
本系列文章文将介绍PostgreSQL的事务处理功能的基本概念,并讲解如何通过PostgreSQL客户端以及从PHP脚本内部来执行各种事务。通过本文,您将学习什么是事务,PostgreSQL是如何实现它们的,以及怎样在自己的PHP应用程序中如何使用事务。
一、什么是事务?
事务可以看作是一个数据库操作的有序集,这些操作应作为整体来对待,即集内所有的操作都成功的时候,该事务才被认为是成功的,否则的话,即使其中只有一个操作失败,该事务也会被认为是不成功。如果所有的操作全部成功,那么事务就会被提交,这时它的所作的修改才能被所有其他数据库进程所用。如果操作失败,该事务就会被回滚,同时事务内部所有已完成操作所做的修改会被全部撤销。在事务提交之前,一次事务期间所作的修改,只对拥有此事务的进程可用。之所以这样做,是为了防止其他线程使用了事务修改的数据后,事务随后又发生了回滚,从而导致数据完整性错误。
事务功能是企业数据库的关键所在,因为许多业务流程是由多步组成的,下面我们以在线购物为例进行说明。在结帐时,顾客的购物车会跟现有库存进行比对,以确保有现货。接下来,顾客必须提供收费与交货信息,这时就需要检查相应的信用卡是否可用,并从中扣款。然后,需要从产品库存清单中扣除相应的数量,如果库存不足,还应向采购部门发出通知。在这些步骤中,只要有一步发生错误,那么所有修改都不应该生效。假设没有现货的情况下,还是从顾客的信用卡中扣了款的话,那么顾客会很生气,问题就会很严重了。同样地,作为在线商家,当信用卡无效的时候,您也肯定不希望从存货清单中扣除此次顾客选择的商品数量,或者因此而发出相应的采购通知。
我们这里所说的事务,必须满足四大要件:
l 原子性:事务所有的步骤必须全部成功;否则,任何步骤都不会被提交。
l 一致性:事务所有的步骤必须全部成功;否则,所有的数据都会恢复到事务开始之前的状态。
l 隔离性:在事务完成之前,所有已执行的步骤必须与系统保持隔离。
l 持久性:所有提交的数据,系统必须加以恰当保存,并保证万一系统发生故障时仍能将数据恢复到有效状态。
PostgreSQL的事务支持功能完全遵循上述四项基本原则(有时候人们简称为ACID),从而能够有效保证数据库的完整性。
二、PostgreSQL的事务隔离
PostgreSQL的事务支持是通过通常所说的多版本并发控制或者MVCC方法实现的,也就是说,每当事务进行处理时,它看到的是自己的数据库快照,而非底层数据的实际状态。 这使得任何给定的事务无法看到其它已经启动但是尚未提交的事务对数据所作的部分修改。这项原则就是所谓的事务隔离。
SQL标准规定了三种属性以用来确定一个事务处于四级隔离级别的哪一级,这些属性如下所示:
l 脏读:一个事务读取了另一个未提交的并行事务写的数据
l 不可重复读:当一个事务重新读取前面读取过的数据时,发现该数据已经被另一个已提交的事务修改过
l 幻读:一个事务重新执行一个查询时,返回一套符合查询条件的行,发现这些行因为其他最近提交的事务而发生了改变
这三种情况确定了一个事务的隔离级别,所有四种水平如表1所示。
表1 SQL标准事务隔离级别
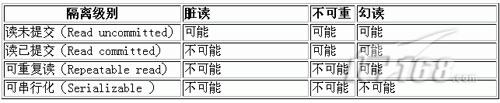
PostgreSQL允许您请求四种可能的事务隔离级别中的任意一种。但是在内部,实际上只有两种可用的隔离级别,分别对应读已提交和可串行化。如果你选择了读未提交的级别,实际上你用的是读已提交,在你选择可重复的读级别的时候,实际上你用的是可串行化,所以实际的隔离级别可能比你选择的更严格。虽然这看起来是有悖于我们的直觉,但是SQL标准的确允许这样做,因为四种隔离级别只定义了哪种现象不能发生,但是没有定义那种现象一定发生,所以除了不允许的事务特性之外,所有的特性都是允许的。举例来说,如果您请求可重复读模式,那么该标准只是要求您不准脏读以及不可重读,但是却没有要求允许幻读。因此,可串行化事务模式满足可重复读模式的要求,即使它跟定义没有完全吻合。因此,您应当确切的知道,当您请求读未提交模式的时候,您实际得到的却是读已提交模式;而当您请求可重复读的时候,实际得到的是可串行化模式。您还应当意识到,默认情况下,如果您没有请求一个特定的隔离级别,那么您得到的将是读已提交隔离级别。
