
mongodb中提供了复制(Replication)机制,通过该机制可以帮助我们很容易实现读写分离方案,并支持灾难恢复(服务器断电)等意外情况下的数据安全。
在老版本(1.6)中,Mongo提供了两种方式的复制:master-slave及replica pair模式(注:mongodb最新支持的replset复制集方式可看成是pair的升级版,它解决pair只能在两个结点间同步的限制,支持多个结点同步且支持主从宕机时的自动切换, 在1.6版以后提供)。
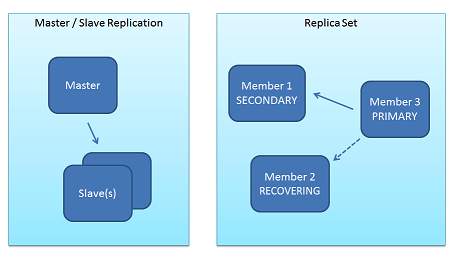
利用前者,我们可以实现读写分离(主从复制模式),后者则支持当主服务器断电情况下的集群中其它slave自动接管,并升级为主服务器。 并且如果后来的也出错了,那么master状态将会转回给第一个服务器(之前宕机但后来又恢复运行的服务器)。
同时mongodb支持使用安全认证(enable)。不管哪种replicate方式,只要在master/slave中创建一个能为各个database认识的用户名/密码即可。其认证过程如下:
| slave先在local.system.users里查找一个名为”repl”的用户,找到后用它去认证master。如果”repl”用户没有找到,则使用local.system.users中的第一个用户去认证。local数据库和admin数据库一样,local中的用户可以访问整个db server。 |
下面介绍分别介绍一下这两种复制的配置方式:
Master-Slave(主从)模式:
一个server可以同时为master和slave。一个slave可以有多个master(不推荐,可能会产生不可预期的结果)。
配置选项:
–master 以主服务器方式启动
–slave 以从服务器方式启动
–autoresync:自动重新sync,因为该操作会copy 主服务器上的所有document,比较耗时,在10分钟内最多只会进行一次。
–oplogSize:指定master上用于存放更改的数据量,如果不指定,在32位机上最少为50M,在64位机上最少为 1G,最大为磁盘空间的5%。
–source 主服务器地址(与–slave组合使用)
–only 仅限于同步指定数据库(下面示例为test库)
–slavedelay 同步延时
下面是本人在本地为了测试方便所使用的配置参数
Master: IP->10.0.1.103
| mongod –dbpath=d:mongodbdb –master –oplogSize 64 |
Slave: IP->10.0.4.210
| mongod –dbpath=d:mongodbdb –slave –source 10.0.1.103:27017 –only test –slavedelay 100 |
补充:受限的master-master复制,这种模式对插入、查询及根据_id进行的删除操作都是安全的。但对同一对象的并发更新无法进行。Mongo 不支持完全的master-master复制,通常情况下不推荐使用master-master模式,但在一些特定的情况下master-master也可用。master-master也只支持最终一致性。配置master-master只需运行mongod时同时加上–master选项和 –slave选项。如下:
| mongod –dbpath=d:mongodbdb –port 27017 –master –slave –source localhost:27018 mongod –dbpath=d:mongodbdb –port 27018 –master –slave –source localhost:27017 |
Replica pairs模式
以这种方式启动后,数据库会自动协商谁是master谁是slave。一旦一个数据库服务器断电,另一个会自动接管,并从那一刻起起为master。万一另一个将来也出错了,那么master状态将会转回给第一个服务器。以这种复制方式启动mongod的命令如下:
配置选项:
mongod –pairwith
–pairwith: remoteserver是pair里的另一个server
–arbiter: arbiterserver是一个起仲裁作用的Mongo数据库,用来协商pair中哪一个是master。arbiter运行在第三个机器上,利用“平分决胜制”决定在pair中的两台机器不能联系上对方时让哪一个做master,一般是能同arbiter通话的那台机器做master。如果不加–arbiter选项,出现网络问题时两台机器都作为master。
注:可使用db.$cmd.findOne({ismaster:1})可以检查当前哪一个database是master。
另外这种模式下的两台机器只能满足最终一致性。当replica pair中的一台机器完全挂掉时,需要用一台新的来代替。如(n1, n2)中的n2挂掉,这时用n3来代替n2。步骤如下:
1. 告诉n1用n3来代替n2:db.$cmd.findOne({replacepeer:1});
2. 重启n1让它同n3对话:mongod –pairwith n3 –arbiter
3. 启动n3:mongod –pairwith n1 –arbiter
在n3的数据没有同步到n1前n3还不能做master,这个过程长短由数据量的多少决定。
了解了复制模式之后,还有一个问题需要介绍一下,不是就是本文中mongodb使用cap collection来存储操作日志,并进而使用日志来复制(同步)结点间的数据,其中由主结点保存的操作的记录叫做oplog(operation log的简称)。
