
1.Hadoop’s SequenceFile

SequenceFile 是 Hadoop 的一个重要数据文件类型,它提供key-value的存储,但与传统key-value存储(比如hash表,btree)不同的是,它是appendonly的,于是你不能对已存在的key进行写操作。每一个key-value记录如下图,不仅保存了key,value值,也保存了他们的长度。
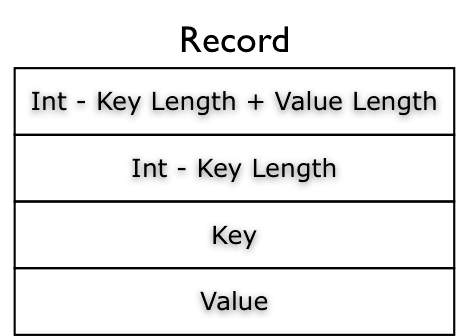
SequenceFile 有三种压缩态:
- Uncompressed – 未进行压缩的状态
- Record Compressed – 对每一条记录的value值进行了压缩(文件头中包含上使用哪种压缩算法的信息)
- Block-Compressed – 当数据量达到一定大小后,将停止写入进行整体压缩,整体压缩的方法是把所有的keylength,key,vlength,value 分别合在一起进行整体压缩
文件的压缩态标识在文件开头的header数据中。
在header数据之后是一个Metadata数据,他是简单的属性/值对,标识文件的一些其他信息。Metadata 在文件创建时就写好了,所以也是不能更改的。

2.MapFile, SetFile, ArrayFile 及 BloomMapFile
SequenceFile 是Hadoop 的一个基础数据文件格式,后续讲的 MapFile, SetFile, ArrayFile 及 BloomMapFile 都是基于它来实现的。
MapFile – 一个key-value 对应的查找数据结构,由数据文件/data 和索引文件 /index 组成,数据文件中包含所有需要存储的key-value对,按key的顺序排列。索引文件包含一部分key值,用以指向数据文件的关键位置。
SetFile – 基于 MapFile 实现的,他只有key,value为不可变的数据。
ArrayFile – 也是基于 MapFile 实现,他就像我们使用的数组一样,key值为序列化的数字。
BloomMapFile – 他在 MapFile 的基础上增加了一个 /bloom 文件,包含的是二进制的过滤表,在每一次写操作完成时,会更新这个过滤表。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Cloudera-Hortonworks合并或将减少Hadoop用户的选择
近日大数据领域两家顶级供应商达成交易协议,这可能会影响Hadoop和其他开源数据处理框架,并使大数据用户的技术 […]
-
Azure数据湖分析从U-SQL中获得提升
大数据的发展已经让许多精通SQL的数据专业人员不知所措。微软的U-SQL编程语言试图让这些人回归数据查询游戏。
-
创建NoSQL数据建模符号 企业架构师亲自上阵
新兴的NoSQL数据风格促使创新的应用程序快速发展,但NoSQL同时也带来了挑战。NoSQL系统能够快速投入生产,有时甚至根本不用创建任何的前期模式。
-
深入理解Amazon DynamoDB NoSQL云数据库服务
Amazon DynamoDB NoSQL云数据库即服务主要为跨移动设备、网页web端、游戏、数字营销和物联网领域的应用提供支持。