
SSAS为我们提供了九种数据挖掘算法,但是在应用中我们需要根据实际问题设计适当的算法,这个时候就需要扩展SSAS,使它能应用更多的算法。SSAS有比较好的可扩展性,它提供了一个完整的机制来进行扩展,只要继承一些类并按适当的方法进行注册就可以在SSAS中使用自己的算法了。
下面我将通过实例分别用几篇文章来介绍一下如何开发SSAS算法插件。本文介绍的算法插件开发方法是基于托管代码的,是用C#开发的(算法插件也可以用C++开发,并且SQLSERVER2005的案例中附带C++版本的代码stub)。整个过程大至为六个步骤。在开始开发之前需要做一些准备工作,就是要去下载 一个用C++编写的COM组件,叫DMPluginWrapper(可以通过下载本文附带的附件获得),它作为SSAS与算法插件的中间层,用于处理 SSAS与算法插件之间的交互以及封装从SSAS到算法插件的参数和从算法插件到SSAS的处理结果。DMPluginWrapper、SSAS和算法插 件之间的关系可以由下图来描述。
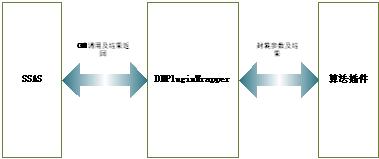
图表1: DMPluginWrapper、SSAS和算法插件之间的关系
下面开始创建算法扩展的项目。
首先新建一个类库项目(名为AlgorithmPlugin)将刚才的DMPluginWrapper项目引用到新建的这个 AlgorithmPlugin类库项目中。你可以选择为这个类库项目进行程序集签名,这样就可以将其注册到GAC中。另外还要为 DMPluginWrapper添加后生成脚本将程序集注册到GAC,参考脚本如下(根据机器具体设置而定):
|
C:Program FilesMicrosoft Visual Studio 8SDKv2.0Bingacutil.exe” /u $(TargetName) “ C:Program FilesMicrosoft Visual Studio 8SDKv2.0Bingacutil.exe” /if $(TargetPath) |
如果第一行脚本不能正确运行的话,算法插件是不能被SQLSERVER分析服务器识别的。另外两行脚本就是将算法程序集注册到GAC。
接下来的几个步骤主要是继承一些基类的工作,包括AlgorithmMetadataBase类、AlgorithmBase类和 ICaseProcessor接口和AlgorithmNavigationBase类。首先在AlgorithmPlugin中新建一个类文件并命名为 Metadata,为这个类添加ComVisible、MiningAlgorithmClass(typeof(Algorithm))和Guid属性 (Algorithm是下面要创建的算法类),并为Guid属性指定一个GUID编码。这个类要继承于AlgorithmMetadataBase类。现 在要做的事情就是覆盖基类的方法。下面是所有需要覆盖的方法(对于较简单的实现写在表格中):
方法名实现(参考)备注
GetServiceNamereturn “MyFirstAlgorithmPlugin”这个方法的返回值中不能带有空格字符GetServiceDescriptionreturn “Sample Algorithm Plugin”;GetServiceTypePlugInServiceType.ServiceTypeOther;GetViewerTypereturn string.EmptyGetScalingreturn MiningScaling.Medium; |
用于指定算法适用的规模,这个值不会被服务器使用而是显示在模式行集中,为用户提供算法的一些相关信息。
GetTrainingComplexity
return MiningTrainingComplexity.Low
用于指定算法训练适用的复杂度,这个值不会被服务器使用而是显示在模式行集中,为用户提供算法的一些相关信息。
GetPredictionComplexity
return MiningPredictionComplexity.Low
用于指定预测复杂度,这个值不会被服务器使用而是显示在模式行集中,为用户提供算法的一些相关信息。
GetSupportsDMDimensionsretrun false;GetSupportsDrillThroughreturn false;指定这个算法是否支持钻透功能。GetDrillThroughMustIncludeChildrenreturn false;GetCaseIdModeledreturn false;GetMarginalRequirementsreturn MarginalRequirements.AllStatsGetParametersCollectionreturn null;算法参数,因为本文中的例子没有参数,所以这里返回空。GetSupInputContentTypesMiningColumnContent[] arInputContentTypes = new MiningColumnContent[] { MiningColumnContent.Discrete, MiningColumnContent.Continuous, MiningColumnContent.Discretized, MiningColumnContent.NestedTable, MiningColumnContent.Key }; return arInputContentTypes;指定算法所支持的输入属性的数据类型,如连续型、离散型等。GetSupPredictContentTypesMiningColumnContent[] arPredictContentTypes = new MiningColumnContent[] { MiningColumnContent.Discrete, MiningColumnContent.Continuous, MiningColumnContent.Discretized, MiningColumnContent.NestedTable, MiningColumnContent.Key }; return arPredictContentTypes;与上一个方法类似,这里是指定预测属性所支持的数据类型。GetSupportedStandardFunctionsSupportedFunction[] arFuncs = new SupportedFunction[] { SupportedFunction.PredictSupport, SupportedFunction.PredictHistogram, SupportedFunction.PredictProbability, SupportedFunction.PredictAdjustedProbability, SupportedFunction.PredictAssociation, SupportedFunction.PredictStdDev, SupportedFunction.PredictVariance, SupportedFunction.RangeMax, SupportedFunction.RangeMid, SupportedFunction.RangeMin, SupportedFunction.DAdjustedProbability, SupportedFunction.DProbability, SupportedFunction.DStdDev, SupportedFunction.DSupport, SupportedFunction.DVariance, // content-related functions SupportedFunction.IsDescendent, SupportedFunction.PredictNodeId, SupportedFunction.IsInNode, SupportedFunction.DNodeId, }; return arFuncs;指定DMX所支持的函数。CreateAlgorithmreturn new Algorithm();返回算法实例,Algorithm是接下来要创建的类。 |