Oplog存在一个叫local的特殊数据库中,在oplog.$main集合。Oplog中的每一个文档表示一个在主结点上执行的操作。文档主要包括4块内容,如下:
Ts:操作的时间戳。时间戳类型是一个用来跟踪操作是何时执行的一种内部类型。它由4字节的时间戳和四字节的增量计数器组成。
Op:执行的操作的类型,大小为1字节。(例如,“i”代表insert,”u”:update, “d”:delete, “n”:none无操作等)
Ns:执行操作的命名空间(集合名)
O:执行操作的文档。对于插入,这是将要插入的文档。
另外这种日志只保存会“改变数据库状态”的操作。查询操作不会记录在oplog中。
好了,了解这些知识之后,我们就来开始看一下如何调试master-slave模式的源码,首先要在vs2010中打开mongod项目,并将启动参数中设置如下:
–master –oplogSize 64 (master IP为10.0.1.103)
如下图:
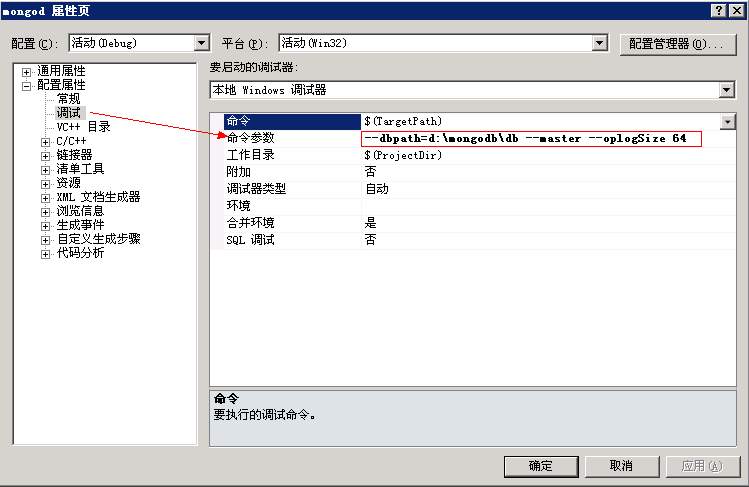
之后编译该项目,启动该主服务结点,如下:
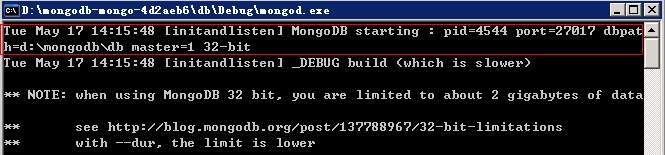
接着我们可以在本地或另外一台机器上启动一个slave结点:
| mongod –dbpath=d:mongodbdb –slave –source 10.0.1.103:27017 –only test –slavedelay 100 |
下面介绍一下master(主服务端)的代码执行流程。首先我们打开instance.cpp文件,找到下面方法:
//instance.cpp
// Returns false when request includes ‘end’
void assembleResponse( Message &m, DbResponse &dbresponse, const SockAddr &client ) {
……
if ( op == dbQuery ) {
if ( handlePossibleShardedMessage( m , &dbresponse ) )
return;
receivedQuery(c , dbresponse, m );
}
//服务端(master) 收到message执行相关查询操作
else if ( op == dbGetMore ) {
if ( ! receivedGetMore(dbresponse, m, currentOp) )
log = true;
}
…..
}
看过本系列开头那几篇BLOG的朋友,会看出上面方法其实在mongodb的crud操作中都会执行到,更多内容可以参见这篇BLOG,这里不再赘述。
当slave 从结点发送同步复制请求时,master会执行上面的dbGetMore操作,从主库中的oplog中获取相应日志并返回给slave结点,下面是receivedGetMore()方法的具体实现:
//instance.cpp
bool receivedGetMore(DbResponse& dbresponse, Message& m, CurOp& curop ) {
StringBuilder& ss = curop.debug().str;
bool ok = true;
//参见:Mongodb源码分析–消息(message)中的 查询更多(document)消息结构相关内容
//http://www.cnblogs.com/daizhj/archive/2011/04/02/2003335.html
DbMessage d(m);
//完整的集合名称,形如:”dbname.collectionname”
const char *ns = d.getns();
//返回的document数
int ntoreturn = d.pullInt();
//在REPLY消息中的Cursor标识符,其必须来自于数据库
long long cursorid = d.pullInt64();
ss << ns << ” cid:” << cursorid;
if( ntoreturn )
ss << ” ntoreturn:” << ntoreturn;
time_t start = 0;
int pass = 0;
bool exhaust = false;
QueryResult* msgdata;//查询结果
while( 1 ) {
try {
readlock lk;
Client::Context ctx(ns);
//执行GetMore查询
msgdata = processGetMore(ns, ntoreturn, cursorid, curop, pass, exhaust);
}
catch ( GetMoreWaitException& ) {
exhaust = false;
massert(13073, “shutting down”, !inShutdown() );
if( pass == 0 ) {
start = time(0);
}
else {
if( time(0) – start >= 4 ) {
// after about 4 seconds, return. this is a sanity check. pass stops at 1000 normally
// for DEV this helps and also if sleep is highly inaccurate on a platform. we want to
// return occasionally so slave can checkpoint.