下面我们了解一下读已提交和可串行化之间的主要区别。在读已提交模式下SELECT 查询只能看到该查询开始之前提交的数据而永远无法看到未提交的数据或者是在查询执行时其他并行的事务提交的改变;不过 SELECT 的确看得见同一次事务中前面更新的结果,即使它们还没提交也看得到。实际上,一个 SELECT 查询看到一个在该查询开始运行的瞬间该数据库的一个快照。请注意两个相邻的 SELECT 命令可能看到不同的数据,哪怕它们是在同一个事务里,因为其它事务会在第一个SELECT执行的时候提交。当一个事务处于可串行化级别的时候,一个 SELECT 查询只能看到在该事务开始之前提交的数据而永远看不到未提交的数据或事务执行中其他并行事务提交的修改;不过,SELECT 的确看得到同一次事务中前面的更新的效果,即使事务还没有提交也一样。这个行为和读已提交级别是不太一样,它的 SELECT 看到的是该事务开始时的快照,而不是该事务内部当前查询开始时的快照。这样,一个事务内部后面的SELECT命令总是看到同样的数据。这意味着,读已提交模式下一个事务内部后面的SELECT命令可以看到不同的数据,但是在可串行化模式下却总是看到同样的数据。
对于以上区别,请读者一定弄清楚。虽然刚看上去有些复杂,但是只要抓住两个要点,理解起来还是很容易的:首先,PostgreSQL运行事务的并发运行,也就是说一个事务执行的时候,并不妨碍另一事务对相同数据操作。其次,一定注意快照的概念,事务提交前操作的是数据快照而非数据库本身,同时注意不同隔离级别使用的是何时的快照——事务开始之前的快照,还是事务内部操作开始之前的快照?我想只要抓住了以上要点,我们就能很好的把握各种隔离级别之间的区别了。
上面介绍了事务的基本概念,接下来我们开始演示如何在PostgreSQL客户端中使用事务。
三、创建示例表
下面,我们通过一个具体的在线交易应用为例来阐述上面介绍的事务概念。为此,我们需要先给这个示例程序在名为company的数据库中创建两个表:participant和trunk。同时,我们还会介绍各个表的用途和结构。建好表后,我们还需为它们填入一些样本数据,具体如下所示。
我们首先创建Participant表,这个表用来存放参与物品交换者的信息,包括他们的姓名、电子邮件地址和可用现金:
| 1 CREATE TABLE participant ( 2 participantid SERIAL, 3 name TEXT NOT NULL, 4 email TEXT NOT NULL, 5 cash NUMERIC(5,2) NOT NULL, 6 PRIMARY KEY (participantid) 7 ); 8 CREATE TABLE participant ( 9 participantid SERIAL, 10 name TEXT NOT NULL, 11 email TEXT NOT NULL, 12 cash NUMERIC(5,2) NOT NULL, 13 PRIMARY KEY (participantid) 14 ); |
然后,我们开始创建trunk 表。这个表存储参与者所有的物品的有关信息,包括属主、名称、描述和价格:
| 1 CREATE TABLE trunk ( 2 trunkid SERIAL, 3 participantid INTEGER NOT NULL REFERENCES participant(participantid), 4 name TEXT NOT NULL, 5 price NUMERIC(5,2) NOT NULL, 6 description TEXT NOT NULL, 7 PRIMARY KEY (trunkid) 8 ); |
用到的表都建好了,下面我们开始添加样本数据。为简单起见,我们这里只添加了两名参与者,即Tom和Jack;并为trunks表添加了少量的物品,如下所示:
