
当设计一个数据表时,考虑使用何种列的数据类型对性能有比较大的影响,如存储空间、查询开销等。甚至还影响到一些操作,如ip地址以字符串的形式存储在数据库中,就不可以直接比较大小。还有一点需要考虑,那就是可读性!数据虽然是存储在数据库中,但也要考虑到可读性问题。
本文要探讨的是“IP地址在数据库中,应该使用何种形式存储?”,文章将以实验为基础介绍使用何种形式比较适合。
1、感性认识
大家都知道ip地址分为ipv4、ipv6,这里我以ipv4为例介绍,ipv6原理是一样的。ipv4的小为32bits(或者说是4Bytes),在使用过程中,我们通常是用点分十进制格式,如192.168.120.65。如何把”192.168.120.65″存储到数据库中呢?
我们考虑下面三个因素:
- 可读性
- 存储效率
- 查询效率
把”192.168.120.65″存储到数据库中有多少中可行方法呢?见下表所示:
|
数据类型 |
大小 |
注释 |
|
varchar(15) |
占7~15字节 |
可读性最好(192.168.120.65),但是最费存储空间 |
|
bigint |
8 字节 |
可以将ip地址存储为类似192168120065的格式,这种可读性稍差,也比较费存储空间 |
|
int |
4 字节 |
这种可读性很差,会存储为1084782657,由192*16777216+168*65536+120*256+65-2147483648计算所得,占用存储空间少。 |
|
tinyint |
4 字节 |
用4个字段来分开存储ip地址,可读性稍差(分别为192, 168, 120, 65),存储空间占用少 |
|
varbinary(4) |
4 字节 |
可读性差(0xC0A87841),存储空间占用少 |
从大小来看,依次varchar(15)> bigint> int、tinyint、varbinary(4)。
从可读性来看,依次是varchar(15)> bigint> tinyint> varbinary(4)>int。
从查询效率来看,
综合考虑,似乎tinyint比较好,其次是varbinary(4)。但是tinyint需要占多个表字段,而varbinary只需要占用一个字段即可。正确性还有待下面的实验检查!!!
2、理性认识
本小节通过创建5张表,分别用上述5中数据类型存储ip地址,每张表插入1,000,000条记录。说明为了方便消除差异,这些表中插入的都是192.168.120.65。建表和插入数据的sql语句如下(说明:插入1,000,000条记录要花挺长时间的,如果你要自己实验,可以考虑少插入点数据):
建表和插入数据的sql语句
|
create database ip_address_test; go |
然后我们执行存储过程sp_spaceused查看空间效率,执行下面的sql语句:
| exec sp_spaceused ip_address_varchar exec sp_spaceused ip_address_bigint exec sp_spaceused ip_address_int exec sp_spaceused ip_address_tinyint exec sp_spaceused ip_address_varbinary |
可以得到下面的结果:
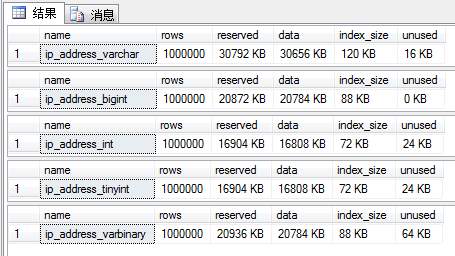
说明:上面各个字段的意思如下表所示
列名数据类型说明
reservedvarchar(18)由数据库中对象分配的空间总量。
datavarchar(18)数据使用的空间总量。
index_sizevarchar(18)索引使用的空间总量。
unusedvarchar(18)为数据库中的对象保留但尚未使用的空间总量。
可以看出,这5张表中的记录都是1000000,ip_address_varchar占空间最大30792 KB;其次是ip_address_bigint和ip_address_varbinary占用16904 KB;最后是ip_address_int和ip_address_tinyint只占用16904 KB。
所以从可读性和空间效率上来看,最理想的是用tinyint的数据类型存储ip地址。其次应该考虑varbinary(4)和bigint。
理论上bigint肯定要比varbinary占用空间多,可是实验得出来是一样的,为什么呢?我查看帮助信息也没有看出什么异常,varbinary(4)的确是占用4个字节、bigint也的确是占用8个字节,如下图
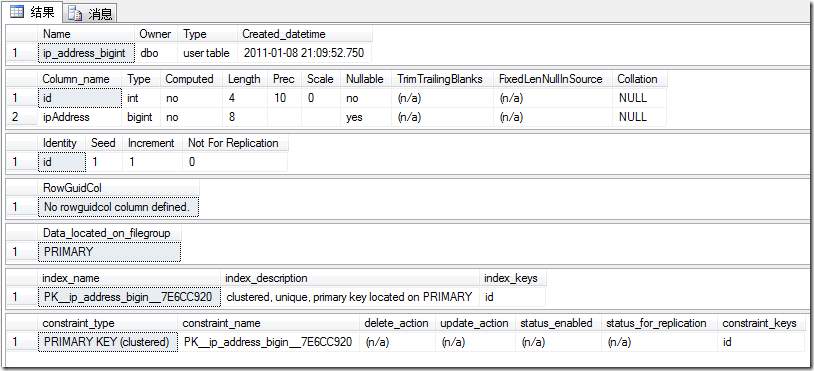
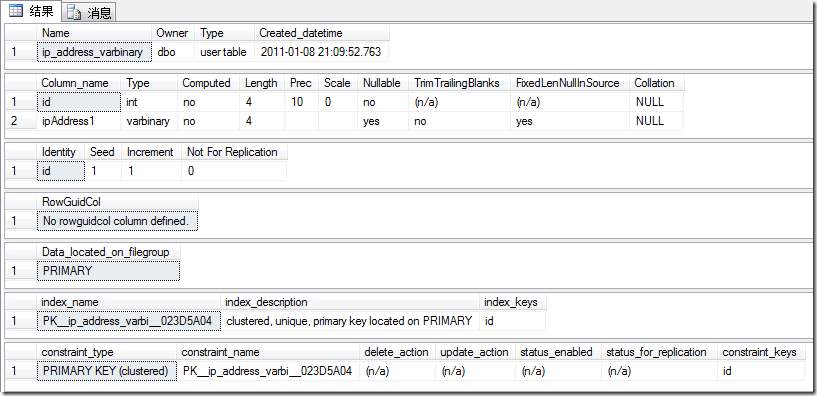
如果有知道的,请告诉我一声!不过让我从这两者之间选(信不过数据结果啊),肯定会选择使用varbinary(4)而不是bigint。如果能够证明数据结果没有错,应该选择bigint,因为他的可读性更好!
3、查询效率
本小节比较上述5中存储ip地址的查询效率。为了比较查询效率,这里重新插入数据,消除每张表中的记录都相同(192.168.120.65),下面编写存储过程像数据表中随机插入1000条记录(但是保证每张表的数据是一样的)。存储过程如下:
随机插入N条ip地址到5张表中
