
SQL Server集成服务(SQL Server Integration Services,SSIS)在其前辈DTS(Data Transformation Services,数据转换服务)的基础上进步了不少,从可用性、性能和并行等方面来说,它已经成长为一个企业级ETL(Extraction, Transformation and Loading,抽取、转换和加载)产品,除了是一个ETL产品外,它也提供了各种内置任务来管理SQL Server实例。虽然SSIS的内部架构已经被设计为提供极好的性能和并行处理能力,但如果遵循最佳实践,其性能还可进一步优化,在本系列文章中,我将讨论SSIS的最佳实践,我会将我过去几年学习和使用SSIS的经验与大家分享。
正如上面所说的,SSIS是DTS(SQL Server 7/2000)的替代产品,如果你曾经使用过DTS,你会发现SSIS包和DTS包非常类似,但本质上已经发生了很大的变化,SSIS不是DTS的增强版本,而是从零开始构建的一个新产品,与DTS相比,SSIS提供了更好的性能和并行处理能力,并克服了DTS的许多限制。
SSIS 2008进一步增强了内部数据流管道引擎,提供了更好的性能,你可能已经看到了SSIS 2008创造的一个ETL世界记录,那就是在半小时内加载1TB数据。
SSIS的最大好处是它是SQL Server的一个组件,它可以随SQL Server安装而免费获得,不再需要为它购买额外的许可,BI开发人员、数据库开发人员和DBA都可以使用它转换数据。
最佳实践1:抽取大批量数据
最近我们从一个有3亿条记录的大表中抽取数据,起初,当SSIS包启动时一切正常,数据如预期的那样在转换,但性能开始逐渐下降,数据转换速率直线下降。通过分析,我们发现目标表有一个主聚集键和两个非聚集键,因为大量数据插入这个表,导致其索引碎片水平达到了85%-90%。我们使用索引在线重建特性重建/重组索引,但在加载期间,每过15-20分钟,索引碎片水平又回到90%,最终数据转换和并行执行的在线索引重建过程花了12-13个小时,远远超出了我们的预期。
我们想出了一个办法,当转换开始前,我们将目标表的索引全部删掉,转换结束后又再重新创建索引,通过这样处理后,整个转换过程花了3-4小时,完全符合我们的预期。
整个过程我画在下面的图中了。因此我建议如果可能,在插入数据前,删掉目标表上的所有索引,特别是插入大数据量时。
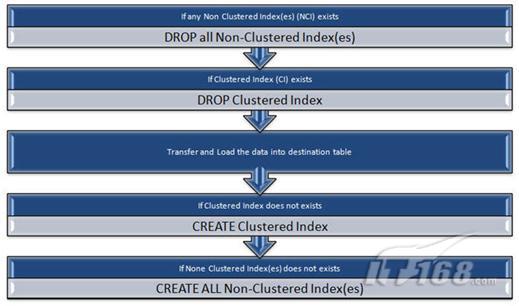
转换数据前,删除目标表上的所有索引,转换完后,再重建索引
最佳实践2:避免使用select *
SSIS的数据流任务(Data Flow Task,DFT)使用一个缓冲区作为数据传输和转换的中转站,当数据从源表传输到目标表时,数据首先进入缓冲区,数据转换是在缓冲区中完成的,转换完毕后才会写入到目标表中。
缓冲区的大小受服务器硬件本身限制,它要估算行的大小,行大小是通过一行中所有列大小的最大值求和得出的,因此列数越多,意味着进入缓冲区的行就会越少,对缓冲区的需求就会越多,性能就会下降。因此转换时最好明确指定需要转换到目标表的列。即使你需要源表中的所有列,你也应该在select语句中明确指定列的名称,如果你使用select *,它会绕到源表收集列的元数据,SQL语句执行时间自然就会长一些。
如果你将目标表不需要的列也做了转换,SSIS将会弹出警告提示信息,如:
[SSIS.Pipeline] Warning: The output column “SalariedFlag” (64) on output “OLE DB Source Output” (11) and component “OLE DB Source” (1) is not subsequently used in the Data Flow task.