现在创建第二个类,命名为Algorithm.cs。这个类要继承于AlgorithmBase并实现ICaseProcesses接口,这是实现算法最重要的一个类,主要的算法处理都在这个类中进行。这个类要有一个成员变量TaskProgressNotification trainingProgress。这个类包含了算法主要的处理逻辑。下面是要实现的方法:
方法名: //处理样本 InsertCases 参考实现: Code//遍历所有的样本并且每处理100个样本更新一次处理进度。 trainingProgress = this.Model.CreateTaskNotification(); // 设置当前的处理进度为0 trainingProgress.Current = 0; // 取得总的样本数量。 trainingProgress.Total = (int)this.MarginalStats.GetTotalCasesCount(); // 为跟踪提示信息设置格式字符串 trainingProgress.Format = “Processing cases: {0} out of {1}”; // 开始处理 trainingProgress.Start(); bool success = false; try { caseSet.StartCases(this); success = true; } finally { trainingProgress.End(success); } 方法名:ProcessCase 参考实现: Code// 检查并确认处理过程没有被中断。this.Context.CheckCancelled(); // 更新当前的进度值 trainingProgress.Current++; if (caseId % 100 == 0) { trainingProgress.Progress(); } //TODO: 在这里进行实际的模型训练处理逻辑 方法名:SaveContent 参考实现: Code//创建一个自定义的标签内容用于保存处理结果(其结构类似XML),MyPersistenceTag是自定义的枚举类型 writer.OpenScope((PersistItemTag)MyPersistenceTag.ShellAlgorithmContent); writer.SetValue(System.DateTime.Now); writer.SetAttribute((PersistItemTag)MyPersistenceTag.NumberOfCases, this.MarginalStats.GetTotalCasesCount()); writer.CloseScope(); 方法名:LoadContent 参考实现: Code//打开自定义的标签(与SaveContent方法相对应)reader.OpenScope((PersistItemTag)MyPersistenceTag.ShellAlgorithmContent); //读取处理时间 System.DateTime processingTime; reader.GetValue(out processingTime); // 取得处理的样本数量 uint numberCases = 0; reader.GetAttribute((PersistItemTag)MyPersistenceTag.NumberOfCases, out numberCases); reader.CloseScope(); 方法名:Predict 参考实现: CodeAttributeGroup targetAttributes = predictionResult.OutputAttributes; targetAttributes.Reset(); uint nAtt = AttributeSet.Unspecified; //对于每一个目标属性,从训练集中复制预测结果 while (targetAttributes.Next(out nAtt)) { //创建一个AttributeStatistics对象用于保存对当前目标属性的预测结果 AttributeStatistics result = new AttributeStatistics(); //设置预测结果中的目标属性,即当前的预测结果针对于哪个输入属性 result.Attribute = nAtt; // 取得当前属性的概率统计值,也即通过模型训练得到的边缘统计概率。 AttributeStatistics trainingStats = this.MarginalStats.GetAttributeStats(nAtt); //复制其余的数据到结果对象 result.AdjustedProbability = trainingStats.AdjustedProbability; result.Max = trainingStats.Max; result.Min = trainingStats.Min; result.Probability = trainingStats.Probability; result.Support = trainingStats.Support; //复制状态统计到结果对象中 if (predictionResult.IncludeStatistics) { for ( int nIndex = 0; nIndex < trainingStats.StateStatistics.Count; nIndex++) { bool bAddThisState = true; // 如果是丢失值状态,那么只有当需要的时候才将其包含在结果之中。 if (trainingStats.StateStatistics[0].Value.IsMissing) {bAddThisState = predictionResult.IncludeMissingState; } if (bAddThisState) { result.StateStatistics.Add( trainingStats.StateStatistics[(uint)nIndex]); } } } //如果预测需要内容结点,就要为内容结点设置一个唯一的编号if (predictionResult.IncludeNodeId) { result.NodeId = “000”; }predictionResult.AddPrediction(result); 方法名:GetNavigator 参考实现: Code//AlgorithmNavigator是下面要创建的类 return new AlgorithmNavigator(this, forDMDimensionContent); |
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
SQL Server 2005支持服务结束 升级何去何从
SQL Server 2005的支持就要结束了,就在2016年4月12日,SQL Server 2005的客户们应该升级了。
-
SQL Server 2005即将终止服务 你准备好了么?
2016年4月12日,微软将正式终止SQL Server 2005相关服务。微软正在终止扩展支持,这意味着不再有新特性更新,什么都没了。
-
解决SQL服务器提示属性IsLocked不可用于登录用户的错误
在SQL Server中,权限的分配很重要。特别是在用户数量众多的数据库里面,用户权限,架构的划分经常会导致权限之间的冲突,导致无法登陆。
-
TT数据库特别推荐:SQL Server编年史
无论是菜鸟还是资深DBA,除了要掌握基本的数据库管理、操作之外,还需要对不同产品的发展历史有一个了解。