pass = 10000;
}
}
pass++;
DEV
sleepmillis(20);
else
sleepmillis(2);
continue;
}
catch ( AssertionException& e ) {
exhaust = false;
ss << ” exception ” << e.toString();
msgdata = emptyMoreResult(cursorid);
ok = false;
}
break;
};
//将查询结果集绑定到message对象
Message *resp = new Message();
resp->setData(msgdata, true);
ss << ” bytes:” << resp->header()->dataLen();
ss << ” nreturned:” << msgdata->nReturned;
//将上面的消息对象指针绑定到dbresponse
dbresponse.response = resp;
dbresponse.responseTo = m.header()->id;
if( exhaust ) {
ss << ” exhaust “;
dbresponse.exhaust = ns;
}
return ok;
}
可以看出,通过对message的解析找出相应的cursorid,因为mongodb如果发现游标为tailable(类型)时,会cache该cursor而不是关闭它,这主要是考虑到当下次slave请求来时,直接从cache中获取该cursor以提升效率并用它来作为继续获取后续oplog操作信息。上面方法在执行结束处会将获取到的oplog结果封装到message中并返回。但其如何获取,就要分析下面方法了:
//query.cpp
QueryResult* processGetMore(const char *ns, int ntoreturn, long long cursorid , CurOp& curop, int pass, bool& exhaust ) {
exhaust = false;
//在map<CursorId, ClientCursor*>中查询相应游客信息
ClientCursor::Pointer p(cursorid);
//将结果返回(可能没找到)
ClientCursor *cc = p.c();
int bufSize = 512;
if ( cc ) {
bufSize += sizeof( QueryResult );
bufSize += MaxBytesToReturnToClientAtOnce;
}
//创建收集查询记录结果的buf对象
BufBuilder b( bufSize );
//跳过预留数据区间(QueryResult)
b.skip(sizeof(QueryResult));
int resultFlags = ResultFlag_AwaitCapable;
int start = 0;
int n = 0;
//判断cc是否有效(如未找到则无效)
if ( !cc ) {
log() << “getMore: cursorid not found ” << ns << ” ” << cursorid << endl;
cursorid = 0;
resultFlags = ResultFlag_CursorNotFound;
}
else {
//更新master结点local.slaves中的相应信息(包括lastop时间戳)
//注:主结点使用存储在local.slaves中的syncedTo来跟踪多少slave是已经更新的。
if ( pass == 0 )
cc->updateSlaveLocation( curop );
int queryOptions = cc->queryOptions();
if( pass == 0 ) {
StringBuilder& ss = curop.debug().str;
ss << ” getMore: ” << cc->query().toString() << ” “;
}
//获取相应cursor,以便while遍历
start = cc->pos();
Cursor *c = cc->c();
c->checkLocation();
DiskLoc last;
scoped_ptr<Projection::KeyOnly> keyFieldsOnly;
if ( cc->modifiedKeys() == false && cc->isMultiKey() == false && cc->fields )
keyFieldsOnly.reset( cc->fields->checkKey( cc->indexKeyPattern() ) );
//遍历cursor,找到并封装相应查询结果给buf对象
while ( 1 ) {
if ( !c->ok() ) {//到结尾
if ( c->tailable() ) {//处理tailable情况
//Tailable 表示在返回最后一条数据后,不要关闭当前 cursor。
//这是因为系统考虑到稍后你可以再次使用该cursor.
/* when a tailable cursor hits “EOF”, ok() goes false, and current() is null. however
advance() can still be retries as a reactivation attempt. when there is new data, it will
return true. that’s what we are doing here.
