
(2)RANK( )和DENSE_RANK( )函数
ROW_NUMBER( )函数用于编号,它与排名具有不同的概念。例如,由表1可以看出,班级1中的Grace和Andrew的成绩相同,都是99分。如果使用ROW_NUMBER( )函数编号,有两种编号方案可供选择:一种是Grace第1、Andrew第2,另一种是Andrew第1、Grace第2。这虽然都是正确的,它具有不确定性。
而排名则不同了,它具有确定性,相同的排序值总是被分配相同的排名值。Grace和Andrew在排名的情况下都应当是第1,也就是我们常说的并列第1。那他们两人之后的名次是什么呢?是第2还是第3呢?从两人并列第1的角度讲,他们两人之后的名次应当是第2,这也是DENSE_RANK( )函数的排名方式;前面已经有2个人99分了,他们后面的人应当是第3个高分者,从这个角度理解,后面的名次应当是第3,这也是RANK( )的排名方式。DENSE_RANK( )函数的排名方式我们称之为密集排名,因为它的名次之间没有间隔。
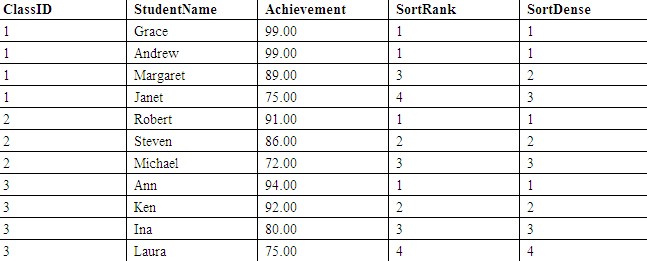
下面的语句演示了RANK( )和DENSE_RANK( )的排名方式,查询结果如表3所示。
| SELECT ClassID, StudentName, Achievement, RANK() OVER(PARTITION BY ClassID ORDER BY Achievement DESC) AS SortRank, DENSE_RANK() OVER(PARTITION BY ClassID ORDER BY Achievement DESC) AS SortDense FROM Students; |
下面是为语句生成的执行计划,与ROW_NUMBER( )相比,执行计划中多出了一个“段”运算符。右边段的分组依据是ClassID,左边段的分组依据是ClassID和Achievement,这是多出的“段”。右边的“段”用于分区操作,在到达下一个分区时发送true信号,“序列射影”运算符会重置排名值。而左边的“段”用于比较排序值是否有变化,如果有变化,则通知“序列射影”运算符递增排名值,递增方式则按RANK( )和DENSE_RANK( )函数的规则进行。

在SQL Server 2005之前,也可以使用子查询的方式实现排名计算。语句的原理就是查询出比当前成绩高的个数,再加上1,就是该成绩的排名。例如,在第1个班级中,比99分高的成绩为0,加上1后,该成绩就是第1名。下面语句的执行结果表3所示相同,但是由于对于每个成绩都要执行两次子查询,在性能方面与RANK( )和DENSE_RANK( )函数相差很远。
| SELECT ClassID, StudentName, Achievement, (SELECT COUNT(*) FROM Students AS S2 WHERE S2.ClassID = S1.ClassID AND S2.Achievement > S1.Achievement)+1 AS SortRank, (SELECT COUNT(DISTINCT achievement) FROM Students AS S2 WHERE S2.ClassID = S1.ClassID AND S2.Achievement > S1.Achievement)+1 AS SortDense FROM Students AS S1 ORDER BY ClassID, Achievement DESC; |
(3)NTILE( )函数
NTILE( )函数用于把行分发到指定数目的组中。各个组有编号,编号从1开始。对于每一个行,NTILE将返回此行所属的组的编号。
NTILE( )函数可以接受一个代表组数量的参数,分组的方式“均分”原则。例如,假设一个表有10行,需要分成2组,则每个组都会有5行。如果表有11行,需要分成3个组,这时候是无法均分的。它分配方法是先得到一个能够整除的基组大小(11/3=3),每组应当分配3行,剩余的2行(11-9)会被再次均分到前面的2组中。
例如,下面的语句指定将Students表按学生成绩划分为3个组,并且Students表恰好也是11行,分组结果如表4所示。
| SELECT ClassID, StudentName, Achievement, NTILE(3) OVER(ORDER BY Achievement DESC) AS Tile FROM Students; |
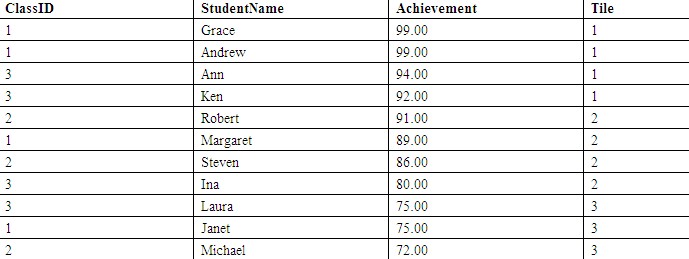
也可以先分区,再分组。例如,下面的语句将每个班级的成绩划分为高、低两组,查询结果如表5所示。可以看出,包含4名学生的班级,每组是2人;包含3名学生的班级,第1组是2人,第2组是1人。
| SELECT ClassID, StudentName, Achievement, CASE NTILE(2) OVER(PARTITION BY ClassID ORDER BY Achievement DESC) WHEN 1 THEN ‘高’ WHEN 2 THEN ‘低’ END AS Tile FROM Students; |
2.基于窗口的聚合计算
在进行聚合计算时,OVER子句中不再需要ORDER BY子句。因此,语法简化成如下格式:
OVER ( [ PARTITION BY value_expression , … [ n ] ]
(1)分区聚合计算与联接的比较