| use ip_address_test declare @ip1 tinyint, @ip2 tinyint, @ip3 tinyint, @ip4 tinyint, @i int set @i = 1 while @i <= 1000 begin set @ip1 = FLOOR(256*RAND(cast(cast(left(newid(),8) as varbinary ) as int )) ) set @ip2 = FLOOR(256*RAND(cast(cast(left(newid(),8) as varbinary ) as int )) ) set @ip3 = FLOOR(256*RAND(cast(cast(left(newid(),8) as varbinary ) as int )) ) set @ip4 = FLOOR(256*RAND(cast(cast(left(newid(),8) as varbinary ) as int )) ) /**** insert into ip_address_varchar ****/ declare @ip_varchar varchar(15) set @ip_varchar = cast(@ip1 as varchar)+’.’+ cast(@ip2 as varchar)+’.’+ cast(@ip3 as varchar)+’.’+ cast(@ip4 as varchar) insert into ip_address_varchar values(@ip_varchar) /**** insert into ip_address_bigint ****/ declare @ip_bigint bigint set @ip_bigint = convert( bigint, right(‘000’+convert(varchar(3), @ip1),3)+ right(‘000’+convert(varchar(3), @ip2),3)+ right(‘000’+convert(varchar(3), @ip3),3)+ right(‘000’+convert(varchar(3), @ip4),3) ) insert into ip_address_bigint values(@ip_bigint) /**** insert into ip_address_int ****/ declare @ip_int int set @ip_int = cast( (cast(@ip1 as bigint)*16777216)+ (cast(@ip2 as bigint)*65536)+ (cast(@ip3 as bigint)*256)+ cast(@ip4 as bigint) -2147483648 as int) insert into ip_address_int values(@ip_int) /**** insert into ip_address_tinyint ****/ insert into ip_address_tinyint values(@ip1,@ip2,@ip3,@ip4) /**** insert into ip_address_varbinary ****/ declare @ip_varbinary varbinary(4) set @ip_varbinary = cast( convert(tinyint, @ip1) as varbinary)+ cast( convert(tinyint, @ip2) as varbinary)+ cast( convert(tinyint, @ip3) as varbinary)+ cast( convert(tinyint, @ip4) as varbinary) insert into ip_address_varbinary values(@ip_varbinary) set @i = @i + 1 end |
考虑查找在范围192.0.0.0~192.255.255.255之间的ip地址的查询效率问题。说明我忽略了预处理的开销,即将192.0.0.0和192.255.255.255转换为上述的5种类型的时间,代码中我直接使用了这些值,没有给出转换过程,具体代码如下:
查询192.0.0.0~192.255.255.255之间的ip地址
| set statistics profile on set statistics io on set statistics time on /**** find from ip_address_varchar ****/ select * from ip_address_varchar where( cast(parsename(ipAddress, 4) as int) between 192 and 192 and cast(parsename(ipAddress, 3) as int) between 0 and 255 and cast(parsename(ipAddress, 2) as int) between 0 and 255 and cast(parsename(ipAddress, 1) as int) between 0 and 255 ) set statistics profile off set statistics io off set statistics time off set statistics profile on set statistics io on set statistics time on /*****find from ip_address_bigint*****/ select * from ip_address_bigint where( ipAddress between 192000000000 and 192255255255 ) set statistics profile off set statistics io off set statistics time off set statistics profile on set statistics io on set statistics time on /*****find from ip_address_int*****/ select * from ip_address_int where( ipAddress between 1073741824 and 1090519039 ) set statistics profile off set statistics io off set statistics time off set statistics profile on set statistics io on set statistics time on /*****find from ip_address_tinyint*****/ select * from ip_address_tinyint