
索引和表的维护
重新组织索引
随着数据的不断删除,插入和更新,索引页会变得越来越零散,索引页的物理存储顺序不再匹配其逻辑顺序,索引结构的层次会变得过大,这些都会导致索引页的预读取变得效率低下。因此,根据数据更新的频繁程度需要适当的重新组织索引。可以使用 REORG INDEXES 命令来重新组织索引结构,也可以删除并重新创建索引达到相同的目的。同样的,对表进行重新组织也会带来性能的改善。
重新组织某一个表的所有索引的命令如下:REORG INDEXES ALL FOR TABLE table_name。
重新组织一个表的数据的命令如下,在下面的命令还可以为其指定一个特定的索引,REORG 命令将会根据这个索引的排序方式重新组织该表的数据。
REORG TABLE table_name INDEX index_name。
重新收集表和索引的统计信息
和在2.1中提到的原因类似,当一个表经过大量的索引修改、数据量变化或者重新组织后,可能需要重新收集表以及相关索引的统计信息。这些统计信息主要是关于表和索引存储的物理特性,包括记录数目,数据页的数目以及记录的平均长度等。优化器将根据这些信息决定使用什么样的存取计划来访问数据。因此,不能真实反映实际情况的统计信息可能会导致优化器选择错误的存取计划。收集表及其所有索引的统计信息的命令如下:RUNSTATS ON TABLE table_name FOR INDEXES ALL。
上述两个命令具有复杂的参数选择,用户可以参阅DB2 Info Center来根据实际情况使用这两个命令。
修改查询
合理使用NOT IN和NOT EXISTS
一般情况下NOT EXISTS具有快于 NOT IN 的性能,但是这并不绝对。根据具体的数据情况、存在的索引以及查询的结构等因素,两者会有较大的性能差异,开发人员需要根据实际情况选择适当的方式。
譬如下面的查询:
清单10. 查询示例
表结构:temp.customer(cust_num) 主键:cust_num 表结构:temp.contact(cnt_id,cust_num) 主键:cnt_id 表结构:temp.contact_detail(cnt_id,address,phone) 主键:cnt_id 查询 : select cust_num from temp.customer cust where not exists (select 1 from temp.contact cont here cust.cust_num = cont.cust_num) |
此查询用来列出所有不存在联系人的客户。对于这样的需求,开发人员会最自然的写出清单 10 中的查询,的确,对于大部分情况它具有最优的性能。该查询的查询代价为 178,430 timerons。让我们再来看看使用 NOT IN 后查询的总代价,请看清单 11。
清单11. 查询示例
查询: select cust_num from temp.customer cust where cust.cust_num not in (select cont.cust_num from temp.contact cont) 代价:12,648,897,536 timerons |
可以看到 NOT EXISTS 的性能要比 NOT IN 高出许多。NOT IN 是自内向外的操作,即先得到子查询的结果,然后执行最外层的查询,而 NOT EXISTS 恰好相反,是自外向内的操作。在上述例子中,temp.contact 表中有 65 万条记录,使得 10.2 查询中的 NOT IN 列表非常大,导致了使用 NOT IN 的查询具有非常高的查询代价。下面我们对 10.1 和 10.2 的查询进行修改,将 temp.contact 表中的记录限制到 100 条,请看下面的查询:
清单12. 查询示例
查询: select cust_num from temp.customer cust where not exists (select 1 from temp.contact cont here cust.cust_num = cont.cust_num and cont.cnt_id < 100) 代价:42,015 timerons |
清单13. 查询示例:
| 查询: select cust_num from temp.customer cust where cust.cust_num not in (select cont.cust_num from temp.contact cont where cont.cnt_id < 100) 代价:917,804 timerons |
从 12 和 13 中可以看出 NOT EXISTS 的查询代价随子查询返回的结果集的变化没有大幅度的下降,随着子查询的结果集从 65 万下降到 100 条,NOT EXISTS 的查询代价从 178,430 下降到 42,015,只下降 4 倍。但是 NOT IN 的查询代价却有着极大的变化,其查询代价从 12,648,897,536 下降到 917,804,下降了 13782 倍。可见子查询的结果集对 NOT IN 的性能影响很大,但是这个简单的查询不能说明 NOT EXISTS 永远好于 NOT IN,因为同样存在一些因素对 NOT EXISTS 的性能有很大的影响。我们再看下面的例子
清单14. 查询示例
