
Flume是Cloudera提供的日志收集系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
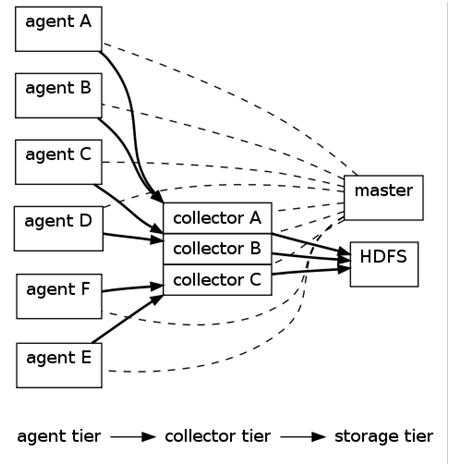
上图的Flume的Architecture,在Flume中,最重要的抽象是data flow(数据流),data flow描述了数据从产生,传输、处理并最终写入目标的一条路径。在上图中,实线描述了data flow。
其中,Agent用于采集数据,agent是flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector。对应的,collector用于对数据进行聚合,往往会产生一个更大的流。
Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。同时,Flume的数据接受方,可以是console(控制台)、text(文件)、dfs(HDFS文件)、RPC(Thrift-RPC)和syslogTCP(TCP syslog日志系统)等。
其中,收集数据有2种主要工作模式,如下:
Push Sources:外部系统会主动地将数据推送到Flume中,如RPC、syslog。
Polling Sources:Flume到外部系统中获取数据,一般使用轮询的方式,如text和exec。
注意,在Flume中,agent和collector对应,而source和sink对应。Source和sink强调发送、接受方的特性(如数据格式、编码等),而agent和collector关注功能。
Flume Master用于管理数据流的配置,如下图。
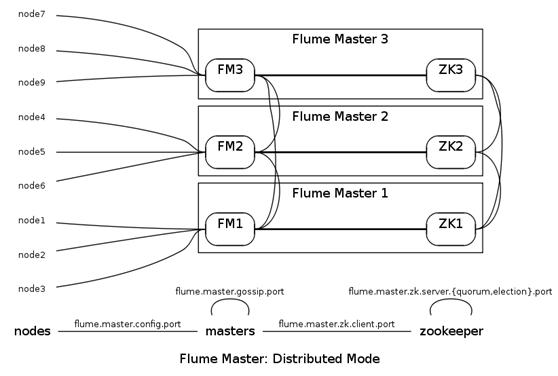
为了保证可扩展性,Flume采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。
Flume Master间使用gossip协议同步数据。
下面简要分析Flume如何支持Reliability、Scalability、Manageability和Extensibility。
Reliability:Flume提供3中数据可靠性选项,包括End-to-end、Store on failure和Best effort。其中End-to-end使用了磁盘日志和接受端Ack的方式,保证Flume接受到的数据会最终到达目的。Store on failure在目的不可用的时候,数据会保持在本地硬盘。和End-to-end不同的是,如果是进程出现问题,Store on failure可能会丢失部分数据。Best effort不做任何QoS保证。
Scalability:Flume的3大组件:collector、master和storage tier都是可伸缩的。需要注意的是,Flume中对事件的处理不需要带状态,它的Scalability可以很容易实现。
Manageability:Flume利用ZooKeeper和gossip,保证配置数据的一致性、高可用。同时,多Master,保证Master可以管理大量的节点。
Extensibility:基于Java,用户可以为Flume添加各种新的功能,如通过继承Source,用户可以实现自己的数据接入方式,实现Sink的子类,用户可以将数据写往特定目标,同时,通过SinkDecorator,用户可以对数据进行一定的预处理。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Cloudera:2016年Hadoop的三大预测
Cloudera近日举行了Hadoop十周年暨Cloudera新春媒体见面会。Cloudera全球副总裁大中华区总经理凌琦分享了Hadoop及其演变的历史, 阐述了Cloudera商业模式和行业领先地位,以及Hadoop在2016年的展望。
-
NoSQL效应与对可扩展数据库的需求
企业中非结构化数据的崛起正在推动NoSQL数据库技术的需求,但你还没有必要完全放弃SQL数据库。
-
阿里正祥解读OceanBase为何没有做成全内存数据库
在这篇文章中,OceanBase的掌门人阳振坤解释了为什么OceanBase可以把一天的修改增量置于内存,以及为什么OceanBase没有做成全内存数据库(如VoltDB,MemSQL)。
-
Cloudera CEO:ODP是对Apache社区的公然侮辱
Cloudera公司CEO Tom Reilly在接受TechTarget记者采访时就表示:ODP项目是对Apache软件基金会的公然侮辱。