通过OVER子句,可以对每个分区内的数据进行聚合计算。仍旧使用表1所示的Students表的数据,现假设我们需要计算每名学生成绩与本班级平均成绩的差异。在之前,我们需要先计算每个班级的平均成绩,然后通过联接的方式将平均成绩关联到相应的学生成绩行,再计算差异。如:
| SELECT S1.ClassID, S1.StudentName, S1.Achievement, S2.AvgAch , S1.Achievement – S2.AvgAch AS Diff FROM Students AS S1 LEFT OUTER JOIN (SELECT ClassID, AVG(Achievement) AS AvgAch FROM Students GROUP BY ClassID) AS S2 –计算每个班级的平均成绩 ON S1.ClassID = S2.ClassID; |
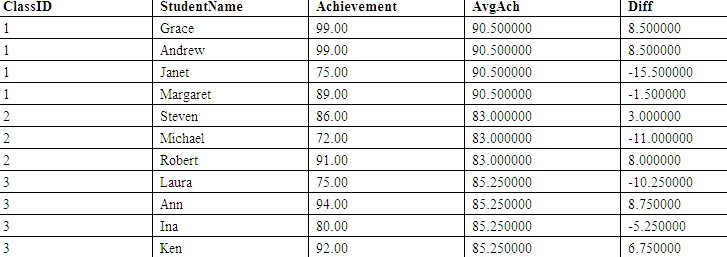
查询结果如表6所示。
在使用OVER子句的情况下,查询语句会简洁许多,下面语句的查询结果与表6相同。
| SELECT ClassID, StudentName, Achievement, AVG(Achievement) OVER(PARTITION BY ClassID) AS AvgAch, Achievement – AVG(Achievement) OVER(PARTITION BY ClassID) AS Diff FROM Students; |
虽然语句有所简洁,但是在性能方面该语句不如上面的联接方式。查询优化器为该语句生成的查询计划比较复杂,与联接语句在同一个批中执行时,含有OVER子句的查询开销占了66%。
(2)对不同类型分区的聚合计算
当在一个语句中需要计算多个不同类型的分区聚合时,OVER子句有着更明显的优势。例如,假设我们既要计算与本班级平均成绩的差异,又要计算与全部学生平均成绩的差异,含有OVER子句的查询变化不大,而使用联结方式则需要增加一个联接。参考下面的语句:
| SELECT ClassID, StudentName, Achievement, AVG(Achievement) OVER(PARTITION BY ClassID) AS AvgAch, Achievement – AVG(Achievement) OVER(PARTITION BY ClassID) AS Diff, AVG(Achievement) OVER() AS AvgAllAch, — 所有学生的平均成绩 Achievement – AVG(Achievement) OVER() AS DiffAll FROM Students; SELECT S1.ClassID, S1.StudentName, S1.Achievement, S2.AvgAch , S1.Achievement – S2.AvgAch AS Diff, S3.AvgAllAch, S1.Achievement – S3.AvgAllAch AS DiffAll FROM Students AS S1 LEFT OUTER JOIN (SELECT ClassID, AVG(Achievement) AS AvgAch FROM Students GROUP BY ClassID) AS S2 ON S1.ClassID = S2.ClassID CROSS JOIN (SELECT AVG(Achievement) AS AvgAllAch FROM Students) AS S3; –增加了一个联接 |
对于语句中所包含的OVER子句数量,对于查询的影响不大。例如,下面的第一条语句仅含有1个OVER子句,而第二条语句则含有4个OVER子句,但是优化器为它们生成的执行计划完全相同。
| SELECT ClassID, StudentName, Achievement, AVG(Achievement) OVER(PARTITION BY ClassID) AS AvgAch FROM Students; SELECT ClassID, StudentName, Achievement, AVG(Achievement) OVER(PARTITION BY ClassID) AS AvgAch, SUM(Achievement) OVER(PARTITION BY ClassID) AS SumAch, MIN(Achievement) OVER(PARTITION BY ClassID) AS MinAch, MAX(Achievement) OVER(PARTITION BY ClassID) AS MaxAch FROM Students; |
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
OpenWorld18大会:Ellison宣布数据库的搜寻和破坏任务
在旧金山举行的甲骨文OpenWorld 2018大会中,甲骨文首席技术官(CTO)兼创始人Larry Elli […]
-
ObjectRocket着力发展Azure MongoDB服务
MongoDB吸引了微软公司的注意力,微软公司计划针对运行于该公司2017年发布的Azure Cosmos D […]
-
数据库和数据仓库的区别在哪儿?
目前,大部分数据仓库还是用数据库进行管理。数据库是整个数据仓库环境的核心,是数据存放的地方和提供对数据检索的支持。
-
如何使用服务来平衡Oracle RAC 数据库工作负载
为不同的应用程序配置不同的服务,DBA可以更有效地平衡集群工作负载,在Oracle RAC数据库环境下实现更好的应用程序性能。