
在之前的一篇文章中,介绍了mongos的balaner的执行流程,其中在源码中的Balancer::run()方法里简单说明了为了连接到configserver,balancer通过构造ScopedDbConnection实现来链接并执行相应操作,因为当时篇幅所限,只是该链接使用池化的方式一带而过,今天就专门介绍一下mongodb中使用池化方式来管理链接对象以提升链接效率的原理。
首先看一下balancer类的run()方法,相关代码如下:
//balance.cpp
void Balancer::run() {
……
while ( ! inShutdown() ) {//一直循环直到程序中断或关闭
try {
……
ScopedDbConnection conn( config );
……
conn.done();//将conn放到链接池中(为其它后续操作使用)
sleepsecs( _balancedLastTime ? 5 : 10 );
}
catch ( std::exception& e ) {
……
}
}
}
上面方法中从ScopedDbConnection声明到该实现执行done()方法结束,系统会从链接池中获取一个链接对象,如无链接则直接创建。如果是创建的链接,则会将该链接添加到池中。下面我们就看一下其类图:
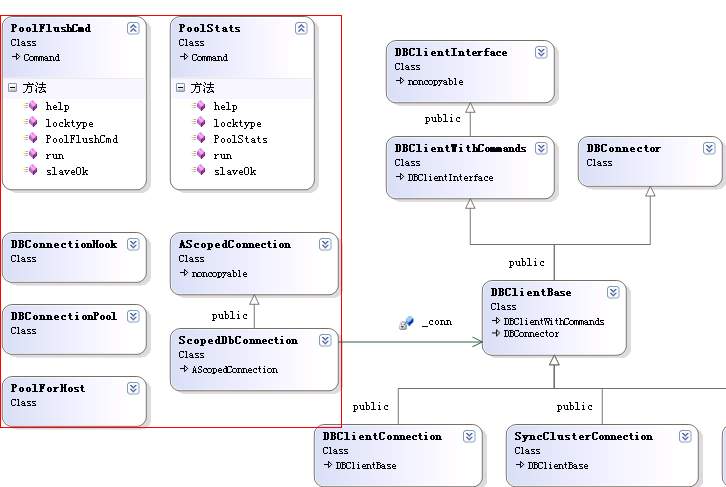
图中的红框所圈的类均为connpool.h头文件中所包含定义的类信息,而这些类中(比如ScopedDbConnection,上面代码提到过)会包含一个DBClientBase属性指针,而DBClientBase的定义位于dbclient.h头文件中,其主要是定义了客户端连接到mongodb服务端时所经常进行的操作(CRUD等)。
图中的类比较多,主要的几个包括:
| ScopedDbConnection:池中的数据库链接类,其通过持有的DBClientBase指出针来施加crud操作 DBConnectionPool:数据库链接池类,定义链接的创建,获取,flush,以及维护等操作。 PoolForHost:该对象提供以栈式(stack)方式管理pool链接对象。 |
下面就先看一下ScopedDbConnection的构造方法,其执行流程如下:
| //connpool.cpp ScopedDbConnection::ScopedDbConnection(const Shard& shard ) : _host( shard.getConnString() ) , _conn( pool.get(_host) ) { } |
其中的_host( shard.getConnString() )只是将要链接的mongo服务地址绑定到ScopedDbConnection的_host属性上。重要的是_conn( pool.get(_host))这一行代码,它会从池中(pool类型为DBConnectionPool)获取一个链接,如池中没有则会创建一个链接并返回,如下(详情见注释):
//connpool.cpp
DBClientBase* DBConnectionPool::get(const ConnectionString& url) {
// 从池中获取一个链接对象
DBClientBase * c = _get( url.toString() );
//如获取到则直接返回
if ( c ) {
onHandedOut( c );//执行取出时定义的hook方法
return c;
}
string errmsg;
c = url.connect( errmsg );