where( ip_address1 between 192 and 192 and ip_address2 between 0 and 255 and ip_address3 between 0 and 255 and ip_address4 between 0 and 255 ) set statistics profile off set statistics io off set statistics time off set statistics profile on set statistics io on set statistics time on /*****find from ip_address_varbinary*****/ select * from ip_address_varbinary where( ipAddress1 between 0xC0000000 and 0xC0FFFFFF ) set statistics profile off set statistics io off set statistics time off |
执行得到的消息如下:
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
(5 行受影响)
表 ‘ip_address_varchar’。扫描计数 1,逻辑读取 6 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(3 行受影响)
(1 行受影响)
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 113 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
=============================共115毫秒,ip_address_varchar
(5 行受影响)
表 ‘ip_address_bigint’。扫描计数 1,逻辑读取 5 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(2 行受影响)
(1 行受影响)
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
===================================共4毫秒,ip_address_bigint
(5 行受影响)
表 ‘ip_address_int’。扫描计数 1,逻辑读取 5 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(2 行受影响)
(1 行受影响)
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 146 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
===================================共149毫秒,ip_address_int
(5 行受影响)
表 ‘ip_address_tinyint’。扫描计数 1,逻辑读取 5 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(2 行受影响)
(1 行受影响)
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 85 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
=======================================共88毫秒,ip_address_tinyint
(5 行受影响)
表 ‘ip_address_varbinary’。扫描计数 1,逻辑读取 5 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(2 行受影响)
(1 行受影响)
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 13 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
===================================共15毫秒,ip_address_varbinary
上述结果只是初略的估计了效率,可能不太精确,但还是具有一定参考价值的!我只看ip_address_varbinary(15毫秒)、ip_address_tinyint(88毫秒)、ip_address_bigint(4毫秒)。
效率差距还是挺大的,综合可读性、存储效率、查询效率,我给这三者排序是:
如果考虑存储效率,tinyint是最好的!其次是bigint,然后是varbinary(4)
如果更多的是考虑查询效率,bigint是最好的!其次是varbinary(4),然后是tinyint
如果加我选择,我会使用varbinary(4)。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Notre Dame对云端SQL Server性能基准的探索实践
确立SQL Server的性能基准,对于云端迁移来说是至关重要的第一步,一位来自于University of Notre Dame 的DBA表示,他正在试图通过数据库监控软件,找出SQL server的性能基准。
-
DBA必须掌握的数据库恢复管理技术
如果没有备份副本,数据库管理员就无法还原数据库,所以DBA在恢复之前倾向于考虑备份是合乎逻辑的。 但是,对我来说,这种逻辑一直是错误的。
-
表征数据库性能问题的三个指标
即使数据库结构定义和SQL代码编写非常完美,应用程序性能都可能下降。如果性能问题不能得到及时纠正,那么就可能为公司带来很大的损失。
-
DBA也要和领导抢饭碗?
数据库架构师Ziaul Mannan 认为,DBA有成为高管的潜在可能,而这种潜力在过去往往被忽视,他还将证明DBA技能到领导力的转变是可行的。