| 1 INSERT INTO participant (name,email,cash) VALUES 2 (‘Tom’,’Tom@example.com’,’1100.00′); 3 INSERT INTO participant (name,email,cash) VALUES 4 (‘Jack’,’Jack@example.com’,’1150.00′); 5 INSERT INTO trunk (participantid,name,price,description) VALUES 6 (1,’Linux CD’,’1.00′,’Complete OS on a CD’); INSERT INTO trunk (participantid, 7 name,price,description) VALUES 8 (2,’ComputerABC’,’12.99′,’a book about computer!’); 9 INSERT INTO trunk (participantid,name,price,description) VALUES 10 (2,’Magazines’,’6.00′,’Stack of Computer Magazines’); |
四、简单的示例应用
为了让读者切身体会事务的运行机制,我们从命令行来运行我们的示例程序。我们的示例程序将演示两个交易者如何通过现金的形式来互换物品。在考察代码之前,先让我们看一下更容易理解的伪代码:
1. 参加者Tom请求一个物品,例如位于参加者Jack的虚拟储物箱中的ComputerABC。
2. 参加者Tom向参加者Jack的帐户上划过去$12.99的现金。结果是,Tom的帐户中现金数量减去12.99,而Jack的帐户的现金数量则增加12.99。
3. 将ComputerABC的属主改为参加者Tom。
如您所见,这个过程中的每一步对于该交易的整体成功来说都是非常关键的,所以必须保证我们的数据不会由于单步失败而遭到破坏。当然,现实中的情景要比这里复杂得多,例如必须检查购买方是否具有足够的现金等等,不过为了简单起见,我们忽略了一些细节,以便读者将主要精力都放到事务这一主题上来。
我们可以提交START TRANSACTION命令来启动事务处理:
1 company=# START TRANSACTION;
2 START TRANSACTION
注意,START TRANSACTION还有一个别名,即BEGIN命令,虽然两者都能完成该任务,但是我们还是推荐您使用后者,因为它符合SQL规范。接下来,从Tom的帐户中扣除$12.99:
1 company=# UPDATE participant SET cash=cash-12.99 WHERE participantid=1;
2 UPDATE 1
然后,为Jack的帐户增加$12.99:
1 company=# UPDATE participant SET cash=cash+12.99 WHERE participantid=2;
2 UPDATE 1
然后,将ComputerABC过户给Tom:
1 company=# UPDATE trunk SET participantid =1 WHERE name=’ComputerABC’ AND
2 company-# participantid=2;
3 UPDATE 1
现在,我们已经完成了一笔交易,接下来我们开始介绍PostgreSQL的另一个特性:savepoint。注意,Savepoint功能是从PostgreSQL 8.0.0才引入的,因此如果您使用的是该版本之前的PostgreSQL的话,那么就无法使用下面介绍的命令。Savepoint就像是事务的书签,我们可以在一个事务里设置一个点,以便万一事务出错时回滚到该保存点。我们可以像下面这样提交一个保存点:
1 company=# SAVEPOINT savepoint1;
2 SAVEPOINT
提交了保存点后,我们就可以继续执行各种语句了。为了演示保存点的功能,假如我们想要检验对participant表所做的修改,但是在查询命令中拼错了participant表的名称:
1 company=# SELECT * FROM particapant;
2 ERROR: relation “particapant” does not exist
注意,对于8.0.0版本之前的PostgreSQL来说,则必须回滚整个事务。如果我们没有设置保存点就执行了这个查询,那么我们就会因为事务中的单个错误而不得不回滚整个事务。即使我们改正了这个错误,PostgreSQL也不会让我们继续该事务:
1 company=# SELECT * FROM participant;
2 ERROR: current transaction is aborted, commands ignored until end of transaction block
