
在MySQL中,只有一种Join算法,就是大名鼎鼎的Nested Loop Join,他没有其他很多数据库所提供的Hash Join,也没有Sort Merge Join。顾名思义,Nested Loop Join实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与 Join,则再通过前两个表的Join 结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复。
还是通过示例和图解来说明吧,后面将通过我个人数据库测试环境中的一个 example(自行设计,非MySQL 自己提供) 数据库中的三个表的 Join 查询来进行示例。
注意:由于这里有些内容需要在MySQL 5.1.18之后的版本中才会体现出来,所以本测试的MySQL 版本为5.1.26
表结构:
example 11:09:32> show create table user_groupG *************************** 1. row *************************** Table: user_group Create Table: CREATE TABLE `user_group` ( `user_id` int(11) NOT NULL, `group_id` int(11) NOT NULL, `user_type` int(11) NOT NULL, `gmt_create` datetime NOT NULL, `gmt_modified` datetime NOT NULL, `status` varchar(16) NOT NULL, KEY `idx_user_group_uid` (`user_id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 1 row in set (0.00 sec) sky@localhost : example 11:10:32> show create table group_messageG *************************** 1. row *************************** Table: group_message Create Table: CREATE TABLE `group_message` ( `id` int(11) NOT NULL AUTO_INCREMENT, `gmt_create` datetime NOT NULL, `gmt_modified` datetime NOT NULL, `group_id` int(11) NOT NULL, `user_id` int(11) NOT NULL, `author` varchar(32) NOT NULL, `subject` varchar(128) NOT NULL, PRIMARY KEY (`id`), KEY `idx_group_message_author_subject` (`author`,`subject`(16)), KEY `idx_group_message_author` (`author`), KEY `idx_group_message_gid_uid` (`group_id`,`user_id`) ) ENGINE=MyISAM AUTO_INCREMENT=97 DEFAULT CHARSET=utf8 1 row in set (0.00 sec) sky@localhost : example 11:10:43> show create table group_message_contentG *************************** 1. row *************************** Table: group_message_content Create Table: CREATE TABLE `group_message_content` ( `group_msg_id` int(11) NOT NULL, `content` text NOT NULL, KEY `group_message_content_msg_id` (`group_msg_id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 1 row in set (0.00 sec) |
| 1 select m.subject msg_subject, c.content msg_content2 3 from user_group g,group_message m,group_message_content c4 5 where g.user_id = 16 7 and m.group_id = g.group_id8 9 and c.group_msg_id = m.id |
看看我们的Query的执行计划:
sky@localhost : example 11:17:04> explain select m.subject msg_subject, c.content msg_content -> from user_group g,group_message m,group_message_content c -> where g.user_id = 1 -> and m.group_id = g.group_id -> and c.group_msg_id = m.idG *************************** 1. row *************************** id: 1 select_type: SIMPLE table: g type: ref possible_keys: user_group_gid_ind,user_group_uid_ind,user_group_gid_uid_ind key: user_group_uid_ind key_len: 4 ref: const rows: 2 Extra: *************************** 2. row *************************** id: 1 select_type: SIMPLE table: m type: ref possible_keys: PRIMARY,idx_group_message_gid_uid key: idx_group_message_gid_uid key_len: 4 ref: example.g.group_id rows: 3 Extra: *************************** 3. row *************************** id: 1 select_type: SIMPLE table: c type: ref possible_keys: idx_group_message_content_msg_id key: idx_group_message_content_msg_id key_len: 4 ref: example.m.id rows: 2 Extra: |
