
其实列存储并不是什么新概念,早在1985年SIGMOD会议上就有文章” A decomposition storage model”对DSM(decomposition storage model)做了比较详细的介绍,而Sybase更在2004年左右就推出了列存储的Sybase IQ数据库系统(见200年VLDB文章” Sybase iq multiplex – designed for analytics”),主要用于在线分析、数据挖掘等查询密集型应用。
列存储,缩写为DSM,相对于NSM(N-ary storage model),其主要区别在于,DSM将所有记录中相同字段的数据聚合存储,而NSM将每条记录的所有字段的数据聚合存储,如下图所示:
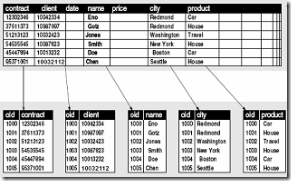
列存储有什么优点?
就我目前比较肤浅的理解,列存储的主要优点有两个:
1) 每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量,据C-Store, MonetDB的作者调查和分析,查询密集型应用的特点之一就是查询一般只关心少数几个字段,而相对应的,NSM中每次必须读取整条记录;
2) 既然是一个字段的数据聚集存储,那就更容易为这种聚集存储设计更好的压缩/解压算法。
列存储适合用在什么场合?
OLAP,数据仓库,数据挖掘等查询密集型应用。当然,列存储数据库并不是说完全不能进行更新操作,其实它们的更新操作性能并不是很差,一般也够用,但是一方面不如自己的查询性能,另外一方面也不如Oracle这种专门搞OLTP的数据库,所以一般就不提这个。
列存储不适合用在什么场合?
相对来说,不适合用在OLTP,或者更新操作,尤其是插入、删除操作频繁的场合。
为啥上世纪80年代就出现的概念现在又重新炒起来了呢?
2005年VLDB有篇文章(“One Size Fits All – An Idea Whose Time Has Come and Gone”),就是那个老牛M. Stonebraker写的,明确指出,时代变了,指望一个数据库产品就统一天下的日子已经一去不复还了。于是,这个老牛在2005年左右做了C-Store,一个列存储的数据库原型系统,在VLDB, SIGMOD等顶级国际会议上灌了几桶水后,拉了一伙人出去开了个公司叫Vertica,将其商业化,专注于数据仓库、在线分析等市场,最近貌似还挺红火的;顺便说一下,为了贯彻上面的思想,这个老牛在同一时期又做了H-Store,一个主内存数据库原型系统,没怎么灌水就又招呼了一帮人开了个公司叫VoltDB,将其商业化,专注于联机事务处理,但是近况貌似不怎么样,可能是跟Oracle老大大直接冲突了吧。
联想到M. Stonebraker在上世纪70年代带头开展关系数据库管理系统的实现工作,做出来了Ingres,其中灌水无数,从这个原型系统基础上产生了很多商业数据库软件,包括 Sybase、Microsoft SQL Server、NonStop SQL、Informix 等,而所谓的最先进的开源数据库系统PostgreSQL也是Ingres的一个后继分支。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
SAP如何帮助客户管理大数据?
SAP的大数据策略是以HANA为中心的,然而真正涉及到大数据任务的部分,SAP是交给Sybase IQ(SAP IQ)和Hadoop(通过Hive)来处理的。
-
微软展示最新SQL Server内存数据库功能
在西雅图举行的SQL Server专家协会峰会(PASS)上,微软公司演示了最新项目“Hekaton”,该项目是一个针对交易型应用系统的SQL Server内存数据库功能。
-
浅析列式数据库的特点
列式数据库从一开始就是面向大数据环境下数据仓库的数据分析而产生,它跟行式数据库相比当然也有一些前提条件和优缺点。
-
大数据时代的赛贝斯(Sybase)分析云平台
大数据面临的问题之一就是如何对数据进行快速地采集。数据的采集是非常困难的事情,数据增长速度比我们现在数据库的处理能力要大得多。