
决策树算法是由Microsoft SQL Server Analysis Services提供的分类和回归算法,用于对离散和连续属性进行预测性建模。
对于离散属性,该算法根据数据集中输入列之间的关系进行预测。它使用这些列的值(也称之为状态)预测指定为可预测的列的状态。具体地说,该算法标识与可预测列相关的输入列。例如,在预测哪些客户可能购买自行车的方案中,假如在十名年轻客户中有九名购买了自行车,但在十名年龄较大的客户中只有两名购买了自行车,则该算法从中推断出年龄是自行车购买情况的最佳预测因子。决策树根据朝向特定结果发展的趋势进行预测。
对于连续属性,该算法使用线性回归确定决策树的拆分位置。
如果将多个列设置为可预测列,或输入数据中包含设置为可预测的嵌套表,则该算法将为每个可预测列生成一个单独的决策树。
示例
Adventure Works Cycles公司的市场部希望标识以前的客户的某些特征,这些特征可能指示这些客户将来是否有可能购买其产品。AdventureWorks数据库存储描述其以前客户的人口统计信息。通过使用Microsoft决策树算法分析这些信息,市场部可以生成一个模型,该模型根据有关特定客户的已知列的状态(如人口统计或以前的购买模式)预测该客户是否会购买产品。
算法的原理
决策树算法通过在树中创建一系列拆分来生成数据挖掘模型。这些拆分以“节点”来表示。每当发现输入列与可预测列密切相关时,该算法便会向该模型中添加一个节点。该算法确定拆分的方式不同,主要取决于它预测的是连续列还是离散列。
决策树算法使用“功能选择”来指导如何选择最有用的属性。所有Analysis Services数据挖掘算法均使用功能选择来改善分析的性能和质量。功能选择对防止不重要的属性占用处理器时间意义重大。如果在设计数据挖掘模型时使用过多的输入或可预测属性,则可能需要很长的时间来处理该模型,甚至导致内存不足。用于确定是否拆分树的方法包括对“平均信息量”和Bayesian网络的行业标准度量。
数据挖掘模型中的常见问题是该模型对定型数据中的细微差异过于敏感,这种情况称为“过度拟合”或“过度定型”。过度拟合模型无法推广到其他数据集。为避免模型对任何特定的数据集过度拟合,Microsoft决策树算法使用一些技术来控制树的生长。
预测离散列
通过柱状图可以演示Microsoft决策树算法为可预测的离散列生成树的方式。下面的关系图显示了一个根据输入列 Age 绘出可预测列 Bike Buyers 的柱状图。该柱状图显示了客户的年龄可帮助判断该客户是否将会购买自行车。
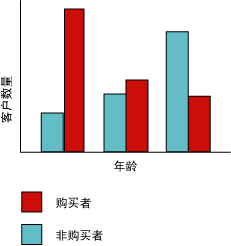
该关系图中显示的关联将会使Microsoft决策树算法在模型中创建一个新节点。
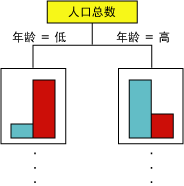
随着算法不断向模型中添加新节点,便形成了树结构。该树的顶端节点描述了客户总体可预测列的分解。随着模型的不断增大,该算法将考虑所有列。
预测连续列
当Microsoft决策树算法根据可预测的连续列生成树时,每个节点都包含一个回归公式。拆分出现在回归公式的每个非线性点处。例如,请看下面的关系图。
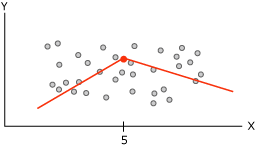
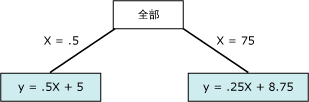
该关系图包含可通过使用一条或两条连线建模的数据。不过,一条连线将使得模型表示数据的效果较差。相反,如果使用两条连线,则模型可以更精确地逼近数据。两条连线的相交点是非线性点,并且是决策树模型中的节点将拆分的点。例如,与上图中的非线性点相对应的节点可以由以下关系图表示。两个等式表示两条连线的回归等式。
决策树模型所需的数据
在准备用于决策树模型的数据时,应了解特定算法的要求,其中包括所需的数据量以及数据的使用方式。
决策树模型的要求如下:
单个key列:每个模型都必须包含一个数值或文本列,用于唯一标识每条记录。不允许复合键。
可预测列:至少需要一个可预测列。可以在模型中包括多个可预测属性,并且这些可预测属性的类型可以不同,可以是数值型或离散型。不过,增加可预测属性的数目可导致处理时间增加。
输入列:需要输入列,可为离散型或连续型。增加输入属性的数目会影响处理时间。
查看决策树模型
若要浏览该模型,可以使用“Microsoft 树查看器”。如果模型生成多个树,则可以选择其中一个树,然后该查看器即会显示对于每个可预测属性,这些事例分类方式的明细。还可以使用依赖关系网络查看器来查看这些树的交互。
如果想了解关于树中任何分支或节点的更多详细信息,还可以使用 Microsoft 一般内容树查看器浏览该模型。为该模型存储的内容包括每个节点中所有值的分布、树中每一级别的概率和连续属性的回归公式。
创建预测
处理过模型之后,结果将以一组模式和统计信息的形式存储,可以使用这些结果来研究关系或作出预测。
注释
- 支持使用预测模型标记语言 (PMML) 创建挖掘模型。
- 支持钻取。
- 支持使用 OLAP 挖掘模型和创建数据挖掘维度。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
SQL Server 2008将退出微软主流数据库支持
你的企业是否还在运行SQL Server 2008?请注意微软为SQL Server 2008提供的主流技术支持服务将于今年的7月8日正式结束。
-
使用Apache Hadoop挖掘现有数据
本文介绍了如何使用Apache Hadoop挖掘您的数据,并将数据转换为可以轻松供给一个基于 web 的报表应用程序的数据。
-
当业务分析师遭遇预测分析软件
在刚刚发布的胜利指数报告中,Hurwitz & Associates公司对业界12家预测分析厂商进行了评定,从市场占有率和客户两方面,Hurwitz将IBM SPSS和SAS评为“胜利者”。
-
数据科学家如何解决预测分析的难题
TechTarget网站最近就关于数据科学家及将来他们如何使用预言分析探寻结果的问题采访了Metamarkets的首席技术官和Michael Drisoll。