我们可以看出,MySQL Query Optimizer选择了user_group作为驱动表,首先利用我们传入的条件user_id通过 该表上面的索引user_group_uid_ind来进行 const 条件的索引ref查找,然后以user_group表中过滤出来的结果集的group_id 字段作为查询条件,对group_message循环查询,然后再通过 user_group 和 group_message 两个表的结果集中的group_message的id作为条件与group_message_content的 group_msg_id 比较进行循环查询,才得到最终的结果。没啥特别的,后一个引用前一个的结果集作为条件,实现过程可以通过下图表示:
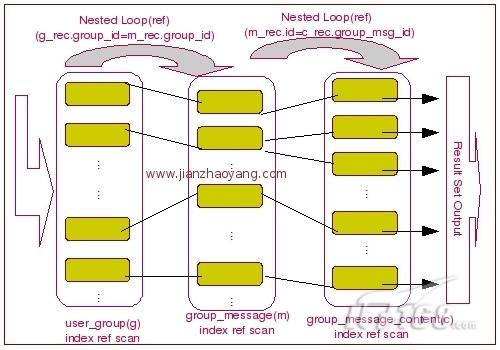
下面的我们调整一下 group_message_content 去掉上面的 idx_group_message_content_msg_id 这个索引,然后再看看会是什么效果:
sky@localhost : example 11:25:36> drop index idx_group_message_content_msg_id on group_message_content; Query OK, 96 rows affected (0.11 sec) sky@localhost : example 10:21:06> explain -> select m.subject msg_subject, c.content msg_content -> from user_group g,group_message m,group_message_content c -> where g.user_id = 1 -> and m.group_id = g.group_id -> and c.group_msg_id = m.idG *************************** 1. row *************************** id: 1 select_type: SIMPLE table: g type: ref possible_keys: idx_user_group_uid key: idx_user_group_uid key_len: 4 ref: const rows: 2 Extra: *************************** 2. row *************************** id: 1 select_type: SIMPLE table: m type: ref possible_keys: PRIMARY,idx_group_message_gid_uid key: idx_group_message_gid_uid key_len: 4 ref: example.g.group_id rows: 3 Extra: *************************** 3. row *************************** id: 1 select_type: SIMPLE table: c type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 96 Extra: Using where; Using join buffer |
我们看到不仅仅 group_message_content 表的访问从 ref 变成了 ALL,此外,在最后一行的 Extra信息从没有任何内容变成为 Using where; Using join buffer,也就是说,对于从 ref 变成 ALL 很容易理解,没有可以使用的索引的索引了嘛,当然得进行全表扫描了,Using where 也是因为变成全表扫描之后,我们需要取得的 content 字段只能通过对表中的数据进行 where 过滤才能取得,但是后面出现的 Using join buffer 是一个啥呢?
我们知道,MySQL 中有一个供我们设置的参数 join_buffer_size ,这里实际上就是使用到了通过该参数所设置的 Buffer 区域。那为啥之前的执行计划中没有用到呢?
实际上,Join Buffer 只有当我们的 Join 类型为 ALL(如示例中),index,rang 或者是 index_merge 的时候 才能够使用,所以,在我们去掉 group_message_content 表的 group_msg_id 字段的索引之前,由于 Join 是 ref 类型的,所以我们的执行计划中并没有看到有使用 Join Buffer。
当我们使用了 Join Buffer 之后,我们可以通过下面的这张图片来表示 Join 完成过程:
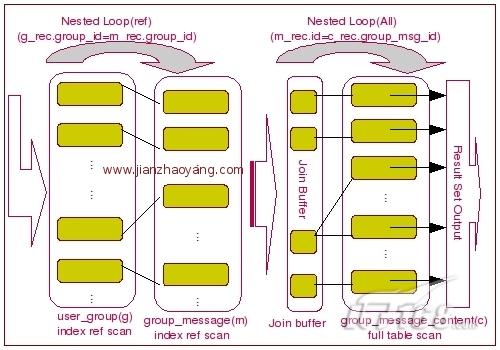
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
2017年5月数据库流行度排行榜 MySQL与Oracle“势均力敌”
数据库知识网站DB-engines.com最近更新了2017年5月的数据库流行榜单。TechTarget继续与您一起分享最新的榜单情况。
-
2017年3月数据库流行度排行榜 Oracle卫冕之路困难重重
时隔一个月,数据库市场经过一轮“洗牌”,旧的市场格局是否会被打破,曾经占巨大市场份额的企业是否可能失去优势?
-
2017年2月数据库流行度排行榜 攻城容易守城难
2016年下半年,数据库排行榜的前二十名似乎都“固守阵地”,在排名上没有太大的变动。随着2017年的悄然而至,数据库的排名情况是否会有新的看点?
-
MySQL管理特性:让企业适合交易平台
当Alexander Culiniac和他的同事在TickTrade系统公司建立一个基于云的交易平台时,面临一些基本的约束。那就是,系统必须在云上工作良好并且经济实用。