uassert( 13328 , _name + “: connect failed ” + url.toString() + ” : ” + errmsg , c );
//以url为链接地址,构造一个链接对象并返回该对象
return _finishCreate( url.toString() , c );
}
上面方法中_get( url.toString() ) 这一行代码主要是用于执行从池中获取对象的操作,它的实现代码如下:
| DBClientBase* DBConnectionPool::_get(const string& ident) { scoped_lock L(_mutex); PoolForHost& p = _pools[ident];//获取指定的链接池 return p.get(); } |
其中_pools类型定义如下,用于实现从“服务器名称”到“相应链接池”的映射,因为不同的服务器会对应不同的链接池:
| typedef map<string,PoolForHost,serverNameCompare> PoolMap; |
找到了相应的链接池之后,返回该池所对应的PoolForHost对象的引用,该对象提供以栈式(stack)方式管理pool链接对象。其get()方法定义如下:
//connpool.cpp
DBClientBase * PoolForHost::get() {
time_t now = time(0);
while ( ! _pool.empty() ) {
StoredConnection sc = _pool.top();//取出栈顶链接
_pool.pop();//移除栈顶的元素
if ( sc.ok( now ) )//如链接空闲未超过1小时
return sc.conn;
delete sc.conn; //释放链接对象
}
return NULL;//如无有效链接,则返回null
}
现在我们再将注意力放回到主流程DBClientBase* DBConnectionPool::get(const ConnectionString& url)方法的下面一行代码,即:
//connpool.cpp
//如获取到则直接返回
if ( c ) {
onHandedOut( c );//执行取出时定义的hook方法
return c;
}
该方法一个hook方法的调用,它的实现方式有些复杂,很像设置模式中的Observer (观察者)模式,我们先看一下该模式的类图:
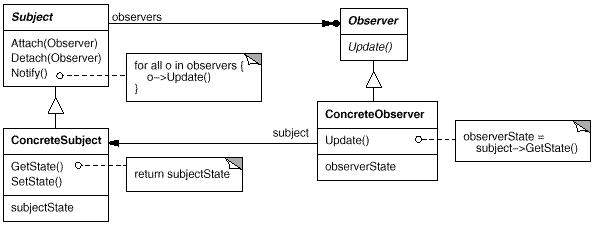
有关该模式的具体讲解可以参见相关资料或在google上搜一下,这里暂不做解释了。
这里我们先看一下该方法的具体实现(onCreate与onHandedOut方式类似,这里仅对onHandedOut进行说明):
void DBConnectionPool::onHandedOut( DBClientBase * conn ) {
if ( _hooks.size() == 0 )
return;
for ( list<DBConnectionHook*>::iterator i = _hooks.begin(); i != _hooks.end(); i++ ) {
(*i)->onHandedOut( conn );
}
}
可以看出,它进而面使用了for的方式,依次对conn进行onHandedOut()方法处理,而_hooks的定义如下:
//connpool.h 文件
//hooks列表,用于收集hook方法并(批量)执行相关方法
list<DBConnectionHook*> _hooks;
看到这里,我们有必要了解一下_hooks是如何添加相关hook对象的。还记得我在这篇文章中介绍在mongos的main()中有如下代码吗?
