
众所周知,BigTable是NoSQL数据库的王者,其论文更是NoSQL理论的基石,但遗憾的是BigTable不开源,于是有了开源的BigTable版本这一说法,其中的佼佼者包括今天提到的两位:Cassandra和HBase。
本文主要对Cassandra和HBase特性和实现中对BigTable理论的应用。
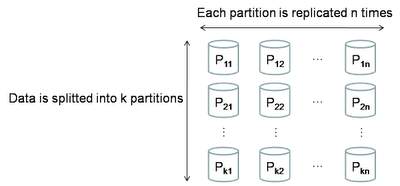
1.Fundamentally Distributed(分布式存储)
项目从最初规划上,就是为海量数据服务的,当然分布式存储的思想也是扎根于其血脉中。分布式系统主要需要考虑两个方面:partitioning(分区存储,也可以理解为通常说的Sharding)、replication(数据复制,主要是将数据复制成多份以提高可用性)。
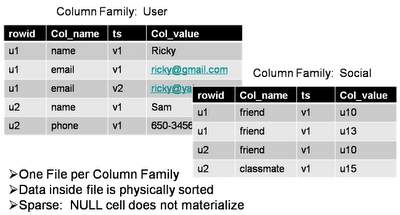
2.Column Oriented(列式存储)
和普通的RDBMS不一样,普通的RDBMS通常是行式存储的,一行数据是连续存在一段磁盘空间上的。而列式存储是将各个列分别进行连续的存储。也正是因此,它对于处理字段中的NULL字段,能够不占用过多的空间。同时能够支持灵活松散的列定义。也就是我们通常所说的schema-less。
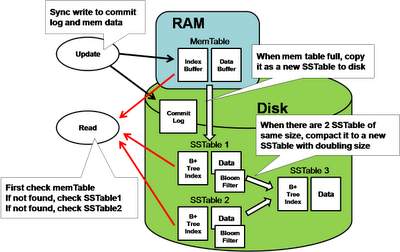
3.Sequential write(顺序写磁盘)
BigTable型系统的一个特点是其对写性能进行的优化。它的写都是通过先记一条操作日志,然后直接写在内存中的数据集合,然后其集合按条件或定时将数据flush到磁盘。这里涉及到的记操作日志或者数据flush到磁盘都会顺序的磁盘操作。故而避免了磁盘随机操作造成的无谓的磁盘寻道时间。
4.Merged read(读操作数据合并)
上面说到写操作是通过定时将数据直接flush到磁盘进行的,每次flush都会生成一个数据块,那可能造成一个数据在多个数据块中的情况,而在读的时候就需要将这多个版本中的值进行合并。其中在判断一个数据块是否包含指定值时使用了bloom-filter算法。
5.Periodic Data Compaction(定期数据合并)
同样是上面说到的,一个数据可能存在于多个数据块,如果我们不做处理,随着时间的推移,数据块会越来越多。所以BigTable型系统会进行定时的数据合并。在上面讲到的将内存中的数据直接flush到磁盘的过程中,flush之前进行了一次数据的排序操作,既是说存在磁盘中的块中的数据,都是顺序的,那么对一堆顺序的数据进行排重合并,其实和我们熟知的多路归并排序很相似。故而其定时数据合并的效率也是非常高的。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
MongoDB与Cassandra数据库对比
MongoDB和Cassandra都属于NoSQL数据库系列,它们也恰好都是开源,但是,它们的相似之处仅此而已 […]
-
创建NoSQL数据建模符号 企业架构师亲自上阵
新兴的NoSQL数据风格促使创新的应用程序快速发展,但NoSQL同时也带来了挑战。NoSQL系统能够快速投入生产,有时甚至根本不用创建任何的前期模式。
-
深入理解Amazon DynamoDB NoSQL云数据库服务
Amazon DynamoDB NoSQL云数据库即服务主要为跨移动设备、网页web端、游戏、数字营销和物联网领域的应用提供支持。
-
SQL和NoSQL数据库设计之争
企业收集了很多大规模增长的松散结构化数据,Hadoop,Spark以及其他新技术处理这些数据非常有助于改善商业智能分析效率。