
如果只查询少量数据,或者查询还包含其他选择性谓词,使得大写谓词只应用于很小的中间结果集,那么这种方式效果还不错。问题是如果使用包含fn:upper-case() 函数的谓词,就不会使用DB2中的XML索引。因此,这种方式不适用于大量数据。
要想避免使用fn:upper-case()函数并利用 XML 索引加快查询,就需要创建不区分大小写的数据库。
创建不区分大小写的DB2数据库
DB2 从 Version 9.5 Fixpack 1 开始支持感知地区的 Unicode 排序规则。这使我们能够忽略大小写和/或重音符号。要想创建对于所有字符串比较不区分大小写的数据库,需要使用排序规则 UCA500R1,见 清单 4。
清单 4. 创建不区分大小写的数据库
CREATE DATABASE testdbUSING CODESET UTF-8 TERRITORY USCOLLATE USING UCA500R1_LEN_S2; |
字符串 UCA500R1_LEN_S2 究竟意味着什么?UCA500R1 指定此数据库使用基于 Unicode 5.0.0 标准的默认 Unicode Collation Algorithm(UCA)。因为默认的 UCA 不能同时覆盖 Unicode 支持的每种语言的排序规则序列,所以可以使用可选属性定制字符的次序。属性以下划线(_)分隔。UCA500R1 关键字加上所有属性构成一个 UCA 排序规则名。
清单 4 中使用的排序规则名包含两个属性:LEN 和 S2。LEN 是 L(语言)和 EN(英语的 ISO 639-1 语言编码)的组合。第二个属性 S2 指定强度级别,这决定在字符串排序或比较时是否考虑大小写或重音符号。在 清单 4 中使用强度级别 2,所以 “PARIS” 和 “paris” 是相等的。下面是其他有效值的示例:
UCA500R1_LEN_S1 导致 “cliche” = “Cliche” = “cliché” UCA500R1_LEN_S2 导致 “cliche” = “Cliche” < “cliché” UCA500R1_LEN_S3 导致 “cliche” < “Cliche” < “cliché” |
在DB2 Information Center中可以找到可以作为UCA排序规则名的所有组合(参见 参考资料)。
在不区分大小写的数据库中查询XML数据
因为此数据库使用排序规则名UCA500R1和强度级别2,所以现在可以简化前面的查询,去掉fn:upper-case() 函数(清单 5),就像所有数据都是大写的一样。无论搜索字符串是 “Paris” 或 “PARIS” 还是其他任何大小写组合,结果都是相同的。
清单5. 选择Paris的客户
SELECT id, XMLCAST( XMLQUERY(‘$XMLDOC/Customer/city’) AS VARCHAR(15)) AS cityFROM customerWHERE XMLEXISTS(‘$XMLDOC/Customer[city = “PARIS”]’); |
图2. 示例查询的结果
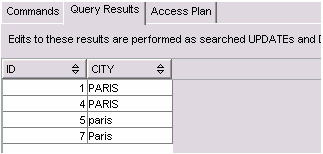
如果通过添加ORDER BY子句按提取的city值排序,那么结果集仍然是相同的:PARIS、paris和Paris被当作相同的值。
为了高效地查询此数据,尤其是在表中行数很大的情况下,应该用 XPath /Customer/city 创建一个 XML 索引,见 清单 6:
清单6. 创建XML索引
CREATE INDEX customer_lang_idx ON test (xmldoc)GENERATE KEY USING XMLPATTERN ‘/Customer/city’ AS SQL VARCHAR(15); |
现在,如果用Visual Explain或db2exfmt解释此查询,就会看到这个不区分大小写的搜索使用了索引:
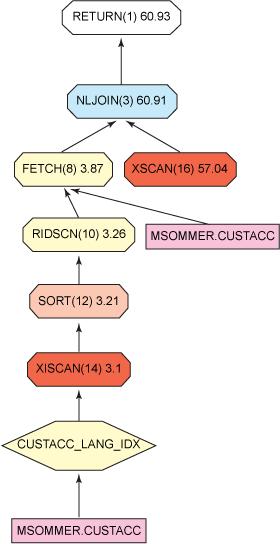
图3. 在不区分大小写的数据库中查询Paris的所有客户的Explain Plan
本节介绍的方法有一个潜在的缺点:整个数据库中所有表中的所有列中的所有数据都是不区分大小写的。不可能以区分大小写的方式处理特定的表或列。要么都区分大小写,要么都不区分。
注意,不区分大小写只应用于元素和属性值,而不应用于标记名本身。XML 标记和路径表达式仍然是区分大小写的。例如,XPath 表达式 /Customer/city(小写 “c”)和 /Customer/City(大写 “C”)是不同的。后者不匹配示例数据中的任何元素,因为示例数据中的 <CITY>元素名是小写的。
性能
在数据库中使用定制的排序规则可能影响查询性能,因为在选择更宽松的 UCA 设置时,匹配的字符串数量可能会增加。换句话说,在不区分大小写的数据库中,字符串比较的开销可能会略微增加。为了查明区分大小写的和不区分大小写的数据库之间的性能差异,我们创建了一个常规数据库(区分大小写)和一个不区分大小写的数据库。然后,插入来自 TPoX 基准测试的 20,000 个 CustAcc 文档并在这两个数据库中对各种查询进行测试。
对于只涉及少量到中等数量的行的查询,两个测试数据库之间的性能差异可以忽略不计。我们发现涉及大量行的查询的性能差异比较大,比如对所有20,000个XML文档进行全表扫描并对每个文档比较字符串。在不区分大小写的数据库中,这种查询花费的时间增加了 5% 到 8%。因此,实现不区分大小写的搜索需要付出的代价并不大。
结束语
以不区分大小写的方式搜索DB 2数据有多种方法,比如使用生成的列。尽管这些方法都适合关系数据,但是不适合查询XML数据。以不区分大小写的方式处理XML数据的最佳方法是用定制的Unicode排序规则创建数据库。这使数据库中的所有字符串值比较都采用不区分大小写的方式,避免妨碍使用XML索引和关系索引。由于不区分大小写或重音符号,会增加匹配的字符串,但是增加的开销非常低。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
数据库产品巡礼:IBM DB2概览
IBM DB2关系型数据库管理系统提供了支持多平台系统的关键技术,它具备较高的可用性和良好的性能。
-
如何进行分布式大数据应用调优
分布式环境通常是与数据库服务器相分离的。而DBA的工作就是监视这些环境并配置和优化数据库服务器以满足多种需求。大数据的出现加剧了DBA的问题。
-
IBM DB2将迎来30岁“生日”
再过几天,主流数据库产品DB2就将迎来它30岁的“生日”。作为关系型数据库技术的标志性产品,DB2在过去的30年中也在伴随用户需求的变化不断地发展。
-
SQL调优之“忧”:如何进行SQL调优
DBA们应该将自己从“我要对什么调优?”的老路上解放出来,而在指标、配置和成本方面花费一定的时间。