然而,因为我们已经提交了一个保存点,所以我们可以回滚到这个保存点,也就是说使我们的事务回到出错之前的状态:
1 company=# ROLLBACK TO savepoint1;
2 ROLLBACK
注意,拼写错误是一个非常烦人的问题,不过对于PostgreSQL 8.1来说,客户端psql带有一个reseterror选项,能够自动地设置保存点,并在出错时进行回滚。
我们现在可以在我们的事务之内进行查询了,好象根本发生错误一样。下面我们花一些时间来检查participant表,以保证向借方和贷方记入正确的现金数量。
1 company=# SELECT * FROM participant;
将返回:
| 1 participantid | name | email | cash 2 —————+——–+——————–+——– 3 1 | Tom | Tom@example.com | 1087.01 4 2 | Jack | Jack@example.com | 1162.99 5 (2 rows) |
此外,我们还需要检查一下trunk表,看看ComputerABC的属主已经是否进行了相应的修改。然而需要注意的是,由于PostgreSQL强制执行ACID原则,因此这个改变只对执行该事务的当前连接可用。为了说明这一点,我们启动另一个psql客户端,并再次登陆数据库company,查看participant表时,我们会发现交易双方相应的现金值并没有变。这是因为ACID中的隔离性所导致的。除非我们提交了所作的修改,否则其他连接是看不到事务处理过程中所作的任何改变的。
如果想撤销事务该怎么操作呢?回到第一个客户端窗口,并通过ROLLBACK命令取消这些改变:
1 company=# ROLLBACK;
2 ROLLBACK
现在,再一次执行SELECT命令:
| 1 company=# SELECT * FROM participant; 2 This returns: 3 CHAPTER 4 5 participantid | name | email | cash 6 —————+——–+——————–+——– 7 1 | Tom | Tom@example.com | 1100.00 8 2 | Jack | Jack@example.com | 1150.00 9 (2 rows) |
需要注意的是,交易双方的现金量已经恢复为原始值。检查trunk表还会看到ComputerABC的属主也没有任何变化。再次重复前面的过程,这一次通过使用COMMIT命令而不是通过回滚操作来提交改变。一旦提交事务,再次返回到第二个客户端并查看这两个数据表,您会发现提交的变化已经可用了。
需要说明的是,COMMIT或者ROLLBACK命令提交之前,事务处理之间对数据所作的任何修改都不会生效。这意味着,如果PostgreSQL服务器在提交这些修改之前崩溃的话,那么这些修改也不会发生;要想使这些修改发生的话,您必须重新启动该事务。
五、小结
本文中,我们介绍了PostgreSQL的事务功能,并讲解如何通过PostgreSQL客户端使用事务。读者通过阅读本文,将会学习什么是事务,PostgreSQL是如何实现它们的。在后面一篇文章中,我们将介绍如何在自己的PHP应用程序中如何使用事务。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
甲骨文自治数据库云现可处理事务
甲骨文现在提供事务处理功能,作为其自治数据库云软件平台的一部分–该平台旨在为云端甲骨文用户自动化数 […]
-
2017年1月数据库流行度排行榜 新年新气象
新年新气象,数据库知识网站DB-engines最近更新了2017年1月份数据库流行度榜单。TechTarget数据库网站将与您分享1月份的榜单排名情况,让我们拭目以待。
-
2016年12月数据库流行度排行榜 几家欢乐几家愁
在过去的6个月中,数据库排行榜的前二十名总体上没有太大的变动,那么数据库知识网站DB-engines最近更新的2016年12月份数据库流行度排名情况是否一如既往的沉寂、低调呢?
-
2016年10月数据库流行度排行榜 两组数据库棋逢对手
数据库知识网站DB-engines更新了2016年10月份的数据库流行度排行榜,10月份的榜单又有哪些变化,哪些惊喜呢?