*/
if ( c->advance() )
continue;
if( n == 0 && (queryOptions & QueryOption_AwaitData) && pass < 1000 ) {
throw GetMoreWaitException();
}
break;
}
//释放cursor资源关闭它(执行delete操作)
p.release();
bool ok = ClientCursor::erase(cursorid);
assert(ok);
cursorid = 0;
cc = 0;
break;
}
// 如果是clone collection时,则不会匹配
// If match succeeds on index key, then attempt to match full document.
if ( c->matcher() && !c->matcher()->matches(c->currKey(), c->currLoc() ) ) {
}
/*
TODO
else if ( _chunkMatcher && ! _chunkMatcher->belongsToMe( c->currKey(), c->currLoc() ) ){
cout << “TEMP skipping un-owned chunk: ” << c->current() << endl;
}
*/
else {//值是否重复
if( c->getsetdup(c->currLoc()) ) {
//out() << ” but it’s a dup n”;
}
else {//如匹配
last = c->currLoc();
n++;
//装填数据到buf中
if ( keyFieldsOnly ) {
fillQueryResultFromObj(b, 0, keyFieldsOnly->hydrate( c->currKey() ) );
}
else {
BSONObj js = c->current();
// show disk loc should be part of the main query, not in an $or clause, so this should be ok
fillQueryResultFromObj(b, cc->fields.get(), js, ( cc->pq.get() && cc->pq->showDiskLoc() ? &last : 0));
}
if ( ( ntoreturn && n >= ntoreturn ) || b.len() > MaxBytesToReturnToClientAtOnce ) {
c->advance();
cc->incPos( n );
break;
}
}
}
//指向下一条记录
c->advance();
if ( ! cc->yieldSometimes() ) {
cc = 0;
break;
}
}
if ( cc ) {
cc->updateLocation();
cc->mayUpgradeStorage();
//用last中的optime 更新_slaveReadTill
cc->storeOpForSlave( last );
exhaust = cc->queryOptions() & QueryOption_Exhaust;
}
}
//将buf中的信息绑定到查询结果集
QueryResult *qr = (QueryResult *) b.buf();
qr->len = b.len();
qr->setOperation(opReply);
qr->_resultFlags() = resultFlags;
qr->cursorId = cursorid;
qr->startingFrom = start;
qr->nReturned = n;
b.decouple();
return qr;
}
上面代码有些长,但其目的很明确,就是针对指定的cursor进行遍历。这里mongodb会为每个slave保存一个cursor,并且其在遍历完成后将最后一条oplog的时间戳作为当前slave在local.slaves中的更新标识信息(syncedTo),来标识当前slave的更新情况。(注:首次同步时全部复制会执行copyDatabase,复制master db上的所有document)。该方法运行截图如下:
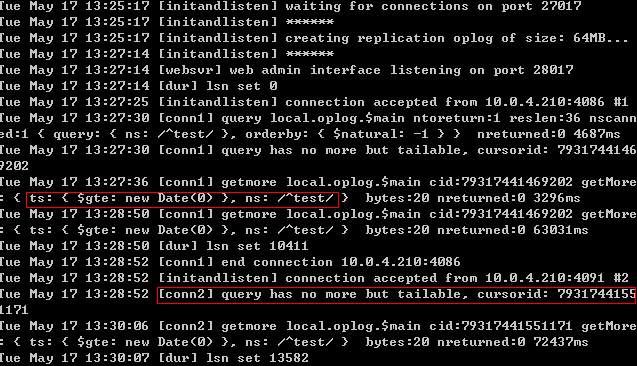
另外需要解释的是,master结点貌似并不会使用slave发来的syncedTo来过滤capped collection中的旧oplog(指小于syncedTo时间戳)的数据,而是使用tailable类型的cursor来解决如果持续获取后续新增oplog操作信息。前者的主观臆测让我在源码中兜了一个圈子,因为我一直主观认为mongod会执行类似查询操作来过滤相应旧oplog的时间戳信息,并将结果集返回给slave端。现在看来master只是不断返回后续添加到cap collection中oplog(有可能是out of sync的情况而引发slave地点执行resync操作),而最终的过滤判断操作完全交给了slave端。这一点会在我下一篇文章中有所介绍。
好了,今天的内容到这里就告一段落了。在接下来的文章中,将会介绍slave端是如何发起同步操作,以及最终如何使用获取到的oplog来构造本机数据的。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
MongoDB与Cassandra数据库对比
MongoDB和Cassandra都属于NoSQL数据库系列,它们也恰好都是开源,但是,它们的相似之处仅此而已 […]
-
OpenWorld18大会:Ellison宣布数据库的搜寻和破坏任务
在旧金山举行的甲骨文OpenWorld 2018大会中,甲骨文首席技术官(CTO)兼创始人Larry Elli […]
-
eHarmony公司利用Redis NoSQL数据库进行热存储
虽然关系型数据库不会消失,但关系型数据库管理系统有时仅在会话管理、推荐引擎和模式匹配等关键Web应用程序中担当 […]
-
ObjectRocket着力发展Azure MongoDB服务
MongoDB吸引了微软公司的注意力,微软公司计划针对运行于该公司2017年发布的Azure Cosmos D […]