
在sql server 2008中提供了9种常用的数据挖掘算法,这些算法用在不同数据挖掘的应用场景下,下面我们就各个算法逐个分析讨论。
1.决策树算法
决策树,又称判定树,是一种类似二叉树或多叉树的树结构。决策树是用样本的属性作为结点,用属性的取值作为分支,也就是类似流程图的过程,其中每个内部节点表示在一个属性上的测试,每个分支代表一个测试输出,而每个树叶节点代表类或类分布。它对大量样本的属性进行分析和归纳。根结点是所有样本中信息量最大的属性,中间结点是以该结点为根的子树所包含的样本子集中信息量最大的属性,决策树的叶结点是样本的类别值。
从树的根结点出发,将测试条件用于检验记录,根据测试结果选择适当的分支,沿着该分支或者达到另一个内部结点,使用新的测试条件或者达到一个叶结点,叶结点的类称号就被赋值给该检验记录。决策树的每个分支要么是一个新的决策节点,要么是树的结尾,称为叶子。在沿着决策树从上到下遍历的过程中,在每个节点都会遇到一个问题,对每个节点上问题的不同回答导致不同的分支,最后会到达一个叶子节点。这个过程就是利用决策树进行分类的过程。决策树算法能从一个或多个的预测变量中,针对类别因变量,预测出个例的趋势变化关系。
在sql server 2008中,我们可以通过挖掘模型查看器来查看决策树模型。如图1所示。
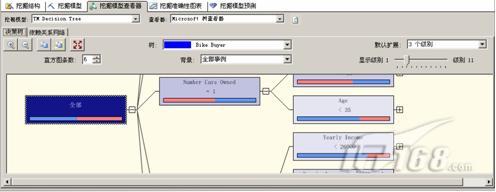
图1
在图1中,我们可以看到决策树显示由一系列拆分组成,最重要的拆分由算法确定,位于“全部”节点中查看器的左侧。其他拆分出现在右侧。依赖关系网络显示了模型中的输入属性和可预测属性之间的依赖关系。并能通过滑块来筛选依赖关系强度。
2.聚类分析算法
聚类分析算法就是衡量个体间的相似度,是依据个体的数据点在几何空间的距离来判断的,距离越近,就越相似,就越容易归为一类。在最初定义分类后,算法将通过计算确定分类表示点分组情况的适合程度,然后尝试重新定义这些分组以创建可以更好地表示数据的分类。该算法将循环执行此过程,直到它不能再通过重新定义分类来改进结果为止。简单得说,聚类就是将数据对象的集合分组成为由类似的对象组成的多个类的过程。聚类用在商务方面的客户分析中,可以从客户库中发现不同的客户群,并分析不同客户群的行为模式。
在sql server 2008中,我们可以通过挖掘模型查看器来查看聚类分析模型。如图2所示。
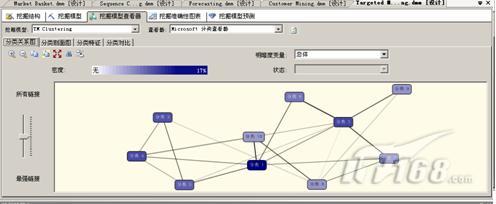
图2
在图2中,分类关系图表现个类间关联性的强弱。分类剖面图了解因变量与自变量的关联性强弱程度。分类特征主要呈现每一类的特性。分类对比主要呈现出两类间特性的比较。
3.Naive Bayes 算法
Naive Bayes 算法是 Microsoft SQL Server Analysis Services 提供的一种分类算法,用于预测性建模。Naive Bayes算法使用贝叶斯定理,假定一个属性值对给定类的影响独立于其他属性的值。与其他算法相比,该算法所需的运算量小,因而能够快速生成挖掘模型,以发现输入列和可预测列之间的关系。可以使用该算法进行初始数据探测,在用于大型数据库时,该算法也表现出了高准确率与高速度,能与决策树和神经网络相媲美。
算法采用监督式的学习方式,在分类之前,需要事先知道分类的类型。通过对训练样本的学习,来有效得进行分类。就是通过训练样本中的属性关系,产生训练样本的中心概念,用这些已经产生的中心概念,对未分类的数据对象进行预测。
在sql server 2008中,我们可以通过挖掘模型查看器来查看Naive Bayes模型。如图3所示。
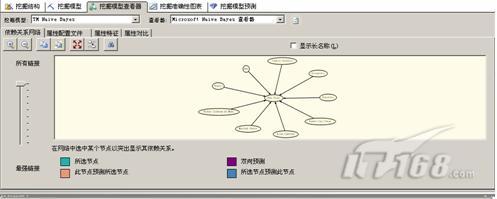
图3
在图3中,依赖关系网络可以对数据的分布进一步了解。属性配置文件可以了解每个变量的特性分布情况。属性特征可以看出不同群分类的基本特性概率。属性对比就是呈现属性之间的特性对比。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
SQL Server 2008将退出微软主流数据库支持
你的企业是否还在运行SQL Server 2008?请注意微软为SQL Server 2008提供的主流技术支持服务将于今年的7月8日正式结束。
-
使用Apache Hadoop挖掘现有数据
本文介绍了如何使用Apache Hadoop挖掘您的数据,并将数据转换为可以轻松供给一个基于 web 的报表应用程序的数据。
-
当业务分析师遭遇预测分析软件
在刚刚发布的胜利指数报告中,Hurwitz & Associates公司对业界12家预测分析厂商进行了评定,从市场占有率和客户两方面,Hurwitz将IBM SPSS和SAS评为“胜利者”。
-
数据科学家如何解决预测分析的难题
TechTarget网站最近就关于数据科学家及将来他们如何使用预言分析探寻结果的问题采访了Metamarkets的首席技术官和Michael Drisoll。