
有两个表,表a
CREATE TABLE `a` (
`id` mediumint(8) unsigned NOT NULL AUTO_INCREMENT,
`fid` smallint(6) unsigned NOT NULL DEFAULT ‘0’,
`cnt` smallint(6) unsigned NOT NULL DEFAULT ‘0’,
…
…
…
PRIMARY KEY (`id`),
KEY `idx_fid` (`fid`),
) ENGINE=MyISAM DEFAULT CHARSET=utf8
表b
CREATE TABLE `b`
(`fid` smallint(6) unsigned NOT NULL AUTO_INCREMENT,
`name` char(50) NOT NULL DEFAULT ”,
…
…
…
PRIMARY KEY (`fid`),
) ENGINE=MyISAM DEFAULT CHARSET=utf8
操作SQL如下:
SELECT COUNT(*) AS num1, SUM(a.cnt)+COUNT(*) AS num2
FROM a, b
WHERE b.fid=’10913′ AND a.fid=b.fid
我们先看下执行计划:
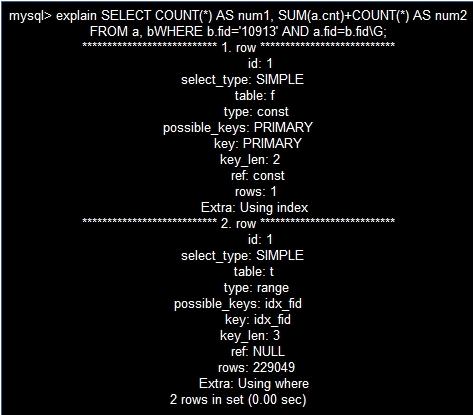
我们可以看到扫描行数是229049行,执行时间:
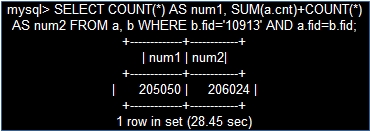
太可怕了,运行set profiling=1,让我们看看时间主要消耗在哪里?
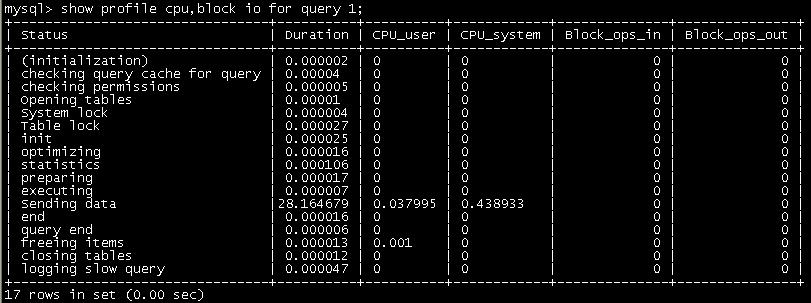
sending data花费的时间较长,那这段时间到底是做什么的呢?先看下这个吧:http://renxijun.blog.sohu.com/82906360.html
意思是它在为select语句准备数据,解决办法:
建索引:
create index idx_fid_cnt on a (fid,cnt);
再看下,执行计划和执行时间:
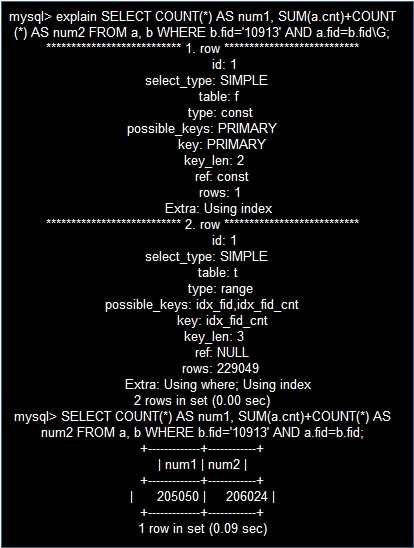
总结:使用恰当的索引,是sql的效率倍增,类似sum的函数还有min(),max(),这些都需要在字段上建索引。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
讲解MySQL中的降序索引
反向检索与正向检索的速度一样的快。但是在某些操作系统上面,并不支持反向的read-ahead预读,所以反向检索会略慢。
-
MySQL的B-Tree索引和Hash索引的区别
Hash索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问。