Removing this unused output column can increase Data Flow task performance.
[SSIS.Pipeline] Warning: The output column “CurrentFlag” (73) on output “OLE DB Source Output” (11) and component “OLE DB Source” (1) is not subsequently used in the Data Flow task.
Removing this unused output column can increase Data Flow task performance.
当你在OLEDB源中使用“表或视图”或“来自变量的表名或视图名”数据访问模式时要小心,它的行为和select *一样,都会将所有列进行转换,当你确实需要将源表中的所有列全部转换到目标表中时,你可以使用这种方法。
最佳实践3:OLEDB目标设置的影响
下面是一组会影响数据转换性能的OLEDB目标设置:
数据访问模式:这个设置提供“快速载入”选项,它使用BULK INSERT语句将数据写入目标表中,而不是简单地使用INSERT语句(每次插入一行),因此,除非你有特殊需求,否则不要更改这个快速载入默认选项。
保持一致性:默认设置是不会检查的,这意味着目标表(如果它有一个标识列)将会创建自己的标识值,如果你检查这个设置,数据流引擎将会确保源标识值受到保护,会向目标表插入相同的值。
保持空值:默认设置也是不会检查的,这意味着来自源表中的空值将会插入到目标表中。
表锁:默认设置是要检查的,建议保持默认设置,除非是同一时刻还有其它进程使用同一个表,指定一个表锁将会取得整个表的访问权,而不是表中多行的访问权,这很可能会引发连锁反应。
检查约束:默认设置是要检查的,如果你能确保写入的数据不会违反目标表上的约束,建议不要检查,这个设置会指定数据流管道引擎验证写入到目标表的数据,如果不检查约束,性能会有很大提升,因为省去了检查的开销。
最佳实践4:每批插入的行数以及最大插入大小设置的影响
每批插入的行数:这个设置的默认值是-1,意味着每个输入行都被看做是一个批次,你可以改变这个默认行为,将所有行分成多个批次插入,值只允许正整数,它指定每一批次包含的最大行数。
最大插入提交大小:这个设置的默认值是“2147483647”,它指定一次提交的最大行数,你可以修改这个值,注意,如果这个值设得太小,会导致提交次数增加,但这样会释放事务日志和tempdb的压力,因为大批量插入数据时,对事务日志和tempdb的压力是非常大的。
上面两个设置对于理解改善tempdb和事务日志的性能是非常重要的,例如,如果你保持最大插入提交大小的默认值,在抽取期间事务日志和tempdb会不断变大,如果你传输大批量数据,内存很快就会消耗光,抽取就会失败,因此最好基于你自身的环境为其设置一个合理的值。
注意:上面的建议得益于我多年的DTS和SSIS使用经验,但如前所示,还有其它因素影响性能,如基础设施和网络环境,因此,当你将这些措施推向生产环境之前,最好做一次彻底的测试。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
Notre Dame对云端SQL Server性能基准的探索实践
确立SQL Server的性能基准,对于云端迁移来说是至关重要的第一步,一位来自于University of Notre Dame 的DBA表示,他正在试图通过数据库监控软件,找出SQL server的性能基准。
-
DBA必须掌握的数据库恢复管理技术
如果没有备份副本,数据库管理员就无法还原数据库,所以DBA在恢复之前倾向于考虑备份是合乎逻辑的。 但是,对我来说,这种逻辑一直是错误的。
-
SQL Server 2016 即将发布 你准备好了吗?
SQL Server 2016即将推出一系列全新的内置特性,并对数据库管理员所依赖的某些非常重要但十分单调的功能进行了改进。
-
DBA也要和领导抢饭碗?
数据库架构师Ziaul Mannan 认为,DBA有成为高管的潜在可能,而这种潜力在过去往往被忽视,他还将证明DBA技能到领导力的转变是可行的。