
用Oracle数据库10g通过回收浪费的空间、联机重组表格和评估增长的趋势,有效地在段中进行存储管理。近来,有人要求我评估一个与 Oracle 数据库竞争的RDBMS。在供应商的演示过程中,观众认为“最棒”的特性是,对联机重组的支持——该产品可以联机重新部署数据块,以使段的等价物更简洁,并且不会影响当前的用户。
那时,Oracle还没有在Oracle 9i数据库中提供这种功能。但是现在,有了Oracle数据库10g,就可以轻松地联机回收浪费的空间和压缩对象——正好适合于起步者。
不过,在检验该特性之前,让我们看一看处理这项任务的“传统的”方法。
当前惯例
考虑让我们看一个段,如一张表,其中填满了块,如图1 所示。在正常操作过程中,删除了一些行,如图2 所示。现有就有了许多浪费的空间:(i)在表的上一个末端和现有的块之间,以及(ii)在块内部,其中还有一些没有删除的行。

图 1:分配给该表的块。用灰色正方形表示行
Oracle不会释放空间以供其他对象使用,有一条简单的理由:由于空间是为新插入的行保留的,并且要适应现有行的增长。被占用的最高空间称为最高使用标记(HWM),如图2所示:
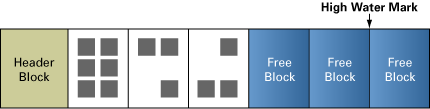
图 2:行后面的块已经删除了;HWM 仍保持不变
但是,这种方法有两个主要的问题:
当用户发出一个全表扫描时,Oracle始终必须从段一直扫描到HWM,即使它什么也没有发现。该任务延长了全表扫描的时间。
当用直接路径插入行时 — 例如,通过直接加载插入(用APPEND提示插入)或通过SQL*Loader直接路径 — 数据块直接置于HWM之上。它下面的空间就浪费掉了。
在Oracle9i及其以前的版本中,可以通过删除表,然后重建表并重新加载数据来回收空间;或通过使用ALTER TABLE MOVE命令把表移动到一个不同的表空间中来回收空间。这两种处理方式都必须脱机进行。另外,可以使用联机表重组特性,但是这需要至少双倍的现有表空间。
在10g中,该任务已经变得微不足道了;假如您的表空间中支持自动段空间管理(ASSM),您现在可以缩小段、表和索引,以回收空闲块并把它们提供给数据库以作他用,让我们看看其中的缘由。
10g中的段管理方式
设想有一个表BOOKINGS,它保存有经由Web站点的联机登记。当一个登记确认后,就会把它存储在一个存档表BOOKINGS_HIST中,并从BOOKINGS表中删除该行。登记和确认之间的时间间隔依据客户有很大的不同,由于无法从删除的行获得足够的空间,因此许多行就插入到了表的 HWM 之上。
现在您需要回收浪费的空间。首先,准确地查明在可回收的段中浪费了多少空间。由于它是在支持ASSM的表空间中,您将不得不使用DBMS_SPACE包的SPACE_USAGE过程,如下所示:
| declare l_fs1_bytes number; l_fs2_bytes number; l_fs3_bytes number; l_fs4_bytes number; l_fs1_blocks number; l_fs2_blocks number; l_fs3_blocks number; l_fs4_blocks number; l_full_bytes number; l_full_blocks number; l_unformatted_bytes number; l_unformatted_blocks number; begin dbms_space.space_usage( segment_owner => user, segment_name => ‘BOOKINGS’, segment_type => ‘TABLE’, fs1_bytes => l_fs1_bytes, fs1_blocks => l_fs1_blocks, fs2_bytes => l_fs2_bytes, fs2_blocks => l_fs2_blocks, fs3_bytes => l_fs3_bytes, fs3_blocks => l_fs3_blocks, fs4_bytes => l_fs4_bytes, fs4_blocks => l_fs4_blocks, full_bytes => l_full_bytes, full_blocks=> l_full_blocks, unformatted_blocks => l_unformatted_blocks, unformatted_bytes => l_unformatted_bytes ); dbms_output.put_line(‘ FS1 Blocks = ‘ ||l_fs1_blocks||’ Bytes = ‘||l_fs1_bytes); dbms_output.put_line(‘ FS2 Blocks = ‘ ||l_fs2_blocks||’ Bytes = ‘||l_fs1_bytes); dbms_output.put_line(‘ FS3 Blocks = ‘ ||l_fs3_blocks||’ Bytes = ‘||l_fs1_bytes); dbms_output.put_line(‘ FS4 Blocks = ‘ ||l_fs4_blocks||’ Bytes = ‘||l_fs1_bytes); dbms_output.put_line(‘Full Blocks = ‘ ||l_full_blocks||’ Bytes = ||l_full_bytes); end; / |
输出结果如下:
FS1 Blocks = 0 Bytes = 0 FS2 Blocks = 0 Bytes = 0 FS3 Blocks = 0 Bytes = 0 FS4 Blocks = 4148 Bytes = 0 Full Blocks = 2 Bytes = 16384 |
