
简介
众所周知,对于海量数据的schema修改是一个极其昂贵的代价,MySQL分表的很大原因其实就有500w数据一个表,DDL会比较快。
一般来说,动态schema是指的非固定表结构,schema字段(有时也指索引)的增删对于正常的读写没有任何影响。一般有两个方向的表现形式:
- Online Schema Change
- Schema-Free
NoSQL中一般采用后者,而关系型数据库可能会采用前者,两者的区别是,前者虽然是固定表结构,但是可以通过一定的方式进行在线修改,同时尽可能不影响服务,而后者是原生支持动态schema,是很多NoSQL产品所支持的feature之一,也是它们之于开源关系型数据库的优势所在。下面我将就目前比较通用的动态schema解决方案就一一介绍。
OSC
OSC即Online Schema Change,是Facebook出的一个在线修改Schema的PHP脚本,它解决了MySQL长期以来无法在线进行Schema变更的一大难题,也成功将Facebook曾经添加一个索引需要几个月的滚动升级,变成了现在的几天。
OSC目前包含以下几个步骤:
- copy:制造一个表的副本
- build:在副本上进行修改,直到它满足新的schema
- replay:将原始表的变更传播到副本上
- cut-over:切换原始表和副本,这需要极短时间的downtime,同时还需要一次replay操作
看到这个步骤,或许很多人都觉得简单,其实实践过程还是比较复杂的,有兴趣的人可以去看看,这里不做过多介绍。
http://www.facebook.com/notes/mysql-at-facebook/online-schema-change-for-mysql/430801045932
总之,对于关系型数据库来说一般都是采用的Online Schema Change这种解决方案,商业数据库Oracle和DB2都有比较和谐的Online Schema Change解决方案,但是考虑到其成本,这里不做过多介绍了。
优点:在线变更,无额外空间消耗
Schema-free
一般来说,文档数据库(Document-orient Database)支持Schema-Free,就mongodb来说,它的一行记录可能是以下格式:
Xml代码
{name:”mongo”,type:”db”,”x” : 4, “j” : 1}
严格来说其实就是JSON,不过mongo采用的是BSON二进制编码,因此空间上来说应该会比JSON省一些的。
因此,对于这种类型的动态schema方式来说,实际是使用key/value存储的,一条记录的多个字段实际是用json方式合并存在value中。解析的时候按照JSON解析即可,不好的地方是有额外的空间消耗,也许有点人觉得把字段名取为一个字母,但是这样可读性就太差了。
优点:完全的schema-free,无需任何改变,适用于及其复杂多变的业务。
Any More?
这里补充一点,看到有朋友对于此实现有疑问,这里所说的schema-less是针对的key-value存储,不针对mysql数据库,
MySQL还是建议使用OSC。
看完前面的两种解决方案,很多人或许就会觉得,是不是NoSQL鼓吹的动态Schema就是一个笑话呢?把字段存到数据库里面,谁都可以做啊,其实不然,让我们看看另外一个解决方案。这个方案好不好,大家看完后评价。
举例说明,对于下面一个Schema:

我们对于这样一个Schema,其元数据信息应该是什么样的呢?
首先对于我们的元数据做如下定义:
这里的这个元数据信息是对于某一个schema来说的,依次是一个SchemaId,然后是Name(可以理解为表名),然后是当前schema的代数,其实就是一个类似于版本的东西,初始为0,最后一个是创建或修改时间,还有一些其它信息,这里省略掉。

下面是对于字段的一些元数据,两者通过SchemaId关联,包含了所对应的Schema,在schema中的顺序(解析的时候用),类型,是否为空,是否为主键啊之类的。
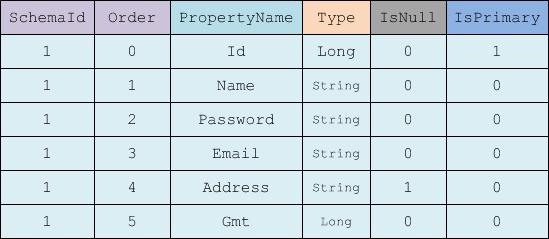
我们有了这些元数据信息以后可以做什么呢?
对于我们的一行记录,我们理解为一串二进制字节码,如何从这串字节码中解析我们的字段呢,依靠的就是这些元数据,下面我将物理上存储的格式贴出来,大家就明白了:

大家注意看,物理上我们存储了一个Generation字段来标识当前的Schema是属于该schema的哪个特点的版本。那么根据这个Generation以及这个表名(即StoreName)我们就可以得出一个SchemaId,根据这个SchemaId我们可以得到有序的该Schema的所有字段,那么剩下的就很easy了,如果对于二进制编码不太熟悉的,请看看Protocol Buffer
好了,那么我们如果想增加一个字段呢?需要做的仅仅是修改元信息,将新的Schema信息存入上面两个元数据,如果想读取原有的老数据,那么根据generation进行相关解析即可,如果插入新的Schema的数据,使用最新的generation就可以了,一切都非常完美。这个generation字段还可以使用压缩编码的方式,在generation小于128的时候,我们只需要1个字节的额外空间消耗
优点:无需额外空间消耗,无需在线修改,透明的使用,几乎无downtime
缺点:如果增加字段,原有老数据的格式仍然是默认值,但我想这一点大部分人都可以将其忽略
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
2017年5月数据库流行度排行榜 MySQL与Oracle“势均力敌”
数据库知识网站DB-engines.com最近更新了2017年5月的数据库流行榜单。TechTarget继续与您一起分享最新的榜单情况。
-
2017年3月数据库流行度排行榜 Oracle卫冕之路困难重重
时隔一个月,数据库市场经过一轮“洗牌”,旧的市场格局是否会被打破,曾经占巨大市场份额的企业是否可能失去优势?
-
2017年2月数据库流行度排行榜 攻城容易守城难
2016年下半年,数据库排行榜的前二十名似乎都“固守阵地”,在排名上没有太大的变动。随着2017年的悄然而至,数据库的排名情况是否会有新的看点?
-
MySQL管理特性:让企业适合交易平台
当Alexander Culiniac和他的同事在TickTrade系统公司建立一个基于云的交易平台时,面临一些基本的约束。那就是,系统必须在云上工作良好并且经济实用。