查询: select cust_num from temp.customer cust where not exists (select 1 from temp.contact cont where cust.cust_num = cont.cust_num and cont.cnt_id in (select cnt_id from temp.contact_detail where cnt_id<100)) 代价:5,263,096 timerons |
清单15. 查询示例
查询: select cust_num from temp.customer cust where cust_num not in (select cust_num from temp.contact cont where cont.cnt_id in (select cnt_id from temp.contact_detail where cnt_id<100)) 代价:4,289,095 timerons |
在上面的例子中,我们只是对查询增加了一个小改动,使用一个嵌套查询限制了在 temp.contact 中扫描的范围。但是在这两个新的查询中,NOT IN 的性能却又好于 NOT EXISTS。NOT EXISTS 的代价增加了 125 倍,而 NOT IN 的代价却只增加了 4 倍。这是由于 NOT EXISTS 是自外向内,嵌套查询的复杂度对其存在较大的影响。因此在实际应用中,要考虑子查询的结果集以及子查询的复杂度来决定使用 NOT EXISTS 或者 NOT IN。对于 IN,EXISTS 和 JOIN 等操作,大多数情况下 DB2 优化器都能形成比较一致的最终查询计划。
合理使用子查询减少数据扫描和利用索引
某些情况下可以将查询中的某一部分逻辑提取出来作为子查询出现,能够减少扫描的数据量,以及利用索引进行数据检索。请看清单 16 中的查询:
清单 16:
索引:temp.cust_i1 on temp.customer(add_date) temp.order_i1 on temp.order(sold_to_cust_num) temp.order_i2 on temp.order(add_date) 查询: select cust.cust_num from temp.customer cust left join temp.order ord on cust.cust_num = ord.sold_to_cust_num where cust.add_date > current timestamp – 2 months or ord.add_date > current timestamp – 2 months |
上面的查询用来选择所有两个月内新增加的用户以及在两个月内定购了产品的用户。从图 10.a 的查询计划中可看出没有任何索引被使用。
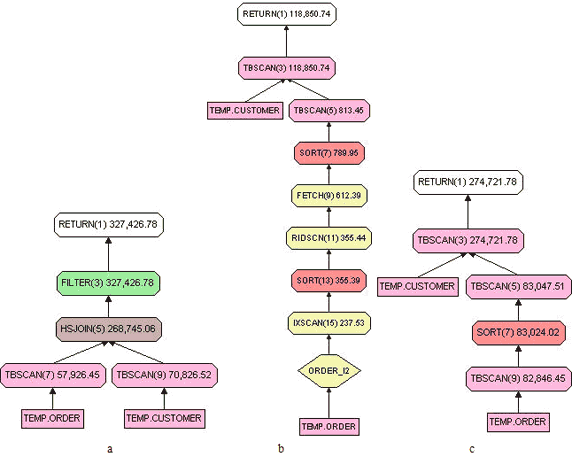
图 10. 查询计划
使用子查询对该查询重新改写后,请看清单 17:
清单17.
查询: with tmp as( select sold_to_cust_num from temp.order where add_date > current timestamp – 2 months) select cust.cust_num from temp.customer cust where cust.add_date > current timestamp – 2 months or cust.cust_num in (select sold_to_cust_num from tmp ) |
在清单 17 的查询中,我们使用子查询预先限定了要扫描 temp.order 表中的记录数目,而不是像清单 16 中的查询那样对 temp.order 表进行全表扫描。同时,在预先限定数据范围的时候,能够利用 temp.order_i2 索引。请看其查询计划,如图 10.b。可以看到查询代价有大幅度下降。其实,即使没有 temp.order_i2 索引,修改后的查询也仍然由于前者,因为它预先限定了数据的扫描范围,也减少了后续连接处理的数据量,请看图 10.c。
重新排列各个表的连接顺序,尽量减小中间结果集的数据量
一般情况下,DB2 会根据各表的 JOIN 顺序自顶向下顺序处理,因此合理排列各表的连接顺序会提高查询性能。譬如清单 18 中的查询:
清单18.
查询: select cust.cust_name, ord.order_num, cnt.cnt_first_name from temp.customer cust left join temp.order ord on cust.cust_num = ord.sold_to_cust_num join temp.contact cnt on cust.cust_num = cnt.cust_num where cnt.mod_date > current timestamp – 1 months |
清单 18 中的查询用来选择出所有最近一个月内修改过联系人信息的客户的订单信息。此查询会按照链接的顺序先将 temp.customer 表和 temp.order 表进行 LEFT JOIN,然后使用结果集去 JOIN temp.contact 表。由于该查询使用了 LEFT JOIN,因此在生成中间结果集的时候不会有任何记录会被过滤掉,中间结果集的记录数目大于等于 temp.customer 表。了解到了 DB2 是如何解释和执行这样的查询后,很自然的我们就会想到将 JOIN 提前。请看清单 19。
清单19.
