方法会遍历所有文档的字段。对于每个字段,方法都会检查它是否可以令牌化(tokenized),并使用特定的分析器来做到这一点。这个方法还会更新所有三种内存结构——索引、文档和(可选的)规范,它们会为新增的文档存储信息。
IndexReader
IndexReader会实现Lucene核心所提供的IndexReader接口。因为Hbase中所获得的列表和单独的读操作相比要快很多,所以我们使用一些方法来扩展这个类,从而可以读取多个文档。类本身没有把更多的处理转交给几个类,它会对其进行管理:
- 尽管文档ID通常是字符串,但Lucene内部还是对整型数操作。DocIDManager这个类会负责管理从字符串到数字的转换。IndexReader会以ThreadLocalStorage的形式使用这个类,从而可以在线程结束之后自动清理。
- MemoryTermEnum类扩展了Lucene提供的TermEnum类,负责扫描字段/词汇的值。
- MemoryTermFrequencyVector类会实现Lucene提供的TermDocs和TermPositions接口,负责为给定的字段/词汇对(field/tem pair)处理与文档相关的信息。
- MemoryTermFrequencyVector类实现了Lucene提供的TermFreqVector和TermPositionVector接口,负责针对给定的文档ID返回文档字段频率和位置信息。
HBase表
以上提出的解决方案基于两个主要的HBase表——Index表(图6)和document表(图7)。
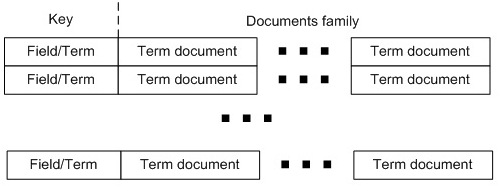
图6: HBase的Index表

图7: HBase的document表
如果需要支持规范的话,可选择实现第三个表(图8)。
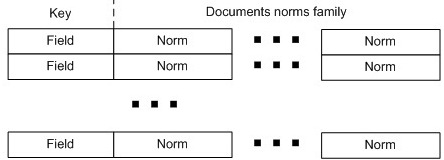
图8: HBase的norm表
HBase的Index表(图6)会完成实现的主要工作。这个表对每个Lucene实例所知道的字段/词汇组合都设置了入口,其中包含一个列族(column family)——documents族。这个列族为包含这个字段或词汇的所有文档都包含了一列(名称是文档的ID)。每个列的内容都是TermDocument类的值。
HBase的document表(图7)存储了文档本身、对索引或规范的向后引用,它会为文档处理引用这些文档以及一些Lucene使用的附加信息。它对所有Lucene实例知道的文档都设置了入口(row)。每个文档都通过文档ID(键值)唯一标识,并包含两个列族——字段族和索引族。字段列族针对所有存储在Lucene中的文档字段包含一列(名称为字段的名称)。列的值是值的类型(字符串或者字符数组)和值本身的组合。索引列族为每个引用这个文档的索引包含了一列(名称是字段或者术语)。列的值包括给定字段/词汇在文档的使用频率、位置和偏移量。
HBase的norm表(图8)为每个字段存储了文档的规范。它对所有Lucene实例知道的每个字段(键值)都设置了入口(行)。每行都只包含一个列族——规范族。这个族对每个需要存储给定字段规范的文档都有一列(名称是文档ID)。
数据格式
最终的设计方案确定了在HBase中存储数据的数据格式。对于这个实现,我们基于性能、结果数据的最小规模以及和Hadoop的紧密整合程度选择了Avro【10】。
实现主要使用的数据结构是TermDocument(代码1)、文档的FieldData(代码2)和DocumentTermFrequency(代码3)。
| { “type” : “record”, “name” : “TermDocument”, “namespace” : “com.navteq.lucene.hbase.document”, “fields” : [ { “name” : “docFrequency”, “type” : “int” }, { “name” : “docPositions”, “type” : [“null”, { “type” : “array”, “items” : “int” }] } ] } |
代码1 词汇文档AVRO定义
| { “type” : “record”, “name” : “FieldsData”, “namespace” : “com.navteq.lucene.hbase.document”, “fields” : [ { “name” : “fieldsArray”, “type” : { “type” : “array”, “items” : { “type” : “record”, “name” : “singleField”, “fields” : [ { “name” : “binary”, “type” : “boolean” }, { “name” : “data”, “type” : [ “string”, “bytes” ] } ] } } } ] } |
代码2 字段数据AVRO定义
| { “type” : “record”, “name” : “TermDocumentFrequency”, “namespace” : “com.navteq.lucene.hbase.document”, “fields” : [ { “name” : “docFrequency”, “type” : “int” }, { “name” : “docPositions”, “type” : [“null”,{ “type” : “array”, “items” : “int” }] }, { “name” : “docOffsets”, “type” : [“null”,{ “type” : “array”, “items” : { “type” : “record”, “name” : “TermsOffset”, “fields” : [ { “name” : “startOffset”, “type” : “int” }, { “name” : “endOffset”, “type” : “int” } ] } }] } ] } |
代码3 TermDocumentFrequency的AVRO定义
结论
本文中描述的简单实现完全支持所有Lucene功能,针对Lucene核心和普通模块的单元测试都验证了这一点。我们可以将它作为基础,构建可扩展性很强的搜索实现,支持HBase固有的可扩展性以及完全对称的设计,让我们可以添加任意数量服务于HBase数据的进程。它还可以避免需要关闭打开状态的Lucene索引读取程序,就可以包含新的索引数据,那会经过一定延迟之后为用户所用,而延迟是通过活动参数的缓存时间所控制的。在下一篇文章中我们会展示如何扩展这个实现,以包含地理搜索支持。
参考文献
Animesh Kumar. Apache Lucene and Cassandra
3. Animesh Kumar. Lucandra – an inside story!
Michael McCandless, Erik Hatcher, Otis Gospodnetic. Lucene in Action, Second Edition.
Boris Lublinsky. Using Apache Avro.
[1]附加的Lucene程序包含了为Berkley DB构建的DB目录。
[2]这个实现受到了Lusandra源代码【3】的启发。
[3]没有在内存中存在太长时间。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
OpenWorld18大会:Ellison宣布数据库的搜寻和破坏任务
在旧金山举行的甲骨文OpenWorld 2018大会中,甲骨文首席技术官(CTO)兼创始人Larry Elli […]
-
ObjectRocket着力发展Azure MongoDB服务
MongoDB吸引了微软公司的注意力,微软公司计划针对运行于该公司2017年发布的Azure Cosmos D […]
-
创建NoSQL数据建模符号 企业架构师亲自上阵
新兴的NoSQL数据风格促使创新的应用程序快速发展,但NoSQL同时也带来了挑战。NoSQL系统能够快速投入生产,有时甚至根本不用创建任何的前期模式。
-
深入理解Amazon DynamoDB NoSQL云数据库服务
Amazon DynamoDB NoSQL云数据库即服务主要为跨移动设备、网页web端、游戏、数字营销和物联网领域的应用提供支持。