//server.cpp
// set some global state
//添加对链接池hook的绑定(shardingConnectionHook对象引用),以最终调用其onHandedOut方法
pool.addHook( &shardingConnectionHook );
//设置链接池名称
pool.setName( “mongos connectionpool” );
对了,就是上面的addHook()方法,添加了对shardingConnectionHook的引用,而shardingConnectionHook则是对shard链接hook的具体实现,如下:
//server.cpp
class ShardingConnectionHook : public DBConnectionHook {
public:
virtual void onHandedOut( DBClientBase * conn ) {
ClientInfo::get()->addShard( conn->getServerAddress() );
}
} shardingConnectionHook;
当然这里不是对addShard及相应command命令进行分析的时候,因为mongodb有一个架构设计非常清晰的指令(command)体系,有关该方面内容我也会专门接时间来加以说明。
还是回到程序主流程上,在onHandedOut处理完之后,就可以将获取到的链接实例返回了。但如果没有可能的链接信息,那么就要创建一个链接(cs.connect( errmsg ))并将其入库,如下:
//connpool.cpp
DBClientBase* DBConnectionPool::_finishCreate( const string& host , DBClientBase* conn ) {
{
scoped_lock L(_mutex);
//获取池中相应host的PoolForHost信息并将创建的链接数(_created属性)加1
PoolForHost& p = _pools[host];
p.createdOne( conn );
}
//调用绑定到当前pool的DBConnectionHook中的create方法(施加额外操作)
onCreate( conn );
//调用绑定到当前pool的DBConnectionHook中的onHandedOut方法(施加额外操作)
onHandedOut( conn );
return conn;
}
在完成了这一步,链接池的就会多一个connect对象,并使用该对象来链接configServer. 而当balancer执行并相应均衡chunk操作后,会执行如下代码:
| conn.done();//将conn放到链接池中(为其它后续操作使用) |
下面就是done()函数代码:
//connpool.h ScopedDbConnection类
void done() {
if ( ! _conn )//如无效则返回
return;
/* we could do this, but instead of assume one is using autoreconnect mode on the connection
if ( _conn->isFailed() )
kill();
else
*/
pool.release(_host, _conn);//如有效则进行池化(添加到链接池)
_conn = 0;
}
//connpool.h DBConnectionPool类
void release(const string& host, DBClientBase *c) {
if ( c->isFailed() ) {//如链接出现异常(比如无法链到服务器),则释放
delete c;
return;
}
scoped_lock L(_mutex);
_pools[host].done(c);//否则将其压入链接池供其它操作使用
}
//connpool.h PoolForHost类
void PoolForHost::done( DBClientBase * c ) {
_pool.push(c);
}
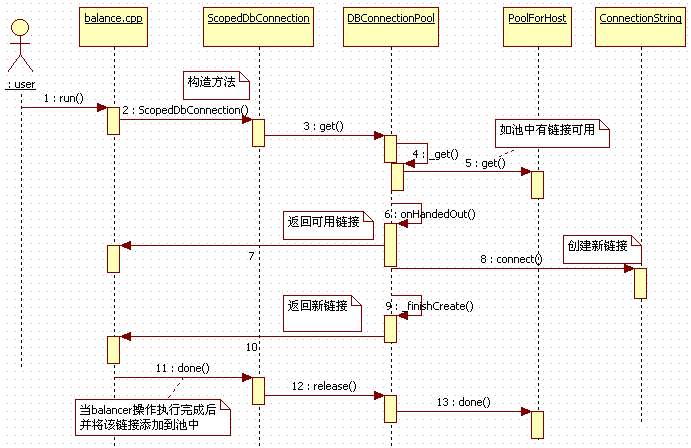
好了,今天的内容就先到这里了。按照惯例,最后用一张时序图来对今天的流程做一下回顾。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
MongoDB与Cassandra数据库对比
MongoDB和Cassandra都属于NoSQL数据库系列,它们也恰好都是开源,但是,它们的相似之处仅此而已 […]
-
OpenWorld18大会:Ellison宣布数据库的搜寻和破坏任务
在旧金山举行的甲骨文OpenWorld 2018大会中,甲骨文首席技术官(CTO)兼创始人Larry Elli […]
-
eHarmony公司利用Redis NoSQL数据库进行热存储
虽然关系型数据库不会消失,但关系型数据库管理系统有时仅在会话管理、推荐引擎和模式匹配等关键Web应用程序中担当 […]
-
ObjectRocket着力发展Azure MongoDB服务
MongoDB吸引了微软公司的注意力,微软公司计划针对运行于该公司2017年发布的Azure Cosmos D […]