
想象这样一个场景:在DataBase_name.dbo.Table_name中有一个名为Title(标题)和Contents(内容)的字段,现在需要查询在Title或者Contents中包括“qq”字符的所有记录。
面对这样的一个场景,我们通常都会写这样一个脚本:SELECT * FROM DataBase_name.dbo.Table_name WHERE Title LIKE ‘%qq%’ OR Contents LIKE ‘%qq%’; 没错,这也是我第一个想到的方法。但是我们需要思考的是:随着时间的推移,数据会越来越大,那个时候我们该如何提高我们的性能?用户随时都有可能再添加对Remark(备注)字段进行查找,难道我们就应该不厌其烦地修改程序代码?
需要指出的是:面对这样的查询条件,即使Title和Contents上都有索引,我们也无法使用到索引,因为在 ‘%qq%’的“qq”前面使用了通配符,所以无法使用到索引;如果查询的条件是’qq%’,那到是可以利用上索引。在许多数据库性能调优的文章上都说OR这个谓词可以使用SELECT UNION ALL SELECT这样的方式来提高性能,但是需要提醒大家的是:如果在一条记录中字段Title和Contents都同时存在“中国”字符的话,那么返回的结果就会出现两条相同的记录,如果你希望是唯一的记录,那么这个时候你就要注意了。
现在回到我们上面的问题,大概这个时候大家都应该想到了数据库的全文索引了。全文索引是一种特殊类型的基于标记的功能性索引,由 Microsoft SQL Server 全文引擎 (MSFTESQL) 服务创建和维护。创建全文索引的过程与创建其他类型的索引的过程差别很大。MSFTESQL 不是基于某一特定行中存储的值来构造 B 树结构,而是基于要索引的文本中的各个标记来创建倒排、堆积且压缩的索引结构。(摘自MSDN)
讲了那么久,硬伤在哪里呢?可能大家都怀疑我是不是标题党了,呵呵,马上就讲到,那就是这个全文索引能解决我们一开始提到的场景吗?回答是否定。为什么呢?因为它的分词和倒排索引造成了对字符串“tqq.tencent.com”这样的内容进行‘“*qq*”’这样的条件查询,上面那条记录是不会被返回的。它的分词应该是正向最大值的分词方法,它没有对方向再进行一次分词和索引,索引无法查询到。这个可能会被大家所忽略掉的。
主题的内容讲完了,下面附带讲一些创建全文索引的步骤和注意事项,懂的同学可以跳过。
设置全文索引的步骤
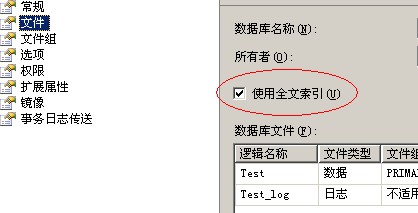
1:对着数据库点击右键-选择属性-选择文件,选中“使用全文索引”
2:对着表点击右键-全文索引-定义全文索引
3:点击下一步,如果这个表中没有唯一性索引就会出现下图所示

4:选择表列,选择断字符语言。
5:点击下一步,这里的选项要注意,如果不想再表、视图更改的时候更新全文索引,那就选择不跟踪更改;这样就可以选择是否在创建索引时启动完全填充了。
6:点击下一步创建索引要保存的目录,全文索引的索引文件是以文件的形式保存到硬盘上的。
7:之后就可以设置自动填充、手动跟踪更改,还有设置计划了。
全文索引需要注意:
表中必须有一个唯一性索引,当并不需要是主键。
一个表中只能有一个全文索引。
你需要告诉你的脚本你想使用全文索引,如何告诉呢?那就是使用关键字:CONTAINS、FULLTEXT、CONTAINSTABLE、FREETEXTTABLE。例如:SELECT * FROM table_name WHERE CONTAINS(fullText_column,'”search contents*”‘);需要记住CONTAINS等在不同场景、需求下的用法。
如果定义了变量作为传入值,那么就要注意是否需要在set字符的时候的前面加入N标识。
要对表设置全文索引,那就得先对数据库设置了全文索引,这样点击表右键的时候,“全文索引”选项才能用。
脚本在查找的时候是不区分大小写的。解决办法:SELECT * FROM Table_name WHERE Column_name=’A’ COLLATE Chinese_PRC_CS_AI;或者SELECT * FROM Table_name WHERE ASCII(Column_name) = ASCII(‘A’);
Microsoft SQL Server 全文引擎 (MSFTESQL) 不是基于某一特定行中存储的值来构造 B 树结构,而是基于要索引的文本中的各个标记来创建倒排、堆积且压缩的索引结构。
全文索引并不一定能达到like这个谓词的效果,如LIKE ‘%qq%’。这正是本篇文章想要说明的。
如果数据库是在移动盘符上,好像就无法设置:数据库-属性-文件-“使用全文索引”了,这个时候chckbox是不可用的。(这个大家可以求证一下)
关于搜索结果的排序问题,全文索引并没有这个功能,也就是匹配度排序或者说是相似度排序。
Lucene中有一个Similarity类,Lucene Practical Scoring Function就包含了得分的计算公式,tf、idf。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
发现那些未被使用的数据库索引
为了确保快速访问数据,和其他关系型数据库系统一样SQL Server会利用索引来快速的查找数据。然而有太多索引的缺点是不得不维护这些索引,维护也需要代价。
-
DBA如何做好数据库容量管理
一个合格的DBA应该更具前瞻性。也就是说,DBA需要时不时地去关注你的SQL Server数据库系统,即便它是正常运行中的。
-
在information_schema中“创建”和维护表
本文描述information_schema库中表的存在形式,访问时的调用方法,以及在该库中增加一个表需要的修改点。
-
介绍SQL Server聚集索引指示
借助聚集索引来搜索行一般的情况下借助非聚集索引来搜索行快,其主要有两个原因。原因一是聚集索引只包含了一个指向页的指针而不是指向单个数据行的指针。