
本文将讨论的是SQL中简单嵌套查询与非嵌套查询的异同,通过这些来更加深刻理解SQL语句。
某天的工作是修复某个项目的bug,接着就发现,其sql极其混乱,有非常多的left join和in操作,还有嵌套查询(只有一个表的嵌套查询)。不知道看到过哪里的资料说,嵌套查询速度慢,于是我把全部嵌套查询都改成join的形式,嵌套查询里面的where条件,我都写到join…on后面去了。突然一个想法冒出来:筛选条件跟在join…on后面 和 跟在整个sql语句最后面的where后面有什么区别呢?还有嵌套查询真的慢么?于是便有下面的测试产生,数据库环境为MS SQL 2005。
先看看非嵌套查询:
| a.select * from t1 inner join t2 on t1.id = t2.id inner join t3 on t1.id = t3.id where t1.a=1 and t2.b=1 and t3.c=1 b.select * from t1 inner join t2 on t1.id = t2.id and t2.b=1 inner join t3 on t1.id = t3.id where t1.a=1 and t3.c=1 c.select * from t1 inner join t2 on t1.id = t2.id and t2.b=1 inner join t3 on t1.id = t3.id and t3.c=1 where t1.a=1 |
在上面三个非嵌套查询,让“and t2.b=1”和“and t3.c=1”分别在join…on和where之间游走,用Management Studio选中“包含实际的执行计划”并执行这三条语句,都得出下面这个执行计划。
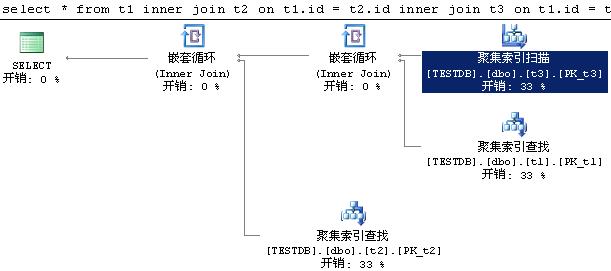
三个“聚集索引扫描”的谓词从上到下分别是:
1.t3.c=1
2.t1.a=1 (seek谓词:t1.id=t3.id)
3.t2.b=1 (seek谓词:t2.id=t3.id)
故可以认为:在MS SQL2005中,条件跟在join…on后面 和 跟在where后面是等价的。
接着看嵌套查询:
| d.select * from t1 inner join (select * from t2 where t2.b=1)a on t1.id=a.id inner join t3 on t1.id = t3.id where t1.a=1 and t3.c=1 e.select * from t1 inner join (select * from t2 where t2.b=1)a on t1.id=a.id inner join (select * from t3 where t3.c=1)b on t1.id=b.id where t1.a=1 f.elect * from t1 inner join (select t3.id,t2.b,t3.c from t3 inner join t2 on t2.id = t3.id where t2.b=1 and t3.c=1)a on t1.id=a.id where t1.a=1 |
第一句sql语句把t2的查询变成子查询,第二句sql语句把t2,t3分别变成子查询,第三句把t2和t3的查询合成一个子查询,再看看实际的执行计划:
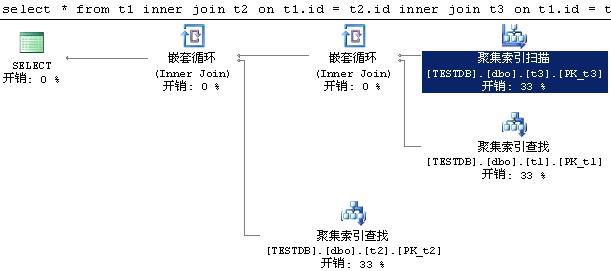
跟上面非嵌套查询的执行计划一模一样。
故可以认为:简单(注意是简单的,复杂的情况得另外考虑)嵌套查询和其相对应的非嵌套查询形式,执行效率是一样的(网上一些文章指出这是MS SQL优化器针对这些嵌套查询进行了优化)。
接着,在上面两个执行计划的图中又发现一个小问题,为什么明明是select t1 inner join t2 inner join t3,执行计划却把t1和t3先inner join(t1.id = t3.id)再跟t2 inner join(t2.id = t3.id)起来?
经过三个表,四个表,五个表进行连接测试,发现这些顺序都是不确定的。很可能这些顺序是根据SQL优化器内的算法所决定的,由于没有源代码,所以无从考究。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Azure数据湖分析从U-SQL中获得提升
大数据的发展已经让许多精通SQL的数据专业人员不知所措。微软的U-SQL编程语言试图让这些人回归数据查询游戏。
-
TT百科:SQL(结构化查询语言)
一般来说,SQL-on-Hadoop仍是一项新兴技术,但随着各个公司寻求获得拥有大数据应用程序编程SQL技能的开发和分析人员,它们正逐渐成为Hadoop部署的固定组件。
-
SQL和NoSQL数据库设计之争
企业收集了很多大规模增长的松散结构化数据,Hadoop,Spark以及其他新技术处理这些数据非常有助于改善商业智能分析效率。
-
如何通过格式良好的SQL提高效率和准确性
格式良好的SQL并不会比乱七八糟的SQL运行效果更好。数据库其实不怎么关心SQL语句中你把逗号放到了字段名的前面还是后面。