这个输出结果显示有4,148个块,具有75-100%的空闲空间(FS4);没有其他空闲块可用。这里仅有两个得到完全使用的块。4,148个块都可以回收。
接下来,您必须确保该表支持行移动。如果不支持,您可以使用如下命令来支持它:
alter table bookings enable row movement;
或通过Administration页上的企业管理器10g。您还要确保在该表上禁用所有基于行id的触发器,这是因为行将会移动,行id可能会发生改变。
最后,您可以通过以下命令重组该表中现有的行:
alter table bookings shrink space compact;
该命令将会在块内重新分配行,如图3所示,这就在HWM之下产生了更多的空闲块,但是HWM自身不会进行分配。
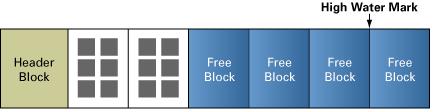
图 3:重组行后的表中的块
在执行该操作后,让我们看一看空间利用率所发生的改变。使用在第一步展示的PL/SQL块,可以看到块现在是如何组织的:
FS1 Blocks = 0 Bytes = 0 FS2 Blocks = 0 Bytes = 0 FS3 Blocks = 1 Bytes = 0 FS4 Blocks = 0 Bytes = 0 Full Blocks = 2 Bytes = 16384 |
注意这里的重要改变:FS4块(具有75-100%的空闲空间)的数量现在从4,148降为0。我们还看到FS3块(具有50-75%的空闲空间)的数量从0增加到1。但是,由于HWM没有被重置,总的空间利用率仍然是相同的。我们可以用如下命令检查使用的空间:
| SQL> select blocks from user_segments where segment_name = ‘BOOKINGS’; BLOCKS ——— 4224 |
由该表占用的块的数量(4,224)仍然是相同的,这是因为并没有把 HWM 从其原始位置移开。可以把HWM移动到一个较低的位置,并用如下命令回收空间:
alter table bookings shrink space;
注意子句COMPACT 没有出现。该操作将把未用的块返回给数据库并重置HWM。可以通过检查分配给表的空间来对其进行测试:
SQL> select blocks from user_segments where segment_name = ‘BOOKINGS’; BLOCKS ———- 8 |
块的数量从4,224降为8;该表内所有未用的空间都返回给表空间,以让其他段使用,如图4 所示。
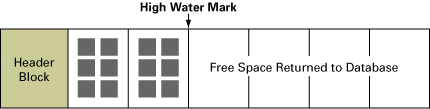
图 4:在收缩后,把空闲块返回给数据库
这个收缩操作完全是在联机状态下发生的,并且不会对用户产生影响。
也可以用一条语句来压缩表的索引:
alter table bookings shrink space cascade;
联机shrink命令是一个用于回收浪费的空间和重置HWM的强大的特性。我把后者(重置HWM)看作该命令最有用的结果,因为它改进了全表扫描的性能。
找到收缩合适选择
在执行联机收缩前,用户可能想通过确定能够进行最完全压缩的段,以找出最大的回报。只需简单地使用dbms_space包中的内置函数verify_shrink_candidate。如果段可以收缩到1,300,000字节,则可以使用下面的PL/SQL代码进行测试:
begin if (dbms_space.verify_shrink_candidate (‘ARUP’,’BOOKINGS’,’TABLE’,1300000) then 😡 := ‘T’; else 😡 := ‘F’; end if; end; / |
PL/SQL过程成功完成。
| SQL> print x X ——————————– T 如果目标收缩使用了一个较小的数,如 3,000: begin if (dbms_space.verify_shrink_candidate (‘ARUP’,’BOOKINGS’,’TABLE’,30000) then 😡 := ‘T’; else 😡 := ‘F’; end if; end; |
变量x 的值被设置成’F’,意味着表无法收缩到3,000字节。现在假定您将着手在一个表上,或者也许是一组表上创建一个索引的任务。除了普通的结构元素,如列和单值性外,您将不得不考虑的最重要的事情是索引的预期大小 — 必须确保表空间有足够的空间来存放新索引。
在Oracle数据库9i 及其以前的版本中,许多DBA使用了大量的工具(从电子数据表到独立程序)来估计将来索引的大小。在10g中,通过使用DBMS_SPACE包,使这项任务变得极其微不足道。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Collaborate 18大会:了解甲骨文云数据库和应用的进展
在Collaborate 18大会即将举行时,我们会发现,甲骨文用户社区的技术变化会略高于平常水平。 由独立甲 […]
-
甲骨文自治数据库亮相 带来云计算新希望
早前甲骨文还不在云计算公司之列,而现在该公司正在迅速弥补其失去的时间。甲骨文的云计算核心是甲骨文自治数据库(O […]
-
2017年12月数据库流行度排行榜 定格岁末排名瞬间
数据库知识网站DB-engines最近更新的2017年12月份数据库流行度排名情况是否能提供更多的看点呢?TechTarget数据库网站将与您分享12月份的榜单排名情况,让我们拭目以待。
-
2017年11月数据库流行度排行榜 半数以上数据库积分减少
数据库知识网站DB-engines更新了2016年11月份的数据库流行度排行榜。TechTarget数据库网站将与您一同关注11月份的榜单排名情况。