
XML Auto处理比较少的数据
我将使用同一个表做同样的测试,只是读取更少的数据。
首先,我将在ID列上创建一个索引:
Ø create unique clustered index UQ_Employes on Employes (id)
然后,我用WHERE子句查询此表,先查询100条记录,然后查询1000条记录:
100条记录如下:
| SELECT * FROM Employes where id between 5000 and 5100 go SELECT * FROM Employes where id between 5000 and 5100 FOR XML AUTO go SELECT * FROM Employes where id between 5000 and 5100 FOR XML AUTO, TYPE go SELECT * FROM Employes where id between 5000 and 5100 FOR XML AUTO, TYPE, ELEMENTS go SELECT * FROM Employes where id between 5000 and 5100 FOR XML AUTO, TYPE, ELEMENTS, ROOT go |
SQL Profiler显示这些命令的使用没有实质差别:
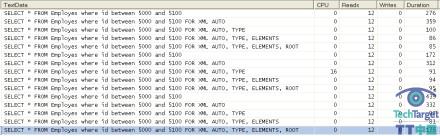
同样,没有创建工作表,且所有的命令有着相同数量的工作:
| Table ‘Employes’. Scan count 1, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table ‘Employes’. Scan count 1, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table ‘Employes’. Scan count 1, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table ‘Employes’. Scan count 1, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table ‘Employes’. Scan count 1, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
执行计划同样也显示了相同的工作量:
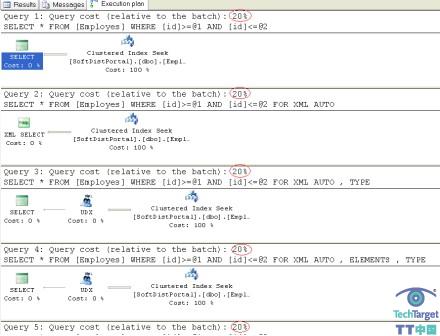
1000条记录:
| SELECT * FROM Employes where id between 5000 and 6000 go SELECT * FROM Employes where id between 5000 and 6000 FOR XML AUTO go SELECT * FROM Employes where id between 5000 and 6000 FOR XML AUTO, TYPE go SELECT * FROM Employes where id between 5000 and 6000 FOR XML AUTO, TYPE, ELEMENTS go SELECT * FROM Employes where id between 5000 and 6000 FOR XML AUTO, TYPE, ELEMENTS, ROOT go |
SQL Profiler:
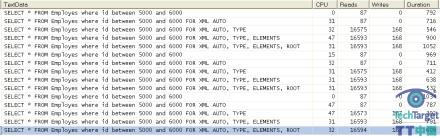
I/O统计:
| Table ‘Employes’. Scan count 1, logical reads 87, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table ‘Employes’. Scan count 1, logical reads 87, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table ‘Employes’. Scan count 1, logical reads 87, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table ‘Worktable’. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 5222, lob physical reads 0, lob read-ahead reads 242. Table ‘Employes’. Scan count 1, logical reads 87, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table ‘Worktable’. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 5229, lob physical reads 0, lob read-ahead reads 245. Table ‘Employes’. Scan count 1, logical reads 87, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table ‘Worktable’. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 5229, lob physical reads 0, lob read-ahead reads 245. |
执行计划:
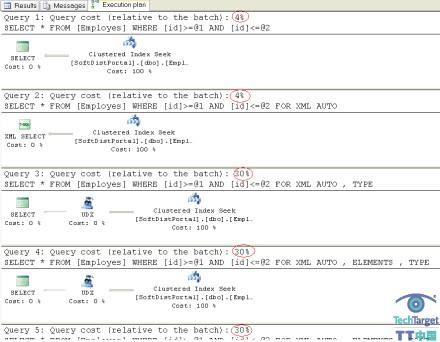
何时使用工作表?
在优化器中使用工作表有何限制呢?这取决于优化器处理内存的工作量及XML分析器中的数据量。我的查询返回的XML被存储在内存中的一个大的XML变量中。以上限制不是一个明确的数据。SQL Server Developer Center的技术人员表示:“XML类型的变量和参数可达2GB。数据量小的时候,它们使用主存,但是,大数据量时被存储在tempdb中”。
结论:
XML数据和函数比标准的T-SQL要使用更多的资源。因此,如果查询处理大量数据时或XML函数更加复杂,就考虑在数据库级别上使用标准的T-SQL。通常建议大家测试XML性能,来确保在数据库中使用XML不会降低应用的性能。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
翻译
相关推荐
-
OpenWorld18大会:Ellison宣布数据库的搜寻和破坏任务
在旧金山举行的甲骨文OpenWorld 2018大会中,甲骨文首席技术官(CTO)兼创始人Larry Elli […]
-
ObjectRocket着力发展Azure MongoDB服务
MongoDB吸引了微软公司的注意力,微软公司计划针对运行于该公司2017年发布的Azure Cosmos D […]
-
Notre Dame对云端SQL Server性能基准的探索实践
确立SQL Server的性能基准,对于云端迁移来说是至关重要的第一步,一位来自于University of Notre Dame 的DBA表示,他正在试图通过数据库监控软件,找出SQL server的性能基准。
-
DBA必须掌握的数据库恢复管理技术
如果没有备份副本,数据库管理员就无法还原数据库,所以DBA在恢复之前倾向于考虑备份是合乎逻辑的。 但是,对我来说,这种逻辑一直是错误的。