查询: select cust.cust_name, ord.order_num, cnt.cnt_first_name from temp.customer cust join temp.contact cnt on cust.cust_num = cnt.cust_num left join temp.order ord on cust.cust_num = ord.sold_to_cust_num where cnt.mod_date > current timestamp – 1 months |
图 11.a 和图 11.b 分别为清单 18 和 19 的查询的存取计划。在 19 的查询中,在形成中间结果集的时候也应用到了 WHERE 语句中的条件,而不是在所有 JOIN 都结束以后才被应用去除记录的。
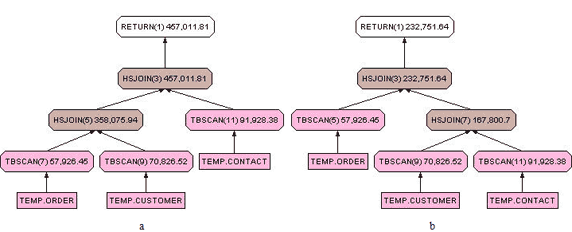
图11. 查询计划
另外,在修改查询尽量减少中间结果集的记录条数的时候还要考虑中间结果集的数据总量,譬如中间结果集需要保存的每条记录的长度。如果我们把 JOIN temp.contact 提前以后,由于中间结果集需要保存过多的 contact 表的列反而使得结果集的数据总量变大,可能不会带来性能上的改善。
使用UDF代替查询中复杂的部分
由于 UDF 是预先编译的,性能普遍优于一般的查询,UDF 使用的存取计划一经编译就会相对稳定。笔者在工作中曾多次发现,使用 UDF 代替查询或者视图中的复杂部分会提高几倍甚至几十倍的性能,主要原因是迫使 DB2 使用指定的存取计划来充分利用 index 或者调整其访问过程(如 Join 顺序, Filter 位置等)。使用 UDF 进行优化的基本思路是,将复杂查询分解为多个部分执行,针对每个部分优化处理,将各部分组合时能够避免存取计划的一些不必要变化,优化整体性能。譬如清单 20 中的查询:
清单20.
查询:select * from temp.customer where cust_num in ( select distinct sold_to_cust_num from temp.order where add_date > current timestamp – 2 months union select distinct cust_num from temp.contact where add_date > current timestamp – 2 months ) |
这个查询会导致优化器生成比较复杂的查询计划,尤其是 temp.customer 是一个比较复杂的视图的时候。这种情况下我们可以通过创建 UDF,将其分步执行:先执行子查询获得 cust_num 值的列表,然后执行最外层的查询。下面的例子是通过 UDF 对清单 20 的查询的改写:
清单21.
CREATE FUNCTION temp.getCustNum(p_date timestamp) RETURNS TABLE (cust_num CHARACTER(10)) RETURN select distinct sold_to_cust_num from temp.order where add_date > p_date union select distinct cust_num from temp.contact where add_date > p_date; select * from customer where cust_num in ( select cust_num from table(temp.getCustNum(current timestamp – 2 months)) tbl ) |
改写前后的查询代价分别是 445,159.31 和 254,436.98。当面对比较复杂的查询时考虑使用 UDF 将其拆分为多步执行常常会带来意想不到的效果。在实际的项目中,如果数据处理和查询调用是包含在其他应用程序中如 Unix 脚本,Java 程序等,同样可以考虑采用分步数据处理的方式来调用数据库,以优化应用性能。
总结
本文主要介绍了如何使用 DB2 提供的各种查看存取计划的工具,并根据作者在 DB2 方面的开发经验总结了一些提高查询性能的方法和技巧。如果能够有效地利用 DB2 提供的各种工具,理解 DB2 中索引的结构,以及查询将如何被解释,数据库开发人员可以更好的提高查询性能来满足需求。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
数据库产品巡礼:IBM DB2概览
IBM DB2关系型数据库管理系统提供了支持多平台系统的关键技术,它具备较高的可用性和良好的性能。
-
IBM加入Spark社区 计划培养百万数据科学家
IBM近日宣布,将大力推进Apache Spark项目,并计划培养超过100万名Spark数据科学家和数据工程师。
-
IBM成立物联网部门旨在整合未用数据
IBM准备在未来四年投资30亿美元成立一个专门的物联网(IoT)部门,并由此建立一个基于云的开放平台来帮助客户进行更好的数据整合。
-
ODP项目能否成为Hadoop助推器?
开放数据平台联盟的成立旨在为了推动Hadoop的标准化,但项目能否最终成功,或能否项向着承诺的方向发展,还有很多不确定因素。